 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegGraph: Leveraging Graphs of SAM Segments for Few-Shot 3D Part Segmentation
Dec 18, 2025This work presents a novel framework for few-shot 3D part segmentation. Recent advances have demonstrated the significant potential of 2D foundation models for low-shot 3D part segmentation. However, it is still an open problem that how to effectively aggregate 2D knowledge from foundation models to 3D. Existing methods either ignore geometric structures for 3D feature learning or neglects the high-quality grouping clues from SAM, leading to under-segmentation and inconsistent part labels. We devise a novel SAM segment graph-based propagation method, named SegGraph, to explicitly learn geometric features encoded within SAM's segmentation masks. Our method encodes geometric features by modeling mutual overlap and adjacency between segments while preserving intra-segment semantic consistency. We construct a segment graph, conceptually similar to an atlas, where nodes represent segments and edges capture their spatial relationships (overlap/adjacency). Each node adaptively modulates 2D foundation model features, which are then propagated via a graph neural network to learn global geometric structures. To enforce intra-segment semantic consistency, we map segment features to 3D points with a novel view-direction-weighted fusion attenuating contributions from low-quality segments. Extensive experiments on PartNet-E demonstrate that our method outperforms all competing baselines by at least 6.9 percent mIoU. Further analysis reveals that SegGraph achieves particularly strong performance on small components and part boundaries, demonstrating its superior geometric understanding. The code is available at: https://github.com/YueyangHu2000/SegGraph.
VGR: Visual Grounded Reasoning
Jun 16, 2025In the field of multimodal chain-of-thought (CoT) reasoning, existing approaches predominantly rely on reasoning on pure language space, which inherently suffers from language bias and is largely confined to math or science domains. This narrow focus limits their ability to handle complex visual reasoning tasks that demand comprehensive understanding of image details. To address these limitations, this paper introduces VGR, a novel reasoning multimodal large language model (MLLM) with enhanced fine-grained visual perception capabilities. Unlike traditional MLLMs that answer the question or reasoning solely on the language space, our VGR first detects relevant regions that may help to solve problems, and then provides precise answers based on replayed image regions. To achieve this, we conduct a large-scale SFT dataset called VGR -SFT that contains reasoning data with mixed vision grounding and language deduction. The inference pipeline of VGR allows the model to choose bounding boxes for visual reference and a replay stage is introduced to integrates the corresponding regions into the reasoning process, enhancing multimodel comprehension. Experiments on the LLaVA-NeXT-7B baseline show that VGR achieves superior performance on multi-modal benchmarks requiring comprehensive image detail understanding. Compared to the baseline, VGR uses only 30\% of the image token count while delivering scores of +4.1 on MMStar, +7.1 on AI2D, and a +12.9 improvement on ChartQA.
Empowering Vector Graphics with Consistently Arbitrary Viewing and View-dependent Visibility
May 27, 2025This work presents a novel text-to-vector graphics generation approach, Dream3DVG, allowing for arbitrary viewpoint viewing, progressive detail optimization, and view-dependent occlusion awareness. Our approach is a dual-branch optimization framework, consisting of an auxiliary 3D Gaussian Splatting optimization branch and a 3D vector graphics optimization branch. The introduced 3DGS branch can bridge the domain gaps between text prompts and vector graphics with more consistent guidance. Moreover, 3DGS allows for progressive detail control by scheduling classifier-free guidance, facilitating guiding vector graphics with coarse shapes at the initial stages and finer details at later stages. We also improve the view-dependent occlusions by devising a visibility-awareness rendering module. Extensive results on 3D sketches and 3D iconographies, demonstrate the superiority of the method on different abstraction levels of details, cross-view consistency, and occlusion-aware stroke culling.
RelTriple: Learning Plausible Indoor Layouts by Integrating Relationship Triples into the Diffusion Process
Mar 26, 2025



The generation of indoor furniture layouts has significant applications in augmented reality, smart homes, and architectural design. Successful furniture arrangement requires proper physical relationships (e.g., collision avoidance) and spacing relationships between furniture and their functional zones to be respected. However, manually defined relationships are almost always incomplete and can produce unrealistic layouts. This work instead extracts spacing relationships automatically based on a hierarchical analysis and adopts the Delaunay Triangulation to produce important triple relationships. Compared to pairwise relationship modeling, triple relationships account for interactions and space utilization among multiple objects. To this end, we introduce RelTriple, a novel approach that enhances furniture distribution by learning spacing relationships between objects and regions. We formulate triple relationships as object-to-object (O2O) losses and object-to-region (O2R) losses and integrate them directly into the training process of generative diffusion. Our approach consistently improves over existing state-of-the-art methods in visual results evaluation metrics on unconditional layout generation, floorplan-conditioned layout generation, and scene rearrangement, achieving at least 12% on the introduced spatial relationship metric and superior spatial coherence and practical usability.
