 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Generative Multi-Task Representation Learning Approach for Predicting Postoperative Complications in Cardiac Surgery Patients
Dec 02, 2024


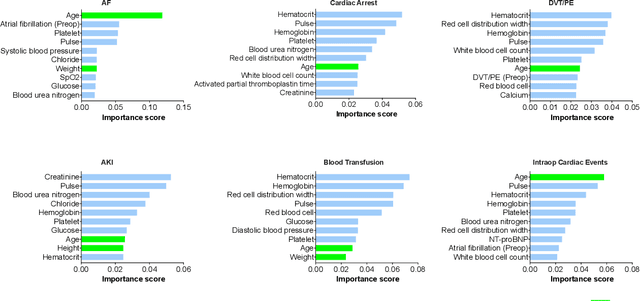
Early detection of surgical complications allows for timely therapy and proactive risk mitigation. Machine learning (ML) can be leveraged to identify and predict patient risks for postoperative complications. We developed and validated the effectiveness of predicting postoperative complications using a novel surgical Variational Autoencoder (surgVAE) that uncovers intrinsic patterns via cross-task and cross-cohort presentation learning. This retrospective cohort study used data from the electronic health records of adult surgical patients over four years (2018 - 2021). Six key postoperative complications for cardiac surgery were assessed: acute kidney injury, atrial fibrillation, cardiac arrest, deep vein thrombosis or pulmonary embolism, blood transfusion, and other intraoperative cardiac events. We compared prediction performances of surgVAE against widely-used ML models and advanced representation learning and generative models under 5-fold cross-validation. 89,246 surgeries (49% male, median (IQR) age: 57 (45-69)) were included, with 6,502 in the targeted cardiac surgery cohort (61% male, median (IQR) age: 60 (53-70)). surgVAE demonstrated superior performance over existing ML solutions across all postoperative complications of cardiac surgery patients, achieving macro-averaged AUPRC of 0.409 and macro-averaged AUROC of 0.831, which were 3.4% and 3.7% higher, respectively, than the best alternative method (by AUPRC scores). Model interpretation using Integrated Gradients highlighted key risk factors based on preoperative variable importance. surgVAE showed excellent discriminatory performance for predicting postoperative complications and addressing the challenges of data complexity, small cohort sizes, and low-frequency positive events. surgVAE enables data-driven predictions of patient risks and prognosis while enhancing the interpretability of patient risk profiles.
Optimizing Edge Offloading Decisions for Object Detection
Oct 24, 2024



Recent advances in machine learning and hardware have produced embedded devices capable of performing real-time object detection with commendable accuracy. We consider a scenario in which embedded devices rely on an onboard object detector, but have the option to offload detection to a more powerful edge server when local accuracy is deemed too low. Resource constraints, however, limit the number of images that can be offloaded to the edge. Our goal is to identify which images to offload to maximize overall detection accuracy under those constraints. To that end, the paper introduces a reward metric designed to quantify potential accuracy improvements from offloading individual images, and proposes an efficient approach to make offloading decisions by estimating this reward based only on local detection results. The approach is computationally frugal enough to run on embedded devices, and empirical findings indicate that it outperforms existing alternatives in improving detection accuracy even when the fraction of offloaded images is small.
SoK: Security and Privacy Risks of Medical AI
Sep 11, 2024



The integration of technology and healthcare has ushered in a new era where software systems, powered by artificial intelligence and machine learning, have become essential components of medical products and services. While these advancements hold great promise for enhancing patient care and healthcare delivery efficiency, they also expose sensitive medical data and system integrity to potential cyberattacks. This paper explores the security and privacy threats posed by AI/ML applications in healthcare. Through a thorough examination of existing research across a range of medical domains, we have identified significant gaps in understanding the adversarial attacks targeting medical AI systems. By outlining specific adversarial threat models for medical settings and identifying vulnerable application domains, we lay the groundwork for future research that investigates the security and resilience of AI-driven medical systems. Through our analysis of different threat models and feasibility studies on adversarial attacks in different medical domains, we provide compelling insights into the pressing need for cybersecurity research in the rapidly evolving field of AI healthcare technology.
