 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Cloud-Grade SLOs for Local Mixture-of-Experts Inference through CPU-GPU Hybrid Design
Jun 09, 2026Local deployment of large Mixture-of-Experts (MoE) models falls short of the service quality achieved in cloud-scale environments, even under low-concurrency workloads. We identify four key gaps in local MoE inference: reliance on capacity-reduced models (quantized, distilled, rerouted), inability to meet 30-second TTFT for long prefills (more than 12K), sub-baseline decode throughput (under 20 tokens/s), and poor concurrency under mixed prefill-decode and batched decode workloads. We present a CPU-GPU hybrid system that achieves cloud-level SLOs on dual-socket commodity CPUs and consumer GPUs by (1) stream-loading prefill (SLP), boosting prefill throughput to 1,200 tokens/s and enabling 32K prompts within 30 seconds; (2) distributed SLP (DSLP) with SmallEP expert parallelism, reaching 1,800 tokens/s and 45K prompts in 30 seconds on two RTX 5090s; (3) intra-node prefill-decode disaggregation with zero-copy shared weights and a dual-batch attention-MoE overlap scheme, sustaining concurrency with under 15 percent latency increase and 50 percent throughput gains; (4) an AVX-512-optimized FP8 GEMV kernel, enabling native CPU FP8 inference while delivering 4-5x lower CPU latency; and (5) fine-grained CPU parallelism that attains 28 tokens/s on INT4 DeepSeek-V3 and 21.5 tokens/s on intact FP8 V3. Evaluations show our system delivers cloud-level QoS for flagship MoE models on consumer CPU-GPU platforms, reshaping local deployment with intact, original-precision inference and enabling high-quality, cost-effective access without datacenter infrastructure.
Think Before You Act: Intention-Guided Reasoning for LLM-Based Location Prediction
Jun 06, 2026Predicting a user's next Point-of-Interest (POI) based on their historical check-in records is a fundamental task in location-based services. While recent methods incorporating large language models have shown strong reasoning capabilities and promising results, they typically formulate the prediction task as a one-step trajectory-to-location mapping problem, making predictions prone to shallow trajectory correlations and historical frequency bias. We argue that users rarely choose locations directly and instead, they usually first form a traveling intention and then accordingly select specific POIs. Motivated by this insight, we propose IntentPOI, a two-stage intention-guided reasoning framework. In the thinking stage, we infer users' intermediate intentions by incorporating historical mobility patterns, similar peer behaviors, and the temporal contexts. In the acting stage, we first construct a compact candidate pool, and then perform intention-guided reasoning to identify locations that best align with the inferred intention. By explicitly decoupling intention inference from location prediction, IntentPOI transforms the next POI prediction from direct trajectory matching into intention-guided reasoning. Extensive experiments on three real-world datasets demonstrate that IntentPOI consistently outperforms eleven state-of-the-art baselines.
Pixel Cube: Diffusion-based Portrait Video Relighting Through Realistic Lighting Reproduction
Jun 05, 2026We present a diffusion-based method for relighting dynamic portrait videos with photorealism and temporal consistency. Our method is fueled by a hybrid training dataset that consists of real-captured and rendered dynamic portrait videos with diverse subject appearances, facial motions, head poses, and known lighting conditions. Specifically, we construct an LED-based lighting system for realistic lighting emulation and high-speed video relighting data acquisition. By leveraging the image priors embedded in pre-trained video diffusion models, and using per-frame high dynamic range (HDR) environment map as lighting control, we train a high-performance generative model for realistic and identity-preserving dynamic portrait video relighting. In addition to the environment map control, our model uses a synthesized background image to enable control on the camera's exposure level and color tone. Our model can produce temporally consistent relit portrait video that looks realistic and harmonious under a provided new environment and faithfully preserve the subject's expression and fine facial features, including skin tone, wrinkles, and facial hair. Our model generalizes well to unseen data, in terms of the subject appearance, motion, and lighting condition. We perform extensive experiments on relighting in-the-wild videos with various environment maps and demonstrate practical applications on portrait photography. Results show that our method achieves state-of-the-art performance in photorealism, lighting harmony, and temporal consistency.
