 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegGraph: Leveraging Graphs of SAM Segments for Few-Shot 3D Part Segmentation
Dec 18, 2025This work presents a novel framework for few-shot 3D part segmentation. Recent advances have demonstrated the significant potential of 2D foundation models for low-shot 3D part segmentation. However, it is still an open problem that how to effectively aggregate 2D knowledge from foundation models to 3D. Existing methods either ignore geometric structures for 3D feature learning or neglects the high-quality grouping clues from SAM, leading to under-segmentation and inconsistent part labels. We devise a novel SAM segment graph-based propagation method, named SegGraph, to explicitly learn geometric features encoded within SAM's segmentation masks. Our method encodes geometric features by modeling mutual overlap and adjacency between segments while preserving intra-segment semantic consistency. We construct a segment graph, conceptually similar to an atlas, where nodes represent segments and edges capture their spatial relationships (overlap/adjacency). Each node adaptively modulates 2D foundation model features, which are then propagated via a graph neural network to learn global geometric structures. To enforce intra-segment semantic consistency, we map segment features to 3D points with a novel view-direction-weighted fusion attenuating contributions from low-quality segments. Extensive experiments on PartNet-E demonstrate that our method outperforms all competing baselines by at least 6.9 percent mIoU. Further analysis reveals that SegGraph achieves particularly strong performance on small components and part boundaries, demonstrating its superior geometric understanding. The code is available at: https://github.com/YueyangHu2000/SegGraph.
VRsketch2Gaussian: 3D VR Sketch Guided 3D Object Generation with Gaussian Splatting
Mar 16, 2025We propose VRSketch2Gaussian, a first VR sketch-guided, multi-modal, native 3D object generation framework that incorporates a 3D Gaussian Splatting representation. As part of our work, we introduce VRSS, the first large-scale paired dataset containing VR sketches, text, images, and 3DGS, bridging the gap in multi-modal VR sketch-based generation. Our approach features the following key innovations: 1) Sketch-CLIP feature alignment. We propose a two-stage alignment strategy that bridges the domain gap between sparse VR sketch embeddings and rich CLIP embeddings, facilitating both VR sketch-based retrieval and generation tasks. 2) Fine-Grained multi-modal conditioning. We disentangle the 3D generation process by using explicit VR sketches for geometric conditioning and text descriptions for appearance control. To facilitate this, we propose a generalizable VR sketch encoder that effectively aligns different modalities. 3) Efficient and high-fidelity 3D native generation. Our method leverages a 3D-native generation approach that enables fast and texture-rich 3D object synthesis. Experiments conducted on our VRSS dataset demonstrate that our method achieves high-quality, multi-modal VR sketch-based 3D generation. We believe our VRSS dataset and VRsketch2Gaussian method will be beneficial for the 3D generation community.
