 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuiChat-CN: Benchmarking Contextual Suicide Risk Assessment in Chinese Group Chats
May 27, 2026Suicide is a critical global public health challenge, causing approximately 720,000 deaths each year and calling for timely, effective prevention strategies. Existing computational studies primarily focus on post-based social media platforms such as Twitter and Weibo, leaving instant messaging environments such as Telegram underexplored. Yet group chats pose distinct challenges: messages are short, fragmented, multi-party, and often rely on implicit or culturally specific expressions, making isolated post-level analysis insufficient. We introduce SuiChat-CN, a Chinese group-chat benchmark for contextual suicide risk assessment. We collect public Telegram group-chat data, construct coherent conversational segments through signal-word extraction and bidirectional context expansion, and annotate user risk levels with an expert-validated, LLM-assisted paradigm. SuiChat-CN contains 13,312 contextual segments from 1,406 users, covering 258,228 raw chat messages. Extensive experiments with PLMs and more than 40 LLMs demonstrate that contextual information is essential for reliable risk assessment, while fine-tuning and partial-context evaluation further reveal the challenges of early detection in multi-party conversations. Due to ethical and sensitivity concerns, the dataset is not publicly released but will be shared with accredited mental health and suicide-prevention research institutions upon reasonable request.
PLATONT: Learning a Platonic Representation for Unified Network Tomography
Nov 19, 2025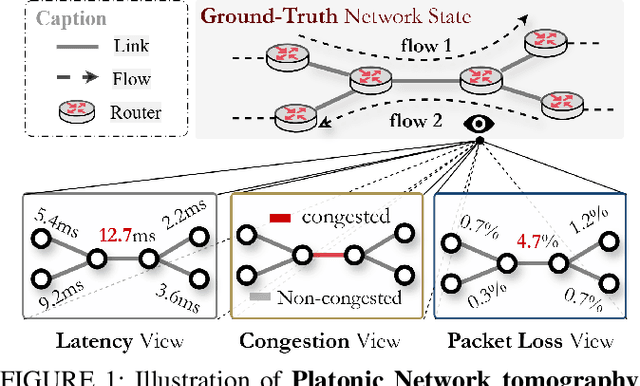
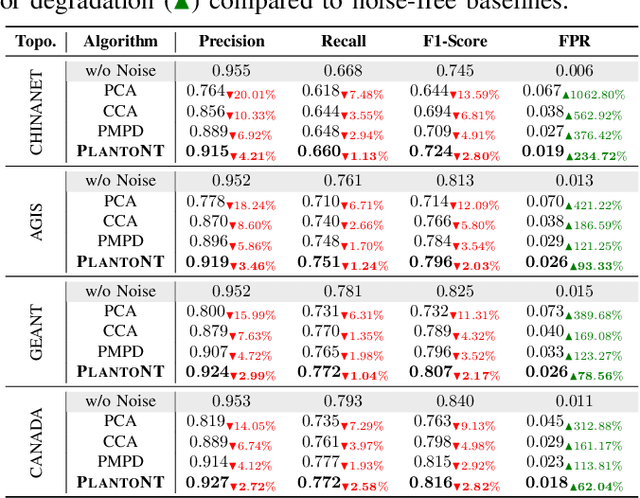
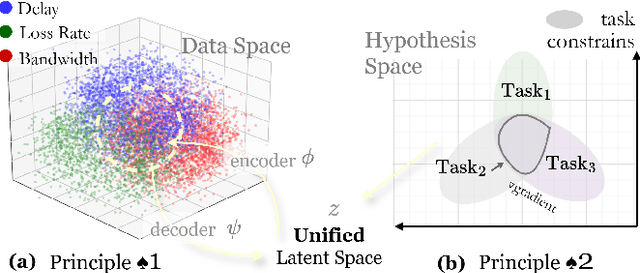
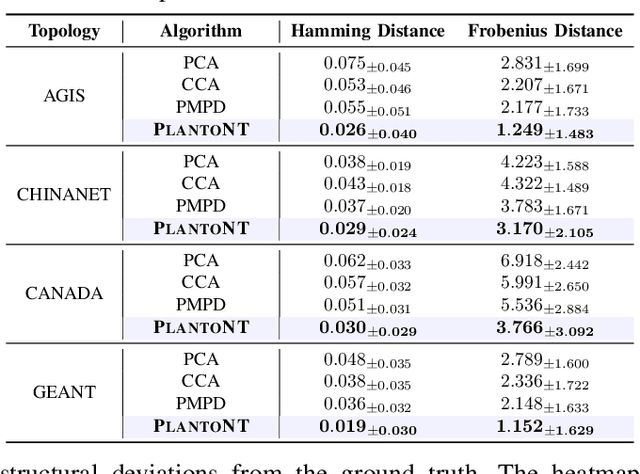
Network tomography aims to infer hidden network states, such as link performance, traffic load, and topology, from external observations. Most existing methods solve these problems separately and depend on limited task-specific signals, which limits generalization and interpretability. We present PLATONT, a unified framework that models different network indicators (e.g., delay, loss, bandwidth) as projections of a shared latent network state. Guided by the Platonic Representation Hypothesis, PLATONT learns this latent state through multimodal alignment and contrastive learning. By training multiple tomography tasks within a shared latent space, it builds compact and structured representations that improve cross-task generalization. Experiments on synthetic and real-world datasets show that PLATONT consistently outperforms existing methods in link estimation, topology inference, and traffic prediction, achieving higher accuracy and stronger robustness under varying network conditions.
