 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCE-RM: A Pointwise Generative Reward Model Optimized via Two-Stage Rollout and Unified Criteria
Jan 28, 2026Automatic evaluation is crucial yet challenging for open-ended natural language generation, especially when rule-based metrics are infeasible. Compared with traditional methods, the recent LLM-as-a-Judge paradigms enable better and more flexible evaluation, and show promise as generative reward models for reinforcement learning. However, prior work has revealed a notable gap between their seemingly impressive benchmark performance and actual effectiveness in RL practice. We attribute this issue to some limitations in existing studies, including the dominance of pairwise evaluation and inadequate optimization of evaluation criteria. Therefore, we propose CE-RM-4B, a pointwise generative reward model trained with a dedicated two-stage rollout method, and adopting unified query-based criteria. Using only about 5.7K high-quality data curated from the open-source preference dataset, our CE-RM-4B achieves superior performance on diverse reward model benchmarks, especially in Best-of-N scenarios, and delivers more effective improvements in downstream RL practice.
SCOPE: Intrinsic Semantic Space Control for Mitigating Copyright Infringement in LLMs
Nov 11, 2025Large language models sometimes inadvertently reproduce passages that are copyrighted, exposing downstream applications to legal risk. Most existing studies for inference-time defences focus on surface-level token matching and rely on external blocklists or filters, which add deployment complexity and may overlook semantically paraphrased leakage. In this work, we reframe copyright infringement mitigation as intrinsic semantic-space control and introduce SCOPE, an inference-time method that requires no parameter updates or auxiliary filters. Specifically, the sparse autoencoder (SAE) projects hidden states into a high-dimensional, near-monosemantic space; benefiting from this representation, we identify a copyright-sensitive subspace and clamp its activations during decoding. Experiments on widely recognized benchmarks show that SCOPE mitigates copyright infringement without degrading general utility. Further interpretability analyses confirm that the isolated subspace captures high-level semantics.
M$^{3}$T2IBench: A Large-Scale Multi-Category, Multi-Instance, Multi-Relation Text-to-Image Benchmark
Oct 27, 2025Text-to-image models are known to struggle with generating images that perfectly align with textual prompts. Several previous studies have focused on evaluating image-text alignment in text-to-image generation. However, these evaluations either address overly simple scenarios, especially overlooking the difficulty of prompts with multiple different instances belonging to the same category, or they introduce metrics that do not correlate well with human evaluation. In this study, we introduce M$^3$T2IBench, a large-scale, multi-category, multi-instance, multi-relation along with an object-detection-based evaluation metric, $AlignScore$, which aligns closely with human evaluation. Our findings reveal that current open-source text-to-image models perform poorly on this challenging benchmark. Additionally, we propose the Revise-Then-Enforce approach to enhance image-text alignment. This training-free post-editing method demonstrates improvements in image-text alignment across a broad range of diffusion models. \footnote{Our code and data has been released in supplementary material and will be made publicly available after the paper is accepted.}
UniAIDet: A Unified and Universal Benchmark for AI-Generated Image Content Detection and Localization
Oct 27, 2025With the rapid proliferation of image generative models, the authenticity of digital images has become a significant concern. While existing studies have proposed various methods for detecting AI-generated content, current benchmarks are limited in their coverage of diverse generative models and image categories, often overlooking end-to-end image editing and artistic images. To address these limitations, we introduce UniAIDet, a unified and comprehensive benchmark that includes both photographic and artistic images. UniAIDet covers a wide range of generative models, including text-to-image, image-to-image, image inpainting, image editing, and deepfake models. Using UniAIDet, we conduct a comprehensive evaluation of various detection methods and answer three key research questions regarding generalization capability and the relation between detection and localization. Our benchmark and analysis provide a robust foundation for future research.