Real-Time Human Action Recognition on Embedded Platforms
Sep 11, 2024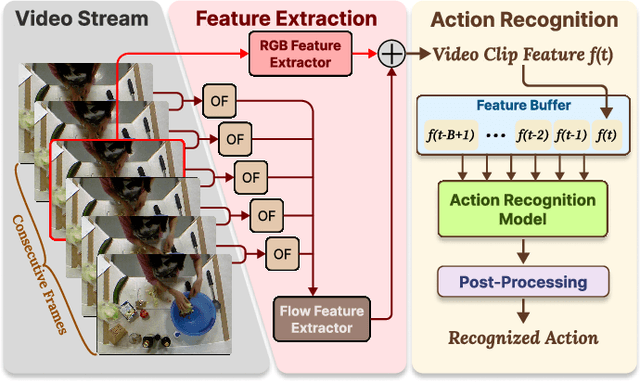
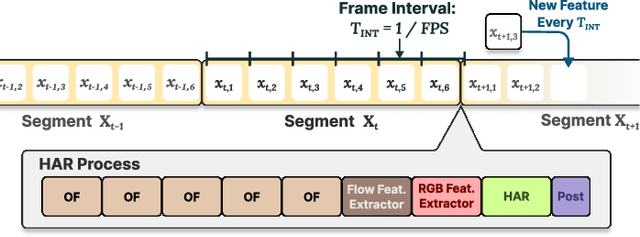
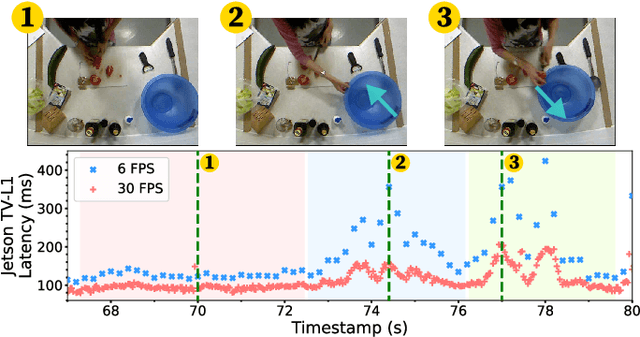
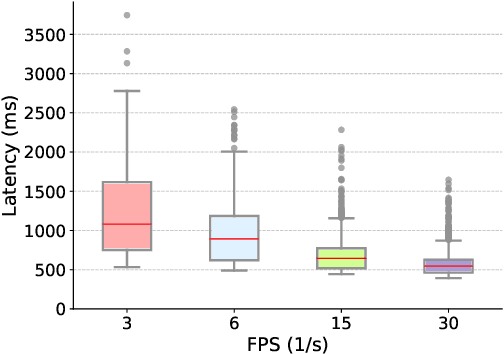
With advancements in computer vision and deep learning, video-based human action recognition (HAR) has become practical. However, due to the complexity of the computation pipeline, running HAR on live video streams incurs excessive delays on embedded platforms. This work tackles the real-time performance challenges of HAR with four contributions: 1) an experimental study identifying a standard Optical Flow (OF) extraction technique as the latency bottleneck in a state-of-the-art HAR pipeline, 2) an exploration of the latency-accuracy tradeoff between the standard and deep learning approaches to OF extraction, which highlights the need for a novel, efficient motion feature extractor, 3) the design of Integrated Motion Feature Extractor (IMFE), a novel single-shot neural network architecture for motion feature extraction with drastic improvement in latency, 4) the development of RT-HARE, a real-time HAR system tailored for embedded platforms. Experimental results on an Nvidia Jetson Xavier NX platform demonstrated that RT-HARE realizes real-time HAR at a video frame rate of 30 frames per second while delivering high levels of recognition accuracy.