DI-Fusion: Online Implicit 3D Reconstruction with Deep Priors
Dec 10, 2020
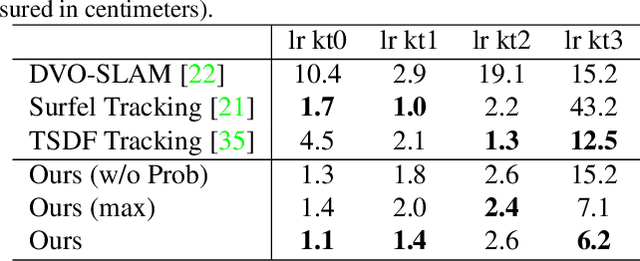
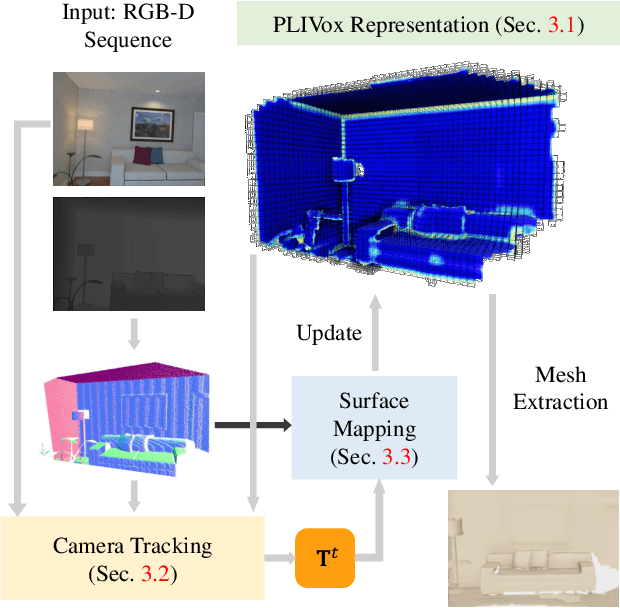
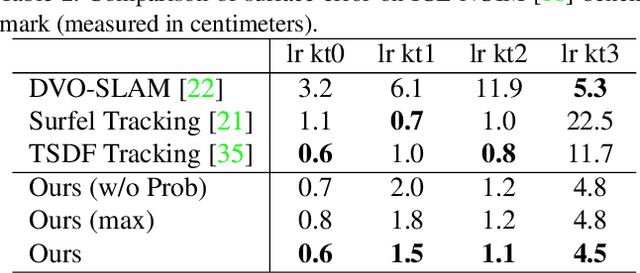
Previous online 3D dense reconstruction methods often cost massive memory storage while achieving unsatisfactory surface quality mainly due to the usage of stagnant underlying geometry representation, such as TSDF (truncated signed distance functions) or surfels, without any knowledge of the scene priors. In this paper, we present DI-Fusion (Deep Implicit Fusion), based on a novel 3D representation, called Probabilistic Local Implicit Voxels (PLIVoxs), for online 3D reconstruction using a commodity RGB-D camera. Our PLIVox encodes scene priors considering both the local geometry and uncertainty parameterized by a deep neural network. With such deep priors, we demonstrate by extensive experiments that we are able to perform online implicit 3D reconstruction achieving state-of-the-art mapping quality and camera trajectory estimation accuracy, while taking much less storage compared with previous online 3D reconstruction approaches.
QGAN: Quantized Generative Adversarial Networks
Jan 24, 2019
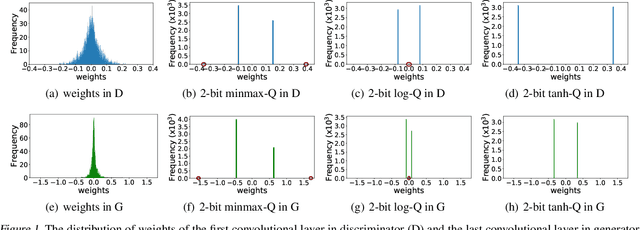
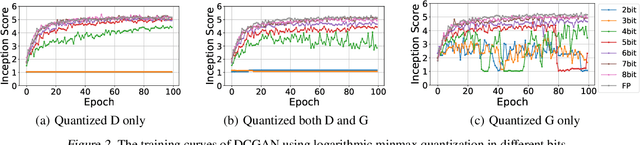
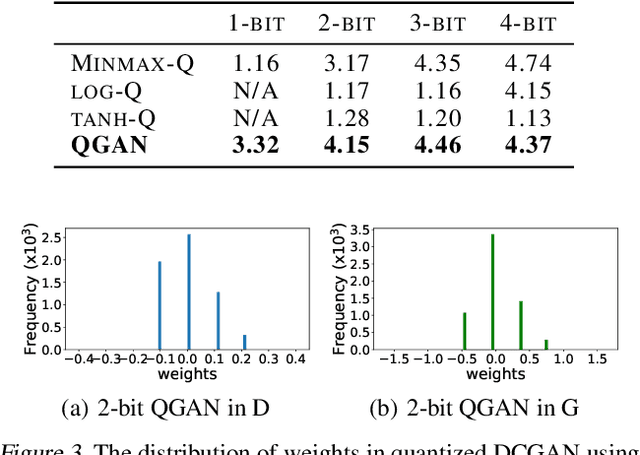
The intensive computation and memory requirements of generative adversarial neural networks (GANs) hinder its real-world deployment on edge devices such as smartphones. Despite the success in model reduction of CNNs, neural network quantization methods have not yet been studied on GANs, which are mainly faced with the issues of both the effectiveness of quantization algorithms and the instability of training GAN models. In this paper, we start with an extensive study on applying existing successful methods to quantize GANs. Our observation reveals that none of them generates samples with reasonable quality because of the underrepresentation of quantized values in model weights, and the generator and discriminator networks show different sensitivities upon quantization methods. Motivated by these observations, we develop a novel quantization method for GANs based on EM algorithms, named as QGAN. We also propose a multi-precision algorithm to help find the optimal number of bits of quantized GAN models in conjunction with corresponding result qualities. Experiments on CIFAR-10 and CelebA show that QGAN can quantize GANs to even 1-bit or 2-bit representations with results of quality comparable to original models.