 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Granular Framework for Construction Material Price Forecasting: Econometric and Machine-Learning Approaches
Dec 10, 2025The persistent volatility of construction material prices poses significant risks to cost estimation, budgeting, and project delivery, underscoring the urgent need for granular and scalable forecasting methods. This study develops a forecasting framework that leverages the Construction Specifications Institute (CSI) MasterFormat as the target data structure, enabling predictions at the six-digit section level and supporting detailed cost projections across a wide spectrum of building materials. To enhance predictive accuracy, the framework integrates explanatory variables such as raw material prices, commodity indexes, and macroeconomic indicators. Four time-series models, Long Short-Term Memory (LSTM), Autoregressive Integrated Moving Average (ARIMA), Vector Error Correction Model (VECM), and Chronos-Bolt, were evaluated under both baseline configurations (using CSI data only) and extended versions with explanatory variables. Results demonstrate that incorporating explanatory variables significantly improves predictive performance across all models. Among the tested approaches, the LSTM model consistently achieved the highest accuracy, with RMSE values as low as 1.390 and MAPE values of 0.957, representing improvements of up to 59\% over the traditional statistical time-series model, ARIMA. Validation across multiple CSI divisions confirmed the framework's scalability, while Division 06 (Wood, Plastics, and Composites) is presented in detail as a demonstration case. This research offers a robust methodology that enables owners and contractors to improve budgeting practices and achieve more reliable cost estimation at the Definitive level.
Unlocking Attributes' Contribution to Successful Camouflage: A Combined Textual and VisualAnalysis Strategy
Aug 22, 2024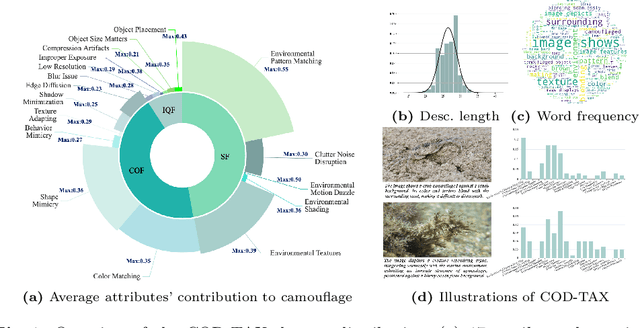
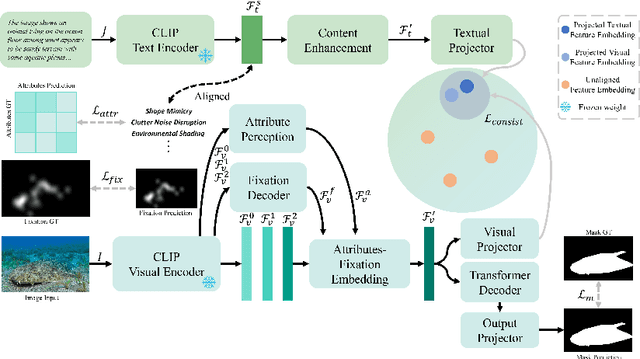
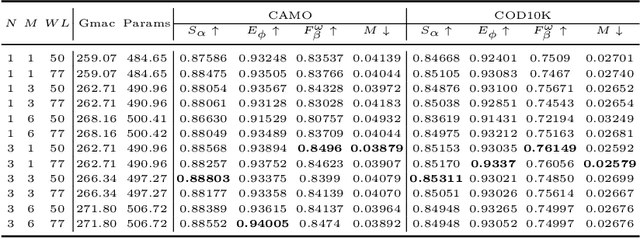
In the domain of Camouflaged Object Segmentation (COS), despite continuous improvements in segmentation performance, the underlying mechanisms of effective camouflage remain poorly understood, akin to a black box. To address this gap, we present the first comprehensive study to examine the impact of camouflage attributes on the effectiveness of camouflage patterns, offering a quantitative framework for the evaluation of camouflage designs. To support this analysis, we have compiled the first dataset comprising descriptions of camouflaged objects and their attribute contributions, termed COD-Text And X-attributions (COD-TAX). Moreover, drawing inspiration from the hierarchical process by which humans process information: from high-level textual descriptions of overarching scenarios, through mid-level summaries of local areas, to low-level pixel data for detailed analysis. We have developed a robust framework that combines textual and visual information for the task of COS, named Attribution CUe Modeling with Eye-fixation Network (ACUMEN). ACUMEN demonstrates superior performance, outperforming nine leading methods across three widely-used datasets. We conclude by highlighting key insights derived from the attributes identified in our study. Code: https://github.com/lyu-yx/ACUMEN.
