 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Apr 28, 2026Autonomous scientific research is significantly advanced thanks to the development of AI agents. One key step in this process is finding the right scientific literature, whether to explore existing knowledge for a research problem, or to acquire evidence for verifying assumptions and supporting claims. To assess AI agents' capability in driving this process, we present AutoResearchBench, a dedicated benchmark for autonomous scientific literature discovery. AutoResearchBench consists of two complementary task types: (1) Deep Research, which requires tracking down a specific target paper through a progressive, multi-step probing process, and (2) Wide Research, which requires comprehensively collecting a set of papers satisfying given conditions. Compared to previous benchmarks on agentic web browsing, AutoResearchBench is distinguished along three dimensions: it is research-oriented, calling for in-depth comprehension of scientific concepts; literature-focused, demanding fine-grained utilization of detailed information; and open-ended, involving an unknown number of qualified papers and thus requiring deliberate reasoning and search throughout. These properties make AutoResearchBench uniquely suited for evaluating autonomous research capabilities, and extraordinarily challenging. Even the most powerful LLMs, despite having largely conquered general agentic web-browsing benchmarks such as BrowseComp, achieve only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research, while many other strong baselines fall below 5%. We publicly release the dataset and evaluation pipeline to facilitate future research in this direction. We publicly release the dataset, evaluation pipeline, and code at https://github.com/CherYou/AutoResearchBench.
Render-in-the-Loop: Vector Graphics Generation via Visual Self-Feedback
Apr 22, 2026Multimodal Large Language Models (MLLMs) have shown promising capabilities in generating Scalable Vector Graphics (SVG) via direct code synthesis. However, existing paradigms typically adopt an open-loop "blind drawing" approach, where models generate symbolic code sequences without perceiving intermediate visual outcomes. This methodology severely underutilizes the powerful visual priors embedded in MLLMs vision encoders, treating SVG generation as a disjointed textual sequence modeling task rather than an integrated visuo-spatial one. Consequently, models struggle to reason about partial canvas states and implicit occlusion relationships, which are visually explicit but textually ambiguous. To bridge this gap, we propose Render-in-the-Loop, a novel generation paradigm that reformulates SVG synthesis as a step-wise, visual-context-aware process. By rendering intermediate code states into a cumulative canvas, the model explicitly observes the evolving visual context at each step, leveraging on-the-fly feedback to guide subsequent generation. However, we demonstrate that applying this visual loop naively to off-the-shelf models is suboptimal due to their inability to leverage incremental visual-code mappings. To address this, we first utilize fine-grained path decomposition to construct dense multi-step visual trajectories, and then introduce a Visual Self-Feedback (VSF) training strategy to condition the next primitive generation on intermediate visual states. Furthermore, a Render-and-Verify (RaV) inference mechanism is proposed to effectively filter degenerate and redundant primitives. Our framework, instantiated on a multimodal foundation model, outperforms strong open-weight baselines on the standard MMSVGBench. This result highlights the remarkable data efficiency and generalization capability of our Render-in-the-Loop paradigm for both Text-to-SVG and Image-to-SVG tasks.
ArtiCAD: Articulated CAD Assembly Design via Multi-Agent Code Generation
Apr 14, 2026Parametric Computer-Aided Design (CAD) of articulated assemblies is essential for product development, yet generating these multi-part, movable models from high-level descriptions remains unexplored. To address this, we propose ArtiCAD, the first training-free multi-agent system capable of generating editable, articulated CAD assemblies directly from text or images. Our system divides this complex task among four specialized agents: Design, Generation, Assembly, and Review. One of our key insights is to predict assembly relationships during the initial design stage rather than the assembly stage. By utilizing a Connector that explicitly defines attachment points and joint parameters, ArtiCAD determines these relationships before geometry generation, effectively bypassing the limited spatial reasoning capabilities of current LLMs and VLMs. To further ensure high-quality outputs, we introduce validation steps in the generation and assembly stages, accompanied by a cross-stage rollback mechanism that accurately isolates and corrects design- and code-level errors. Additionally, a self-evolving experience store accumulates design knowledge to continuously improve performance on future tasks. Extensive evaluations on three datasets (ArtiCAD-Bench, CADPrompt, and ACD) validate the effectiveness of our approach. We further demonstrate the applicability of ArtiCAD in requirement-driven conceptual design, physical prototyping, and the generation of embodied AI training assets through URDF export.