* ACM SIGGRAPH 2026 Journal Track / ACM Transactions on Graphics, 17 pages. Project page: https://yufanzhang82.github.io/PixelCube/
Predicting Preschoolers' Externalizing Problems with Mother-Child Interaction Dynamics and Deep Learning
Dec 29, 2024Objective: Predicting children's future levels of externalizing problems helps to identify children at risk and guide targeted prevention. Existing studies have shown that mothers providing support in response to children's dysregulation was associated with children's lower levels of externalizing problems. The current study aims to evaluate and improve the accuracy of predicting children's externalizing problems with mother-child interaction dynamics. Method: This study used mother-child interaction dynamics during a challenging puzzle task to predict children's externalizing problems six months later (N=101, 46 boys, Mage=57.41 months, SD=6.58). Performance of the Residual Dynamic Structural Equation Model (RDSEM) was compared with the Attention-based Sequential Behavior Interaction Modeling (ASBIM) model, developed using the deep learning techniques. Results: The RDSEM revealed that children whose mothers provided more autonomy support after increases of child defeat had lower levels of externalizing problems. Five-fold cross-validation showed that the RDSEM had good prediction accuracy. The ASBIM model further improved prediction accuracy, especially after including child inhibitory control as a personalized individual feature. Conclusions: The dynamic process of mother-child interaction provides important information for predicting children's externalizing problems, especially maternal autonomy supportive response to child defeat. The deep learning model is a useful tool to further improve prediction accuracy.
DECIDER: A Rule-Controllable Decoding Strategy for Language Generation by Imitating Dual-System Cognitive Theory
Mar 04, 2024Lexicon-based constrained decoding approaches aim to control the meaning or style of the generated text through certain target concepts. Existing approaches over-focus the targets themselves, leading to a lack of high-level reasoning about how to achieve them. However, human usually tackles tasks by following certain rules that not only focuses on the targets but also on semantically relevant concepts that induce the occurrence of targets. In this work, we present DECIDER, a rule-controllable decoding strategy for constrained language generation inspired by dual-system cognitive theory. Specifically, in DECIDER, a pre-trained language model (PLM) is equiped with a logic reasoner that takes high-level rules as input. Then, the DECIDER allows rule signals to flow into the PLM at each decoding step. Extensive experimental results demonstrate that DECIDER can effectively follow given rules to guide generation direction toward the targets in a more human-like manner.
Metacognition-Enhanced Few-Shot Prompting With Positive Reinforcement
Dec 24, 2023



Few-shot prompting elicits the remarkable abilities of large language models by equipping them with a few demonstration examples in the input. However, the traditional method of providing large language models with all demonstration input-output pairs at once may not effectively guide large language models to learn the specific input-output mapping relationship. In this paper, inspired by the regulatory and supportive role of metacognition in students' learning, we propose a novel metacognition-enhanced few-shot prompting, which guides large language models to reflect on their thought processes to comprehensively learn the given demonstration examples. Furthermore, considering that positive reinforcement can improve students' learning motivation, we introduce positive reinforcement into our metacognition-enhanced few-shot prompting to promote the few-shot learning of large language models by providing response-based positive feedback. The experimental results on two real-world datasets show that our metacognition-enhanced few-shot prompting with positive reinforcement surpasses traditional few-shot prompting in classification accuracy and macro F1.
Text2Bundle: Towards Personalized Query-based Bundle Generation
Oct 27, 2023



Bundle generation aims to provide a bundle of items for the user, and has been widely studied and applied on online service platforms. Existing bundle generation methods mainly utilized user's preference from historical interactions in common recommendation paradigm, and ignored the potential textual query which is user's current explicit intention. There can be a scenario in which a user proactively queries a bundle with some natural language description, the system should be able to generate a bundle that exactly matches the user's intention through the user's query and preferences. In this work, we define this user-friendly scenario as Query-based Bundle Generation task and propose a novel framework Text2Bundle that leverages both the user's short-term interests from the query and the user's long-term preferences from the historical interactions. Our framework consists of three modules: (1) a query interest extractor that mines the user's fine-grained interests from the query; (2) a unified state encoder that learns the current bundle context state and the user's preferences based on historical interaction and current query; and (3) a bundle generator that generates personalized and complementary bundles using a reinforcement learning with specifically designed rewards. We conduct extensive experiments on three real-world datasets and demonstrate the effectiveness of our framework compared with several state-of-the-art methods.