Progressive Neural Compression for Adaptive Image Offloading under Timing Constraints
Oct 08, 2023
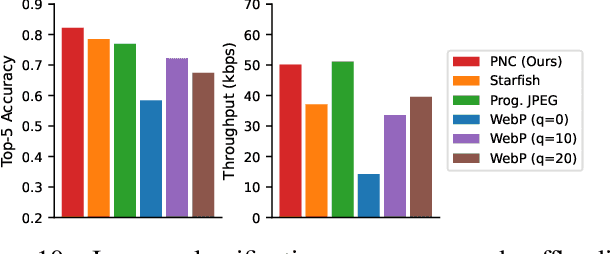


IoT devices are increasingly the source of data for machine learning (ML) applications running on edge servers. Data transmissions from devices to servers are often over local wireless networks whose bandwidth is not just limited but, more importantly, variable. Furthermore, in cyber-physical systems interacting with the physical environment, image offloading is also commonly subject to timing constraints. It is, therefore, important to develop an adaptive approach that maximizes the inference performance of ML applications under timing constraints and the resource constraints of IoT devices. In this paper, we use image classification as our target application and propose progressive neural compression (PNC) as an efficient solution to this problem. Although neural compression has been used to compress images for different ML applications, existing solutions often produce fixed-size outputs that are unsuitable for timing-constrained offloading over variable bandwidth. To address this limitation, we train a multi-objective rateless autoencoder that optimizes for multiple compression rates via stochastic taildrop to create a compression solution that produces features ordered according to their importance to inference performance. Features are then transmitted in that order based on available bandwidth, with classification ultimately performed using the (sub)set of features received by the deadline. We demonstrate the benefits of PNC over state-of-the-art neural compression approaches and traditional compression methods on a testbed comprising an IoT device and an edge server connected over a wireless network with varying bandwidth.
Assisting Clinical Decisions for Scarcely Available Treatment via Disentangled Latent Representation
Jul 06, 2023



Extracorporeal membrane oxygenation (ECMO) is an essential life-supporting modality for COVID-19 patients who are refractory to conventional therapies. However, the proper treatment decision has been the subject of significant debate and it remains controversial about who benefits from this scarcely available and technically complex treatment option. To support clinical decisions, it is a critical need to predict the treatment need and the potential treatment and no-treatment responses. Targeting this clinical challenge, we propose Treatment Variational AutoEncoder (TVAE), a novel approach for individualized treatment analysis. TVAE is specifically designed to address the modeling challenges like ECMO with strong treatment selection bias and scarce treatment cases. TVAE conceptualizes the treatment decision as a multi-scale problem. We model a patient's potential treatment assignment and the factual and counterfactual outcomes as part of their intrinsic characteristics that can be represented by a deep latent variable model. The factual and counterfactual prediction errors are alleviated via a reconstruction regularization scheme together with semi-supervision, and the selection bias and the scarcity of treatment cases are mitigated by the disentangled and distribution-matched latent space and the label-balancing generative strategy. We evaluate TVAE on two real-world COVID-19 datasets: an international dataset collected from 1651 hospitals across 63 countries, and a institutional dataset collected from 15 hospitals. The results show that TVAE outperforms state-of-the-art treatment effect models in predicting both the propensity scores and factual outcomes on heterogeneous COVID-19 datasets. Additional experiments also show TVAE outperforms the best existing models in individual treatment effect estimation on the synthesized IHDP benchmark dataset.