AmodalSVG: Amodal Image Vectorization via Semantic Layer Peeling
Apr 13, 2026We introduce AmodalSVG, a new framework for amodal image vectorization that produces semantically organized and geometrically complete SVG representations from natural images. Existing vectorization methods operate under a modal paradigm: tracing only visible pixels and disregarding occlusion. Consequently, the resulting SVGs are semantically entangled and geometrically incomplete, limiting SVG's structural editability. In contrast, AmodalSVG reconstructs full object geometries, including occluded regions, into independent, editable vector layers. To achieve this, AmodalSVG reformulates image vectorization as a two-stage framework, performing semantic decoupling and completion in the raster domain to produce amodally complete semantic layers, which are then independently vectorized. In the first stage, we introduce Semantic Layer Peeling (SLP), a VLM-guided strategy that progressively decomposes an image into semantically coherent layers. By hybrid inpainting, SLP recovers complete object appearances under occlusions, enabling explicit semantic decoupling. To vectorize these layers efficiently, we propose Adaptive Layered Vectorization (ALV), which dynamically modulates the primitive budget via an error-budget-driven adjustment mechanism. Extensive experiments demonstrate that AmodalSVG significantly outperforms prior methods in visual fidelity. Moreover, the resulting amodal layers enable object-level editing directly in the vector domain, capabilities not supported by existing vectorization approaches. Code will be released upon acceptance.
Hierarchical SVG Tokenization: Learning Compact Visual Programs for Scalable Vector Graphics Modeling
Apr 06, 2026Recent large language models have shifted SVG generation from differentiable rendering optimization to autoregressive program synthesis. However, existing approaches still rely on generic byte-level tokenization inherited from natural language processing, which poorly reflects the geometric structure of vector graphics. Numerical coordinates are fragmented into discrete symbols, destroying spatial relationships and introducing severe token redundancy, often leading to coordinate hallucination and inefficient long-sequence generation. To address these challenges, we propose HiVG, a hierarchical SVG tokenization framework tailored for autoregressive vector graphics generation. HiVG decomposes raw SVG strings into structured \textit{atomic tokens} and further compresses executable command--parameter groups into geometry-constrained \textit{segment tokens}, substantially improving sequence efficiency while preserving syntactic validity. To further mitigate spatial mismatch, we introduce a Hierarchical Mean--Noise (HMN) initialization strategy that injects numerical ordering signals and semantic priors into new token embeddings. Combined with a curriculum training paradigm that progressively increases program complexity, HiVG enables more stable learning of executable SVG programs. Extensive experiments on both text-to-SVG and image-to-SVG tasks demonstrate improved generation fidelity, spatial consistency, and sequence efficiency compared with conventional tokenization schemes.
Molecular Identifier Visual Prompt and Verifiable Reinforcement Learning for Chemical Reaction Diagram Parsing
Mar 17, 2026Reaction diagram parsing (RxnDP) is critical for extracting chemical synthesis information from literature. Although recent Vision-Language Models (VLMs) have emerged as a promising paradigm to automate this complex visual reasoning task, their application is fundamentally bottlenecked by the inability to align visual chemical entities with pre-trained knowledge, alongside the inherent discrepancy between token-level training and reaction-level evaluation. To address these dual challenges, this work enhances VLM-based RxnDP from two complementary perspectives: prompting representation and learning paradigms. First, we propose Identifier as Visual Prompting (IdtVP), which leverages naturally occurring molecule identifiers (e.g., bold numerals like 1a) to activate the chemical knowledge acquired during VLM pre-training. IdtVP enables powerful zero-shot and out-of-distribution capabilities, outperforming existing prompting strategies. Second, to further optimize performance within fine-tuning paradigms, we introduce Re3-DAPO, a reinforcement learning algorithm that leverages verifiable rewards to directly optimize reaction-level metrics, thereby achieving consistent gains over standard supervised fine-tuning. Additionally, we release the ScannedRxn benchmark, comprising scanned historical reaction diagrams with real-world artifacts, to rigorously assess model robustness and out-of-distribution ability. Our contributions advance the accuracy and generalization of VLM-based reaction diagram parsing. We will release data, models, and code on GitHub.
ELBO-T2IAlign: A Generic ELBO-Based Method for Calibrating Pixel-level Text-Image Alignment in Diffusion Models
Jun 11, 2025Diffusion models excel at image generation. Recent studies have shown that these models not only generate high-quality images but also encode text-image alignment information through attention maps or loss functions. This information is valuable for various downstream tasks, including segmentation, text-guided image editing, and compositional image generation. However, current methods heavily rely on the assumption of perfect text-image alignment in diffusion models, which is not the case. In this paper, we propose using zero-shot referring image segmentation as a proxy task to evaluate the pixel-level image and class-level text alignment of popular diffusion models. We conduct an in-depth analysis of pixel-text misalignment in diffusion models from the perspective of training data bias. We find that misalignment occurs in images with small sized, occluded, or rare object classes. Therefore, we propose ELBO-T2IAlign, a simple yet effective method to calibrate pixel-text alignment in diffusion models based on the evidence lower bound (ELBO) of likelihood. Our method is training-free and generic, eliminating the need to identify the specific cause of misalignment and works well across various diffusion model architectures. Extensive experiments on commonly used benchmark datasets on image segmentation and generation have verified the effectiveness of our proposed calibration approach.