DAFFNet: A Dual Attention Feature Fusion Network for Classification of White Blood Cells
May 25, 2024



The precise categorization of white blood cell (WBC) is crucial for diagnosing blood-related disorders. However, manual analysis in clinical settings is time-consuming, labor-intensive, and prone to errors. Numerous studies have employed machine learning and deep learning techniques to achieve objective WBC classification, yet these studies have not fully utilized the information of WBC images. Therefore, our motivation is to comprehensively utilize the morphological information and high-level semantic information of WBC images to achieve accurate classification of WBC. In this study, we propose a novel dual-branch network Dual Attention Feature Fusion Network (DAFFNet), which for the first time integrates the high-level semantic features with morphological features of WBC to achieve accurate classification. Specifically, we introduce a dual attention mechanism, which enables the model to utilize the channel features and spatially localized features of the image more comprehensively. Morphological Feature Extractor (MFE), comprising Morphological Attributes Predictor (MAP) and Morphological Attributes Encoder (MAE), is proposed to extract the morphological features of WBC. We also implement Deep-supervised Learning (DSL) and Semi-supervised Learning (SSL) training strategies for MAE to enhance its performance. Our proposed network framework achieves 98.77%, 91.30%, 98.36%, 99.71%, 98.45%, and 98.85% overall accuracy on the six public datasets PBC, LISC, Raabin-WBC, BCCD, LDWBC, and Labelled, respectively, demonstrating superior effectiveness compared to existing studies. The results indicate that the WBC classification combining high-level semantic features and low-level morphological features is of great significance, which lays the foundation for objective and accurate classification of WBC in microscopic blood cell images.
Prescribing Large Language Models for Perioperative Care: What's The Right Dose for Pre-trained Models?
Feb 28, 2024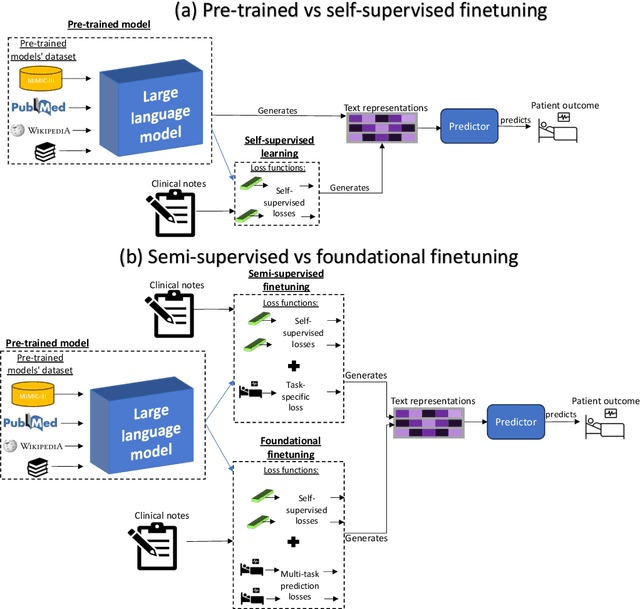



Postoperative risk predictions can inform effective perioperative care management and planning. We aimed to assess whether clinical large language models (LLMs) can predict postoperative risks using clinical texts with various training strategies. The main cohort involved 84,875 records from Barnes Jewish Hospital (BJH) system between 2018 and 2021. Methods were replicated on Beth Israel Deaconess's MIMIC dataset. Both studies had mean duration of follow-up based on the length of postoperative ICU stay less than 7 days. For the BJH dataset, outcomes included 30-day mortality, pulmonary embolism (PE) and pneumonia. Three domain adaptation and finetuning strategies were implemented for BioGPT, ClinicalBERT and BioClinicalBERT: self-supervised objectives; incorporating labels with semi-supervised fine-tuning; and foundational modelling through multi-task learning. Model performance was compared using the area under the receiver operating characteristic curve (AUROC) and the area under the precision recall curve (AUPRC) for classification tasks, and mean squared error (MSE) and R2 for regression tasks. Pre-trained LLMs outperformed traditional word embeddings, with absolute maximal gains of 38.3% for AUROC and 14% for AUPRC. Adapting models further improved performance: (1) self-supervised finetuning by 3.2% for AUROC and 1.5% for AUPRC; (2) semi-supervised finetuning by 1.8% for AUROC and 2% for AUPRC, compared to self-supervised finetuning; (3) foundational modelling by 3.6% for AUROC and 2.6% for AUPRC, compared to self-supervised finetuning. Pre-trained clinical LLMs offer opportunities for postoperative risk predictions in unforeseen data, with peaks in foundational models indicating the potential of task-agnostic learning towards the generalizability of LLMs in perioperative care.