Cross-Lingual Consistency: A Novel Inference Framework for Advancing Reasoning in Large Language Models
Apr 02, 2025Chain-of-thought (CoT) has emerged as a critical mechanism for enhancing reasoning capabilities in large language models (LLMs), with self-consistency demonstrating notable promise in boosting performance. However, inherent linguistic biases in multilingual training corpora frequently cause semantic drift and logical inconsistencies, especially in sub-10B parameter LLMs handling complex inference tasks. To overcome these constraints, we propose the Cross-Lingual Consistency (CLC) framework, an innovative inference paradigm that integrates multilingual reasoning paths through majority voting to elevate LLMs' reasoning capabilities. Empirical evaluations on the CMATH dataset reveal CLC's superiority over the conventional self-consistency method, delivering 9.5%, 6.5%, and 6.0% absolute accuracy gains for DeepSeek-Math-7B-Instruct, Qwen2.5-Math-7B-Instruct, and Gemma2-9B-Instruct respectively. Expanding CLC's linguistic scope to 11 diverse languages implies two synergistic benefits: 1) neutralizing linguistic biases in multilingual training corpora through multilingual ensemble voting, 2) escaping monolingual reasoning traps by exploring the broader multilingual solution space. This dual benefits empirically enables more globally optimal reasoning paths compared to monolingual self-consistency baselines, as evidenced by the 4.1%-18.5% accuracy gains using Gemma2-9B-Instruct on the MGSM dataset.
Unlocking Science: Novel Dataset and Benchmark for Cross-Modality Scientific Information Extraction
Nov 15, 2023Extracting key information from scientific papers has the potential to help researchers work more efficiently and accelerate the pace of scientific progress. Over the last few years, research on Scientific Information Extraction (SciIE) witnessed the release of several new systems and benchmarks. However, existing paper-focused datasets mostly focus only on specific parts of a manuscript (e.g., abstracts) and are single-modality (i.e., text- or table-only), due to complex processing and expensive annotations. Moreover, core information can be present in either text or tables or across both. To close this gap in data availability and enable cross-modality IE, while alleviating labeling costs, we propose a semi-supervised pipeline for annotating entities in text, as well as entities and relations in tables, in an iterative procedure. Based on this pipeline, we release novel resources for the scientific community, including a high-quality benchmark, a large-scale corpus, and a semi-supervised annotation pipeline. We further report the performance of state-of-the-art IE models on the proposed benchmark dataset, as a baseline. Lastly, we explore the potential capability of large language models such as ChatGPT for the current task. Our new dataset, results, and analysis validate the effectiveness and efficiency of our semi-supervised pipeline, and we discuss its remaining limitations.
Data Distribution Bottlenecks in Grounding Language Models to Knowledge Bases
Sep 15, 2023



Language models (LMs) have already demonstrated remarkable abilities in understanding and generating both natural and formal language. Despite these advances, their integration with real-world environments such as large-scale knowledge bases (KBs) remains an underdeveloped area, affecting applications such as semantic parsing and indulging in "hallucinated" information. This paper is an experimental investigation aimed at uncovering the robustness challenges that LMs encounter when tasked with knowledge base question answering (KBQA). The investigation covers scenarios with inconsistent data distribution between training and inference, such as generalization to unseen domains, adaptation to various language variations, and transferability across different datasets. Our comprehensive experiments reveal that even when employed with our proposed data augmentation techniques, advanced small and large language models exhibit poor performance in various dimensions. While the LM is a promising technology, the robustness of the current form in dealing with complex environments is fragile and of limited practicality because of the data distribution issue. This calls for future research on data collection and LM learning paradims.