Reason-SVG: Hybrid Reward RL for Aha-Moments in Vector Graphics Generation
May 30, 2025Generating high-quality Scalable Vector Graphics (SVGs) is challenging for Large Language Models (LLMs), as it requires advanced reasoning for structural validity, semantic faithfulness, and visual coherence -- capabilities in which current LLMs often fall short. In this work, we introduce Reason-SVG, a novel framework designed to enhance LLM reasoning for SVG generation. Reason-SVG pioneers the "Drawing-with-Thought" (DwT) paradigm, in which models generate both SVG code and explicit design rationales, mimicking the human creative process. Reason-SVG adopts a two-stage training strategy: First, Supervised Fine-Tuning (SFT) trains the LLM on the DwT paradigm to activate foundational reasoning abilities. Second, Reinforcement Learning (RL), utilizing Group Relative Policy Optimization (GRPO), empowers the model to generate both DwT and SVGs rationales through refined, reward-driven reasoning. To facilitate reasoning-driven SVG generation, we design a Hybrid Reward function that evaluates the presence and utility of DwT reasoning, along with structural validity, semantic alignment, and visual quality. We also introduce the SVGX-DwT-10k dataset, a high-quality corpus of 10,000 SVG-DwT pairs, where each SVG code is generated based on explicit DwT reasoning. By integrating DwT, SFT, and Hybrid Reward-guided RL, Reason-SVG significantly improves LLM performance in generating accurate and visually compelling SVGs, potentially fostering "Aha moments" in design.
Unleashing the Power of Intermediate Domains for Mixed Domain Semi-Supervised Medical Image Segmentation
May 30, 2025Both limited annotation and domain shift are prevalent challenges in medical image segmentation. Traditional semi-supervised segmentation and unsupervised domain adaptation methods address one of these issues separately. However, the coexistence of limited annotation and domain shift is quite common, which motivates us to introduce a novel and challenging scenario: Mixed Domain Semi-supervised medical image Segmentation (MiDSS), where limited labeled data from a single domain and a large amount of unlabeled data from multiple domains. To tackle this issue, we propose the UST-RUN framework, which fully leverages intermediate domain information to facilitate knowledge transfer. We employ Unified Copy-paste (UCP) to construct intermediate domains, and propose a Symmetric GuiDance training strategy (SymGD) to supervise unlabeled data by merging pseudo-labels from intermediate samples. Subsequently, we introduce a Training Process aware Random Amplitude MixUp (TP-RAM) to progressively incorporate style-transition components into intermediate samples. To generate more diverse intermediate samples, we further select reliable samples with high-quality pseudo-labels, which are then mixed with other unlabeled data. Additionally, we generate sophisticated intermediate samples with high-quality pseudo-labels for unreliable samples, ensuring effective knowledge transfer for them. Extensive experiments on four public datasets demonstrate the superiority of UST-RUN. Notably, UST-RUN achieves a 12.94% improvement in Dice score on the Prostate dataset. Our code is available at https://github.com/MQinghe/UST-RUN
ViewCraft3D: High-Fidelity and View-Consistent 3D Vector Graphics Synthesis
May 26, 2025
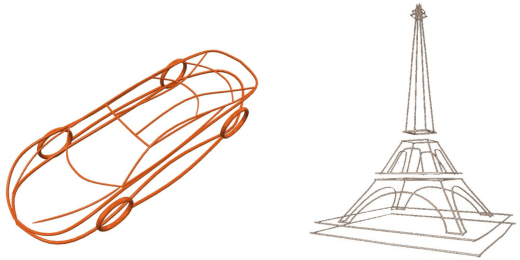
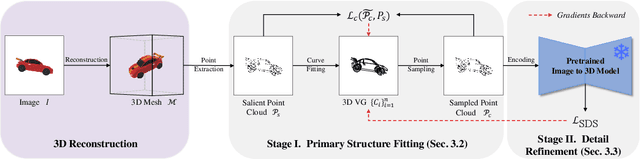
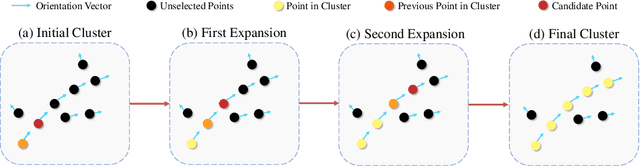
3D vector graphics play a crucial role in various applications including 3D shape retrieval, conceptual design, and virtual reality interactions due to their ability to capture essential structural information with minimal representation. While recent approaches have shown promise in generating 3D vector graphics, they often suffer from lengthy processing times and struggle to maintain view consistency. To address these limitations, we propose ViewCraft3D (VC3D), an efficient method that leverages 3D priors to generate 3D vector graphics. Specifically, our approach begins with 3D object analysis, employs a geometric extraction algorithm to fit 3D vector graphics to the underlying structure, and applies view-consistent refinement process to enhance visual quality. Our comprehensive experiments demonstrate that VC3D outperforms previous methods in both qualitative and quantitative evaluations, while significantly reducing computational overhead. The resulting 3D sketches maintain view consistency and effectively capture the essential characteristics of the original objects.