Progressive Neural Compression for Adaptive Image Offloading under Timing Constraints
Oct 08, 2023
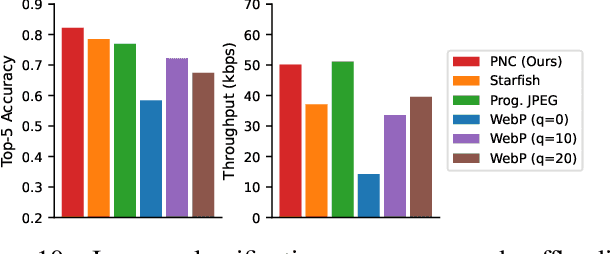


IoT devices are increasingly the source of data for machine learning (ML) applications running on edge servers. Data transmissions from devices to servers are often over local wireless networks whose bandwidth is not just limited but, more importantly, variable. Furthermore, in cyber-physical systems interacting with the physical environment, image offloading is also commonly subject to timing constraints. It is, therefore, important to develop an adaptive approach that maximizes the inference performance of ML applications under timing constraints and the resource constraints of IoT devices. In this paper, we use image classification as our target application and propose progressive neural compression (PNC) as an efficient solution to this problem. Although neural compression has been used to compress images for different ML applications, existing solutions often produce fixed-size outputs that are unsuitable for timing-constrained offloading over variable bandwidth. To address this limitation, we train a multi-objective rateless autoencoder that optimizes for multiple compression rates via stochastic taildrop to create a compression solution that produces features ordered according to their importance to inference performance. Features are then transmitted in that order based on available bandwidth, with classification ultimately performed using the (sub)set of features received by the deadline. We demonstrate the benefits of PNC over state-of-the-art neural compression approaches and traditional compression methods on a testbed comprising an IoT device and an edge server connected over a wireless network with varying bandwidth.
Utilizing Semantic Textual Similarity for Clinical Survey Data Feature Selection
Aug 19, 2023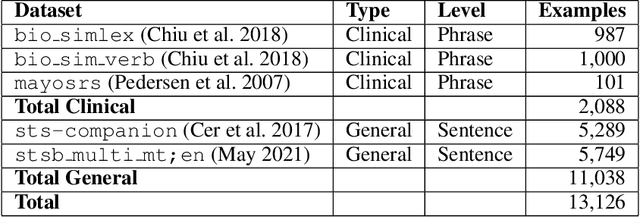
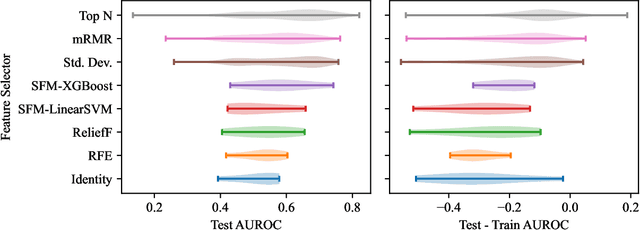
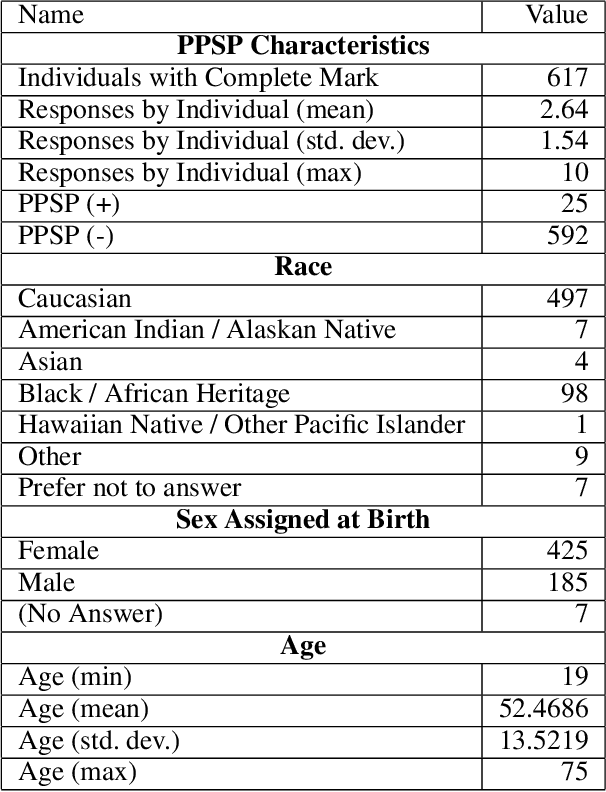
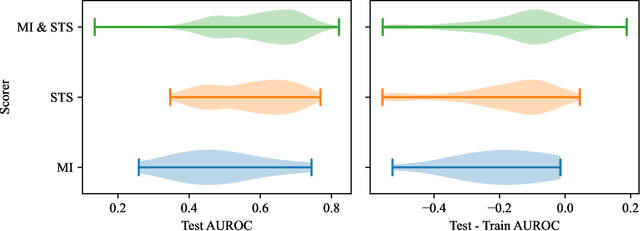
Survey data can contain a high number of features while having a comparatively low quantity of examples. Machine learning models that attempt to predict outcomes from survey data under these conditions can overfit and result in poor generalizability. One remedy to this issue is feature selection, which attempts to select an optimal subset of features to learn upon. A relatively unexplored source of information in the feature selection process is the usage of textual names of features, which may be semantically indicative of which features are relevant to a target outcome. The