Learning to Rank Normalized Entropy Curves with Differentiable Window Transformation
Jan 25, 2023



Recent automated machine learning systems often use learning curves ranking models to inform decisions about when to stop unpromising trials and identify better model configurations. In this paper, we present a novel learning curve ranking model specifically tailored for ranking normalized entropy (NE) learning curves, which are commonly used in online advertising and recommendation systems. Our proposed model, self-Adaptive Curve Transformation augmented Relative curve Ranking (ACTR2), features an adaptive curve transformation layer that transforms raw lifetime NE curves into composite window NE curves with the window sizes adaptively optimized based on both the position on the learning curve and the curve's dynamics. We also introduce a novel differentiable indexing method for the proposed adaptive curve transformation, which allows gradients with respect to the discrete indices to flow freely through the curve transformation layer, enabling the learned window sizes to be updated flexibly during training. Additionally, we propose a pairwise curve ranking architecture that directly models the difference between the two learning curves and is better at capturing subtle changes in relative performance that may not be evident when modeling each curve individually as the existing approaches did. Our extensive experiments on a real-world NE curve dataset demonstrate the effectiveness of each key component of ACTR2 and its improved performance over the state-of-the-art.
HiPAL: A Deep Framework for Physician Burnout Prediction Using Activity Logs in Electronic Health Records
May 24, 2022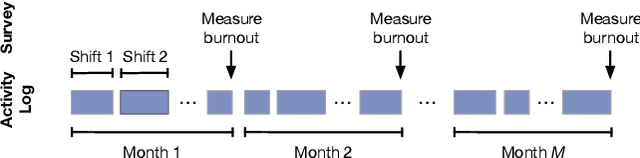
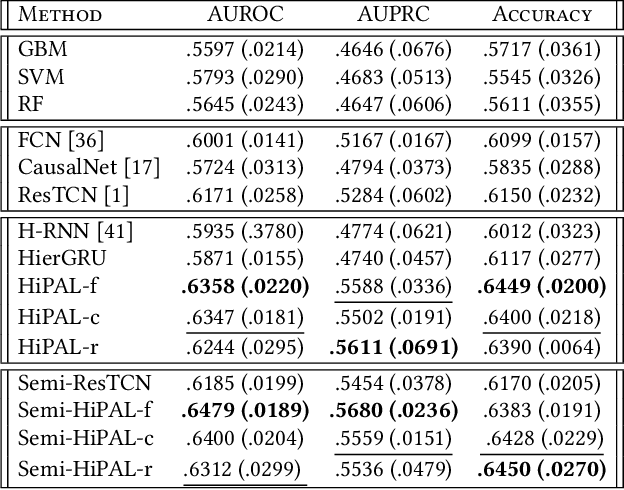

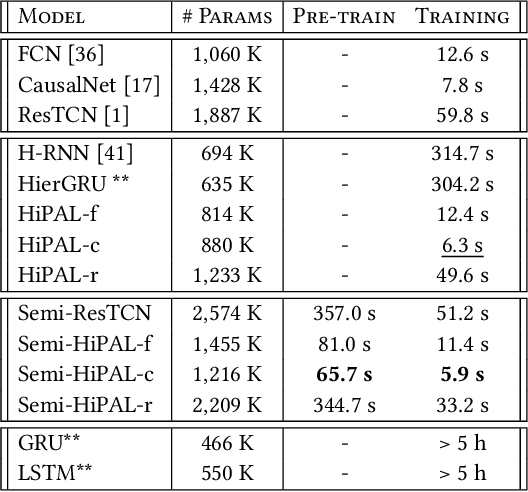
Burnout is a significant public health concern affecting nearly half of the healthcare workforce. This paper presents the first end-to-end deep learning framework for predicting physician burnout based on clinician activity logs, digital traces of their work activities, available in any electronic health record (EHR) system. In contrast to prior approaches that exclusively relied on surveys for burnout measurement, our framework directly learns deep workload representations from large-scale clinician activity logs to predict burnout. We propose the Hierarchical burnout Prediction based on Activity Logs (HiPAL), featuring a pre-trained time-dependent activity embedding mechanism tailored for activity logs and a hierarchical predictive model, which mirrors the natural hierarchical structure of clinician activity logs and captures physician's evolving workload patterns at both short-term and long-term levels. To utilize the large amount of unlabeled activity logs, we propose a semi-supervised framework that learns to transfer knowledge extracted from unlabeled clinician activities to the HiPAL-based prediction model. The experiment on over 15 million clinician activity logs collected from the EHR at a large academic medical center demonstrates the advantages of our proposed framework in predictive performance of physician burnout and training efficiency over state of the art approaches.