Open-world Story Generation with Structured Knowledge Enhancement: A Comprehensive Survey
Dec 09, 2022



Storytelling and narrative are fundamental to human experience, intertwined with our social and cultural engagement. As such, researchers have long attempted to create systems that can generate stories automatically. In recent years, powered by deep learning and massive data resources, automatic story generation has shown significant advances. However, considerable challenges, like the need for global coherence in generated stories, still hamper generative models from reaching the same storytelling ability as human narrators. To tackle these challenges, many studies seek to inject structured knowledge into the generation process, which is referred to as structure knowledge-enhanced story generation. Incorporating external knowledge can enhance the logical coherence among story events, achieve better knowledge grounding, and alleviate over-generalization and repetition problems in stories. This survey provides the latest and comprehensive review of this research field: (i) we present a systematical taxonomy regarding how existing methods integrate structured knowledge into story generation; (ii) we summarize involved story corpora, structured knowledge datasets, and evaluation metrics; (iii) we give multidimensional insights into the challenges of knowledge-enhanced story generation and cast light on promising directions for future study.
TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Bases
Oct 24, 2022



Pre-trained language models (PLMs) have shown their effectiveness in multiple scenarios. However, KBQA remains challenging, especially regarding coverage and generalization settings. This is due to two main factors: i) understanding the semantics of both questions and relevant knowledge from the KB; ii) generating executable logical forms with both semantic and syntactic correctness. In this paper, we present a new KBQA model, TIARA, which addresses those issues by applying multi-grained retrieval to help the PLM focus on the most relevant KB contexts, viz., entities, exemplary logical forms, and schema items. Moreover, constrained decoding is used to control the output space and reduce generation errors. Experiments over important benchmarks demonstrate the effectiveness of our approach. TIARA outperforms previous SOTA, including those using PLMs or oracle entity annotations, by at least 4.1 and 1.1 F1 points on GrailQA and WebQuestionsSP, respectively.
Designs, Motion Mechanism, Motion Coordination, and Communication of Bionic Robot Fishes: A Survey
Jun 30, 2022
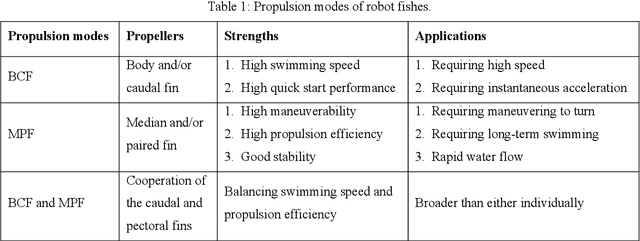

In the last few years, there have been many new developments and significant accomplishments in the research of bionic robot fishes. However, in terms of swimming performance, existing bionic robot fishes lag far behind fish, prompting researchers to constantly develop innovative designs of various bionic robot fishes. In this paper, the latest designs of robot fishes are presented in detail, distinguished by the propulsion mode. New robot fishes mainly include soft robot fishes and rigid-soft coupled robot fishes. The latest progress in the study of the swimming mechanism is analyzed on the basis of summarizing the main swimming theories of fish. The current state-of-the-art research in the new field of motion coordination and communication of multiple robot fishes is summarized. The general research trend in robot fishes is to utilize more efficient and robust methods to best mimic real fish while exhibiting superior swimming performance. The current challenges and potential future research directions are discussed. Various methods are needed to narrow the gap in swimming performance between robot fishes and fish. This paper is a first step to bring together roboticists and marine biologists interested in learning state-of-the-art research on bionic robot fishes.