relationships between feature names and target names can be evaluated using language models (LMs) to produce semantic textual similarity (STS) scores, which can then be used to select features. We examine the performance using STS to select features directly and in the minimal-redundancy-maximal-relevance (mRMR) algorithm. The performance of STS as a feature selection metric is evaluated against preliminary survey data collected as a part of a clinical study on persistent post-surgical pain (PPSP). The results suggest that features selected with STS can result in higher performance models compared to traditional feature selection algorithms.
Assisting Clinical Decisions for Scarcely Available Treatment via Disentangled Latent Representation
Jul 06, 2023



Extracorporeal membrane oxygenation (ECMO) is an essential life-supporting modality for COVID-19 patients who are refractory to conventional therapies. However, the proper treatment decision has been the subject of significant debate and it remains controversial about who benefits from this scarcely available and technically complex treatment option. To support clinical decisions, it is a critical need to predict the treatment need and the potential treatment and no-treatment responses. Targeting this clinical challenge, we propose Treatment Variational AutoEncoder (TVAE), a novel approach for individualized treatment analysis. TVAE is specifically designed to address the modeling challenges like ECMO with strong treatment selection bias and scarce treatment cases. TVAE conceptualizes the treatment decision as a multi-scale problem. We model a patient's potential treatment assignment and the factual and counterfactual outcomes as part of their intrinsic characteristics that can be represented by a deep latent variable model. The factual and counterfactual prediction errors are alleviated via a reconstruction regularization scheme together with semi-supervision, and the selection bias and the scarcity of treatment cases are mitigated by the disentangled and distribution-matched latent space and the label-balancing generative strategy. We evaluate TVAE on two real-world COVID-19 datasets: an international dataset collected from 1651 hospitals across 63 countries, and a institutional dataset collected from 15 hospitals. The results show that TVAE outperforms state-of-the-art treatment effect models in predicting both the propensity scores and factual outcomes on heterogeneous COVID-19 datasets. Additional experiments also show TVAE outperforms the best existing models in individual treatment effect estimation on the synthesized IHDP benchmark dataset.