VRsketch2Gaussian: 3D VR Sketch Guided 3D Object Generation with Gaussian Splatting
Mar 16, 2025We propose VRSketch2Gaussian, a first VR sketch-guided, multi-modal, native 3D object generation framework that incorporates a 3D Gaussian Splatting representation. As part of our work, we introduce VRSS, the first large-scale paired dataset containing VR sketches, text, images, and 3DGS, bridging the gap in multi-modal VR sketch-based generation. Our approach features the following key innovations: 1) Sketch-CLIP feature alignment. We propose a two-stage alignment strategy that bridges the domain gap between sparse VR sketch embeddings and rich CLIP embeddings, facilitating both VR sketch-based retrieval and generation tasks. 2) Fine-Grained multi-modal conditioning. We disentangle the 3D generation process by using explicit VR sketches for geometric conditioning and text descriptions for appearance control. To facilitate this, we propose a generalizable VR sketch encoder that effectively aligns different modalities. 3) Efficient and high-fidelity 3D native generation. Our method leverages a 3D-native generation approach that enables fast and texture-rich 3D object synthesis. Experiments conducted on our VRSS dataset demonstrate that our method achieves high-quality, multi-modal VR sketch-based 3D generation. We believe our VRSS dataset and VRsketch2Gaussian method will be beneficial for the 3D generation community.
World to Code: Multi-modal Data Generation via Self-Instructed Compositional Captioning and Filtering
Sep 30, 2024



Recent advances in Vision-Language Models (VLMs) and the scarcity of high-quality multi-modal alignment data have inspired numerous researches on synthetic VLM data generation. The conventional norm in VLM data construction uses a mixture of specialists in caption and OCR, or stronger VLM APIs and expensive human annotation. In this paper, we present World to Code (W2C), a meticulously curated multi-modal data construction pipeline that organizes the final generation output into a Python code format. The pipeline leverages the VLM itself to extract cross-modal information via different prompts and filter the generated outputs again via a consistency filtering strategy. Experiments have demonstrated the high quality of W2C by improving various existing visual question answering and visual grounding benchmarks across different VLMs. Further analysis also demonstrates that the new code parsing ability of VLMs presents better cross-modal equivalence than the commonly used detail caption ability. Our code is available at https://github.com/foundation-multimodal-models/World2Code.
PS-CAD: Local Geometry Guidance via Prompting and Selection for CAD Reconstruction
May 24, 2024Reverse engineering CAD models from raw geometry is a classic but challenging research problem. In particular, reconstructing the CAD modeling sequence from point clouds provides great interpretability and convenience for editing. To improve upon this problem, we introduce geometric guidance into the reconstruction network. Our proposed model, PS-CAD, reconstructs the CAD modeling sequence one step at a time. At each step, we provide two forms of geometric guidance. First, we provide the geometry of surfaces where the current reconstruction differs from the complete model as a point cloud. This helps the framework to focus on regions that still need work. Second, we use geometric analysis to extract a set of planar prompts, that correspond to candidate surfaces where a CAD extrusion step could be started. Our framework has three major components. Geometric guidance computation extracts the two types of geometric guidance. Single-step reconstruction computes a single candidate CAD modeling step for each provided prompt. Single-step selection selects among the candidate CAD modeling steps. The process continues until the reconstruction is completed. Our quantitative results show a significant improvement across all metrics. For example, on the dataset DeepCAD, PS-CAD improves upon the best published SOTA method by reducing the geometry errors (CD and HD) by 10%, and the structural error (ECD metric) by about 15%.