Automated Chess Commentator Powered by Neural Chess Engine
Sep 23, 2019
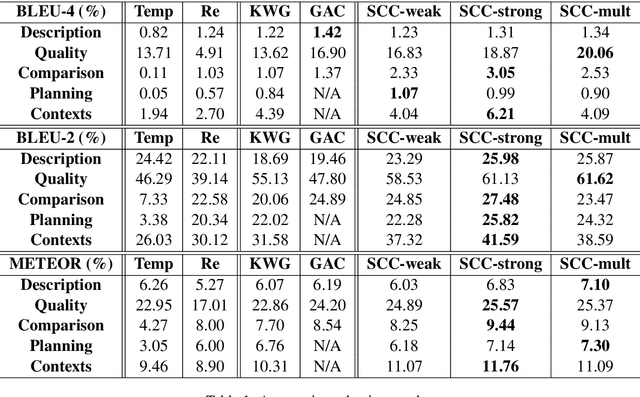
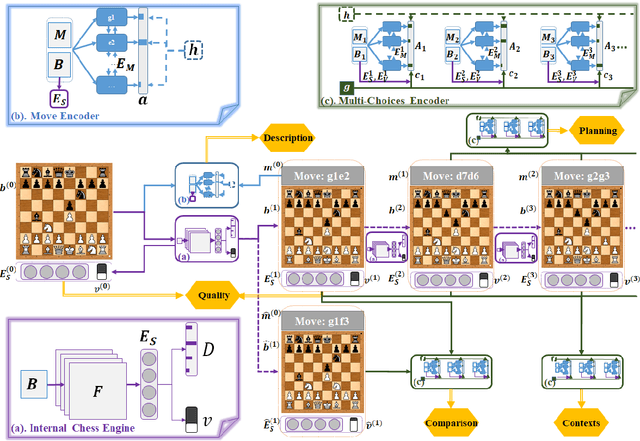

In this paper, we explore a new approach for automated chess commentary generation, which aims to generate chess commentary texts in different categories (e.g., description, comparison, planning, etc.). We introduce a neural chess engine into text generation models to help with encoding boards, predicting moves, and analyzing situations. By jointly training the neural chess engine and the generation models for different categories, the models become more effective. We conduct experiments on 5 categories in a benchmark Chess Commentary dataset and achieve inspiring results in both automatic and human evaluations.
A Neural Approach to Irony Generation
Sep 16, 2019
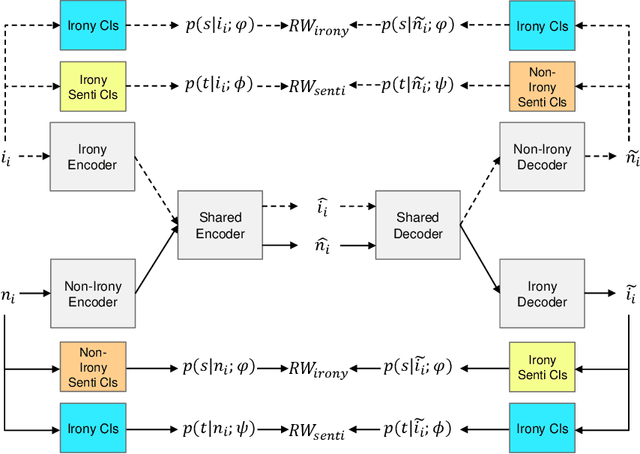
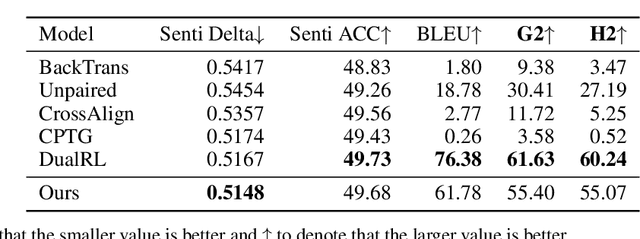
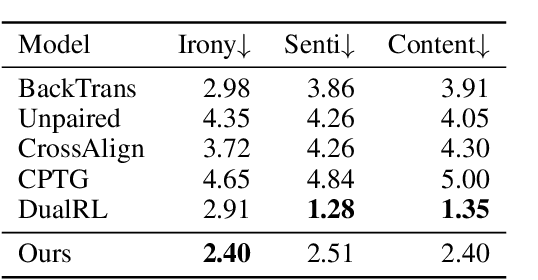
Ironies can not only express stronger emotions but also show a sense of humor. With the development of social media, ironies are widely used in public. Although many prior research studies have been conducted in irony detection, few studies focus on irony generation. The main challenges for irony generation are the lack of large-scale irony dataset and difficulties in modeling the ironic pattern. In this work, we first systematically define irony generation based on style transfer task. To address the lack of data, we make use of twitter and build a large-scale dataset. We also design a combination of rewards for reinforcement learning to control the generation of ironic sentences. Experimental results demonstrate the effectiveness of our model in terms of irony accuracy, sentiment preservation, and content preservation.