Objective-aware Traffic Simulation via Inverse Reinforcement Learning
May 20, 2021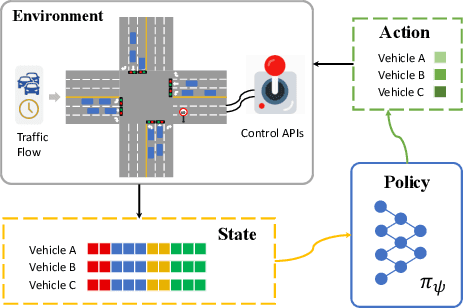

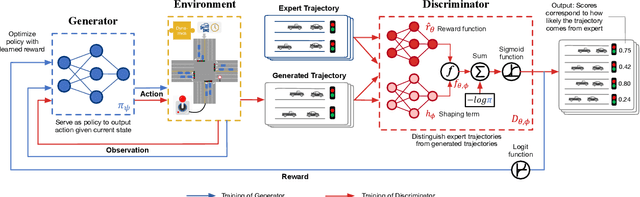
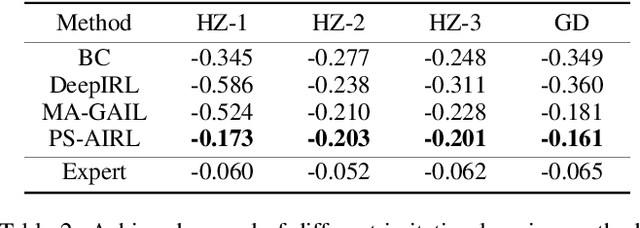
Traffic simulators act as an essential component in the operating and planning of transportation systems. Conventional traffic simulators usually employ a calibrated physical car-following model to describe vehicles' behaviors and their interactions with traffic environment. However, there is no universal physical model that can accurately predict the pattern of vehicle's behaviors in different situations. A fixed physical model tends to be less effective in a complicated environment given the non-stationary nature of traffic dynamics. In this paper, we formulate traffic simulation as an inverse reinforcement learning problem, and propose a parameter sharing adversarial inverse reinforcement learning model for dynamics-robust simulation learning. Our proposed model is able to imitate a vehicle's trajectories in the real world while simultaneously recovering the reward function that reveals the vehicle's true objective which is invariant to different dynamics. Extensive experiments on synthetic and real-world datasets show the superior performance of our approach compared to state-of-the-art methods and its robustness to variant dynamics of traffic.
Predicting Intraoperative Hypoxemia with Joint Sequence Autoencoder Networks
May 19, 2021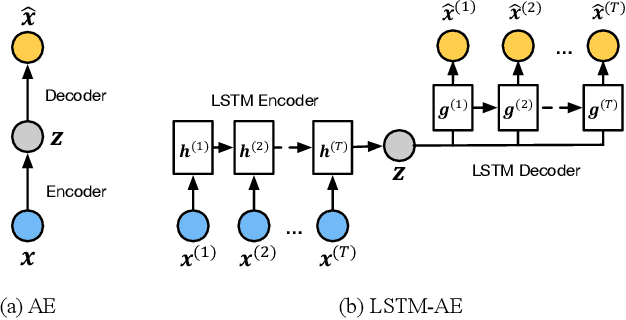
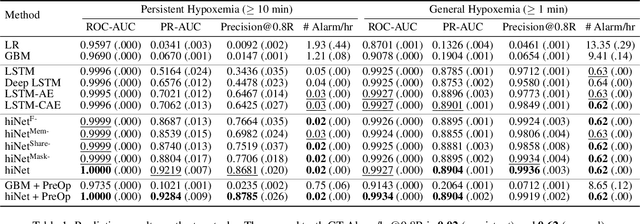
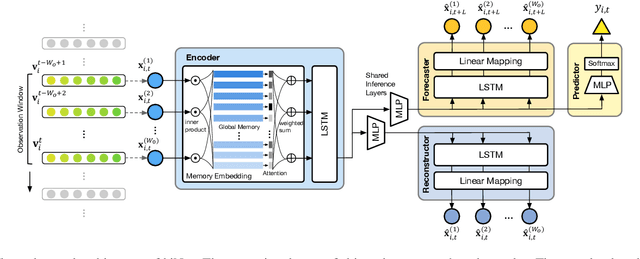
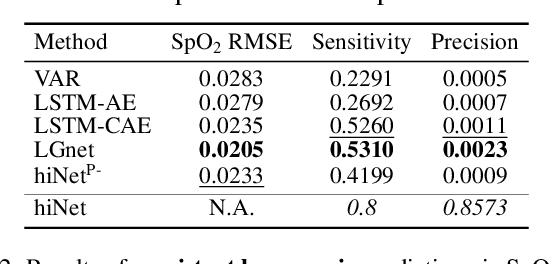
We present an end-to-end model using streaming physiological time series to accurately predict near-term risk for hypoxemia, a rare, but life-threatening condition known to cause serious patient harm during surgery. Our proposed model makes inference on both hypoxemia outcomes and future input sequences, enabled by a joint sequence autoencoder that simultaneously optimizes a discriminative decoder for label prediction, and two auxiliary decoders trained for data reconstruction and forecast, which seamlessly learns future-indicative latent representation. All decoders share a memory-based encoder that helps capture the global dynamics of patient data. In a large surgical cohort of 73,536 surgeries at a major academic medical center, our