HAD: HAllucination Detection Language Models Based on a Comprehensive Hallucination Taxonomy
Oct 22, 2025The increasing reliance on natural language generation (NLG) models, particularly large language models, has raised concerns about the reliability and accuracy of their outputs. A key challenge is hallucination, where models produce plausible but incorrect information. As a result, hallucination detection has become a critical task. In this work, we introduce a comprehensive hallucination taxonomy with 11 categories across various NLG tasks and propose the HAllucination Detection (HAD) models https://github.com/pku0xff/HAD, which integrate hallucination detection, span-level identification, and correction into a single inference process. Trained on an elaborate synthetic dataset of about 90K samples, our HAD models are versatile and can be applied to various NLG tasks. We also carefully annotate a test set for hallucination detection, called HADTest, which contains 2,248 samples. Evaluations on in-domain and out-of-domain test sets show that our HAD models generally outperform the existing baselines, achieving state-of-the-art results on HaluEval, FactCHD, and FaithBench, confirming their robustness and versatility.
JointCQ: Improving Factual Hallucination Detection with Joint Claim and Query Generation
Oct 22, 2025Current large language models (LLMs) often suffer from hallucination issues, i,e, generating content that appears factual but is actually unreliable. A typical hallucination detection pipeline involves response decomposition (i.e., claim extraction), query generation, evidence collection (i.e., search or retrieval), and claim verification. However, existing methods exhibit limitations in the first two stages, such as context loss during claim extraction and low specificity in query generation, resulting in degraded performance across the hallucination detection pipeline. In this work, we introduce JointCQ https://github.com/pku0xff/JointCQ, a joint claim-and-query generation framework designed to construct an effective and efficient claim-query generator. Our framework leverages elaborately designed evaluation criteria to filter synthesized training data, and finetunes a language model for joint claim extraction and query generation, providing reliable and informative inputs for downstream search and verification. Experimental results demonstrate that our method outperforms previous methods on multiple open-domain QA hallucination detection benchmarks, advancing the goal of more trustworthy and transparent language model systems.
Harnessing Rule-Based Reinforcement Learning for Enhanced Grammatical Error Correction
Aug 26, 2025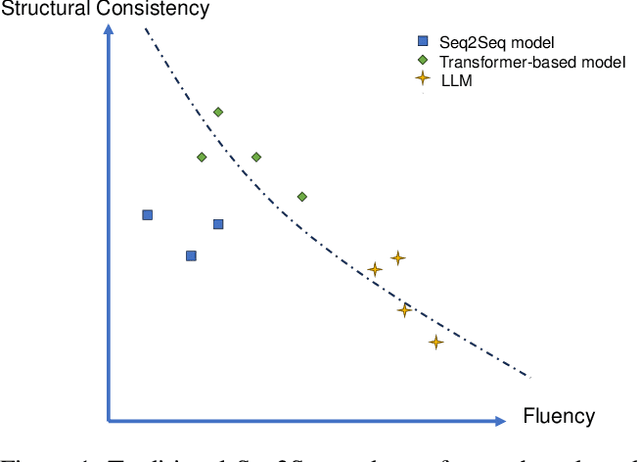

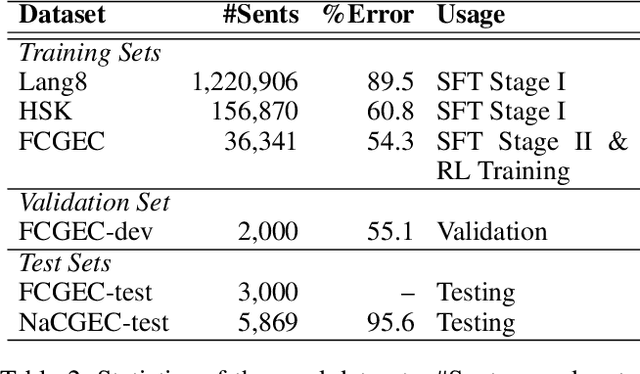

Grammatical error correction is a significant task in NLP. Traditional methods based on encoder-decoder models have achieved certain success, but the application of LLMs in this field is still underexplored. Current research predominantly relies on supervised fine-tuning to train LLMs to directly generate the corrected sentence, which limits the model's powerful reasoning ability. To address this limitation, we propose a novel framework based on Rule-Based RL. Through experiments on the Chinese datasets, our Rule-Based RL framework achieves \textbf{state-of-the-art }performance, with a notable increase in \textbf{recall}. This result clearly highlights the advantages of using RL to steer LLMs, offering a more controllable and reliable paradigm for future development in GEC.