Towards Multi-Subsession Conversational Recommendation
Oct 20, 2023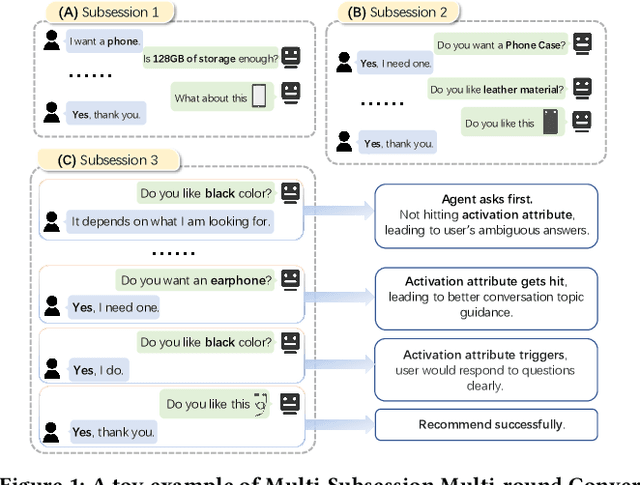
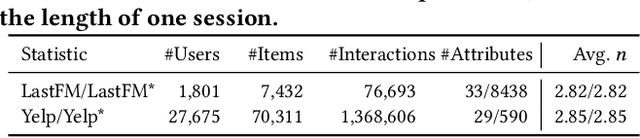
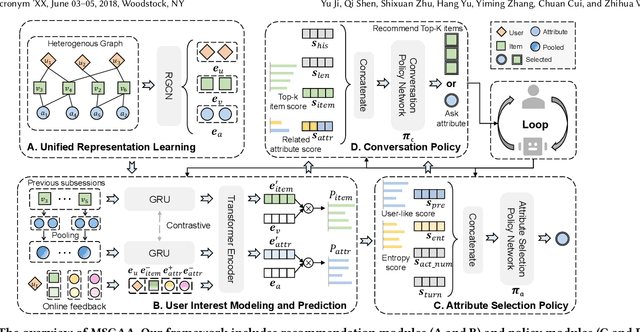
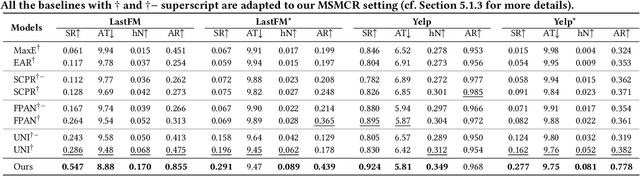
Conversational recommendation systems (CRS) could acquire dynamic user preferences towards desired items through multi-round interactive dialogue. Previous CRS mainly focuses on the single conversation (subsession) that user quits after a successful recommendation, neglecting the common scenario where user has multiple conversations (multi-subsession) over a short period. Therefore, we propose a novel conversational recommendation scenario named Multi-Subsession Multi-round Conversational Recommendation (MSMCR), where user would still resort to CRS after several subsessions and might preserve vague interests, and system would proactively ask attributes to activate user interests in the current subsession. To fill the gap in this new CRS scenario, we devise a novel framework called Multi-Subsession Conversational Recommender with Activation Attributes (MSCAA). Specifically, we first develop a context-aware recommendation module, comprehensively modeling user interests from historical interactions, previous subsessions, and feedback in the current subsession. Furthermore, an attribute selection policy module is proposed to learn a flexible strategy for asking appropriate attributes to elicit user interests. Finally, we design a conversation policy module to manage the above two modules to decide actions between asking and recommending. Extensive experiments on four datasets verify the effectiveness of our MSCAA framework for the MSMCR setting.
Textureless Deformable Surface Reconstruction with Invisible Markers
Aug 25, 2023Reconstructing and tracking deformable surface with little or no texture has posed long-standing challenges. Fundamentally, the challenges stem from textureless surfaces lacking features for establishing cross-image correspondences. In this work, we present a novel type of markers to proactively enrich the object's surface features, and thereby ease the 3D surface reconstruction and correspondence tracking. Our markers are made of fluorescent dyes, visible only under the ultraviolet (UV) light and invisible under regular lighting condition. Leveraging the markers, we design a multi-camera system that captures surface deformation under the UV light and the visible light in a time multiplexing fashion. Under the UV light, markers on the object emerge to enrich its surface texture, allowing high-quality 3D shape reconstruction and tracking. Under the visible light, markers become invisible, allowing us to capture the object's original untouched appearance. We perform experiments on various challenging scenes, including hand gestures, facial expressions, waving cloth, and hand-object interaction. In all these cases, we demonstrate that our system is able to produce robust, high-quality 3D reconstruction and tracking.
Is ChatGPT a Good Personality Recognizer? A Preliminary Study
Jul 26, 2023In recent years, personality has been regarded as a valuable personal factor being incorporated into numerous tasks such as sentiment analysis and product recommendation. This has led to widespread attention to text-based personality recognition task, which aims to identify an individual's personality based on given text. Considering that ChatGPT has recently exhibited remarkable abilities on various natural language processing tasks, we provide a preliminary evaluation of ChatGPT on text-based personality recognition task for generating effective personality data. Concretely, we employ a variety of prompting strategies to explore ChatGPT's ability in recognizing personality from given text, especially the level-oriented prompting strategy we designed for guiding ChatGPT in analyzing given text at a specified level. The experimental results on two representative real-world datasets reveal that ChatGPT with zero-shot chain-of-thought prompting exhibits impressive personality recognition ability and is capable to provide natural language explanations through text-based logical reasoning. Furthermore, by employing the level-oriented prompting strategy to optimize zero-shot chain-of-thought prompting, the performance gap between ChatGPT and corresponding state-of-the-art model has been narrowed even more. However, we observe that ChatGPT shows unfairness towards certain sensitive demographic attributes such as gender and age. Additionally, we discover that eliciting the personality recognition ability of ChatGPT helps improve its performance on personality-related downstream tasks such as sentiment classification and stress prediction.