model outperforms all baselines and gives a large performance gain over the state-of-the-art hypoxemia prediction system. With a high sensitivity cutoff at 80%, it presents 99.36% precision in predicting hypoxemia and 86.81% precision in predicting the much more severe and rare hypoxemic condition, persistent hypoxemia. With exceptionally low rate of false alarms, our proposed model is promising in improving clinical decision making and easing burden on the health system.
Semi-supervised Federated Learning for Activity Recognition
Nov 06, 2020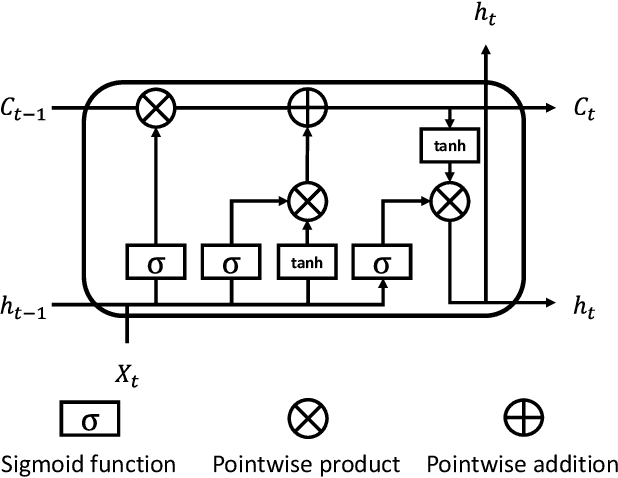



The proliferation of IoT sensors and edge devices makes it possible to use deep learning models to recognise daily activities locally using in-home monitoring technologies. Recently, federated learning systems that use edge devices as clients to collect and utilise IoT sensory data for human activity recognition have been commonly used as a new way to combine local (individual-level) and global (group-level) models. This approach provides better scalability and generalisability and also offers higher privacy compared with the traditional centralised analysis and learning models. The assumption behind federated learning, however, relies on supervised learning on clients. This requires a large volume of labelled data, which is difficult to collect in uncontrolled IoT environments such as remote in-home monitoring. In this paper, we propose an activity recognition system that uses semi-supervised federated learning, wherein clients conduct unsupervised learning on autoencoders with unlabelled local data to learn general representations, and a cloud server conducts supervised learning on an activity classifier with labelled data. Our experimental results show that using autoencoders and a long short-term memory (LSTM) classifier, the accuracy of our proposed system is comparable to that of a supervised federated learning system. Meanwhile, we demonstrate that our system is not affected by the Non-IID distribution of local data, and can even achieve better accuracy than supervised federated learning on some datasets. Additionally, we show that our proposed system can reduce the number of needed labels in the system and the size of local models without losing much accuracy, and has shorter local activity recognition time than supervised federated learning.