Exploring Causal Effect of Social Bias on Faithfulness Hallucinations in Large Language Models
Aug 11, 2025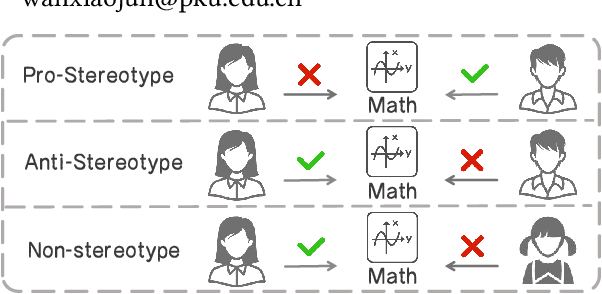



Large language models (LLMs) have achieved remarkable success in various tasks, yet they remain vulnerable to faithfulness hallucinations, where the output does not align with the input. In this study, we investigate whether social bias contributes to these hallucinations, a causal relationship that has not been explored. A key challenge is controlling confounders within the context, which complicates the isolation of causality between bias states and hallucinations. To address this, we utilize the Structural Causal Model (SCM) to establish and validate the causality and design bias interventions to control confounders. In addition, we develop the Bias Intervention Dataset (BID), which includes various social biases, enabling precise measurement of causal effects. Experiments on mainstream LLMs reveal that biases are significant causes of faithfulness hallucinations, and the effect of each bias state differs in direction. We further analyze the scope of these causal effects across various models, specifically focusing on unfairness hallucinations, which are primarily targeted by social bias, revealing the subtle yet significant causal effect of bias on hallucination generation.
ICR Probe: Tracking Hidden State Dynamics for Reliable Hallucination Detection in LLMs
Jul 22, 2025Large language models (LLMs) excel at various natural language processing tasks, but their tendency to generate hallucinations undermines their reliability. Existing hallucination detection methods leveraging hidden states predominantly focus on static and isolated representations, overlooking their dynamic evolution across layers, which limits efficacy. To address this limitation, we shift the focus to the hidden state update process and introduce a novel metric, the ICR Score (Information Contribution to Residual Stream), which quantifies the contribution of modules to the hidden states' update. We empirically validate that the ICR Score is effective and reliable in distinguishing hallucinations. Building on these insights, we propose a hallucination detection method, the ICR Probe, which captures the cross-layer evolution of hidden states. Experimental results show that the ICR Probe achieves superior performance with significantly fewer parameters. Furthermore, ablation studies and case analyses offer deeper insights into the underlying mechanism of this method, improving its interpretability.
LEDOM: An Open and Fundamental Reverse Language Model
Jul 02, 2025We introduce LEDOM, the first purely reverse language model, trained autoregressively on 435B tokens with 2B and 7B parameter variants, which processes sequences in reverse temporal order through previous token prediction. For the first time, we present the reverse language model as a potential foundational model across general tasks, accompanied by a set of intriguing examples and insights. Based on LEDOM, we further introduce a novel application: Reverse Reward, where LEDOM-guided reranking of forward language model outputs leads to substantial performance improvements on mathematical reasoning tasks. This approach leverages LEDOM's unique backward reasoning capability to refine generation quality through posterior evaluation. Our findings suggest that LEDOM exhibits unique characteristics with broad application potential. We will release all models, training code, and pre-training data to facilitate future research.