CSG-Stump: A Learning Friendly CSG-Like Representation for Interpretable Shape Parsing
Aug 25, 2021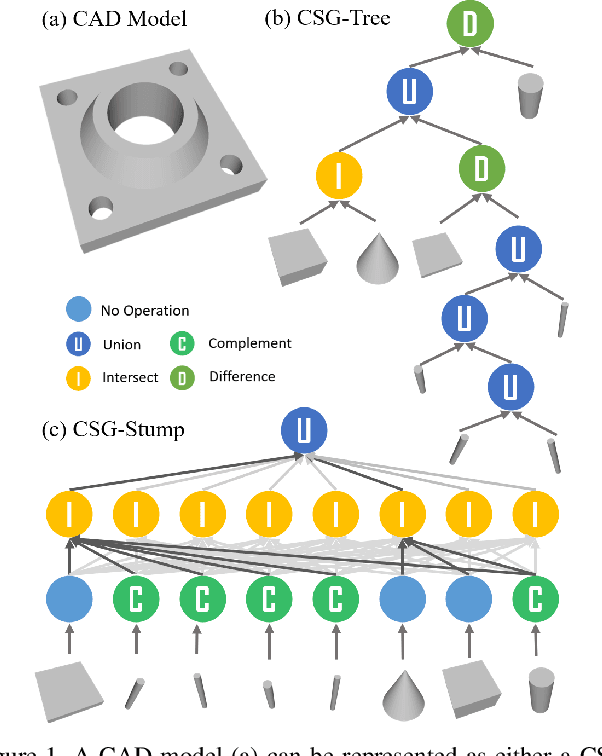

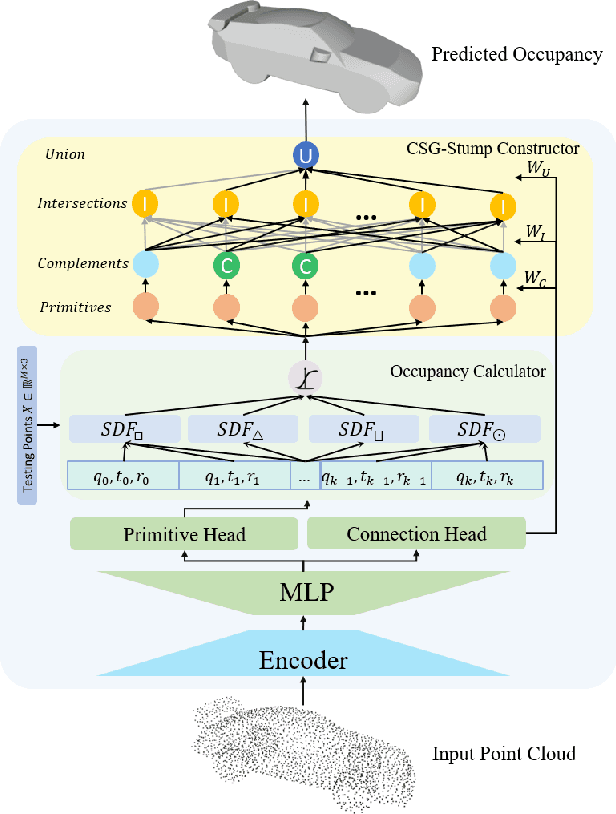
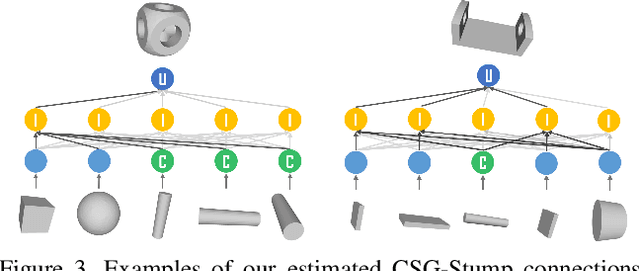
Generating an interpretable and compact representation of 3D shapes from point clouds is an important and challenging problem. This paper presents CSG-Stump Net, an unsupervised end-to-end network for learning shapes from point clouds and discovering the underlying constituent modeling primitives and operations as well. At the core is a three-level structure called {\em CSG-Stump}, consisting of a complement layer at the bottom, an intersection layer in the middle, and a union layer at the top. CSG-Stump is proven to be equivalent to CSG in terms of representation, therefore inheriting the interpretable, compact and editable nature of CSG while freeing from CSG's complex tree structures. Particularly, the CSG-Stump has a simple and regular structure, allowing neural networks to give outputs of a constant dimensionality, which makes itself deep-learning friendly. Due to these characteristics of CSG-Stump, CSG-Stump Net achieves superior results compared to previous CSG-based methods and generates much more appealing shapes, as confirmed by extensive experiments. Project page: https://kimren227.github.io/projects/CSGStump/