Content-aware Token Sharing for Efficient Semantic Segmentation with Vision Transformers
Jun 03, 2023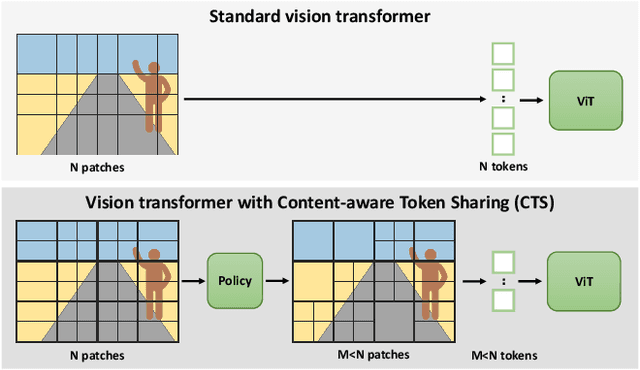
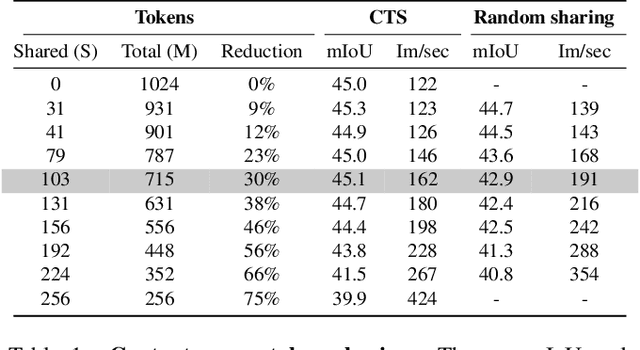
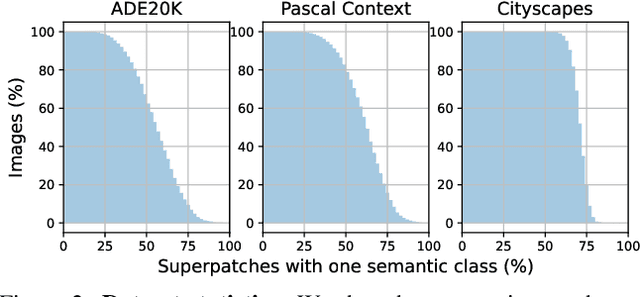
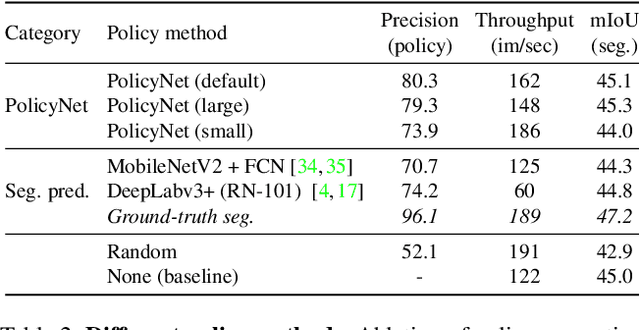
This paper introduces Content-aware Token Sharing (CTS), a token reduction approach that improves the computational efficiency of semantic segmentation networks that use Vision Transformers (ViTs). Existing works have proposed token reduction approaches to improve the efficiency of ViT-based image classification networks, but these methods are not directly applicable to semantic segmentation, which we address in this work. We observe that, for semantic segmentation, multiple image patches can share a token if they contain the same semantic class, as they contain redundant information. Our approach leverages this by employing an efficient, class-agnostic policy network that predicts if image patches contain the same semantic class, and lets them share a token if they do. With experiments, we explore the critical design choices of CTS and show its effectiveness on the ADE20K, Pascal Context and Cityscapes datasets, various ViT backbones, and different segmentation decoders. With Content-aware Token Sharing, we are able to reduce the number of processed tokens by up to 44%, without diminishing the segmentation quality.