 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM$^{3}$T2IBench: A Large-Scale Multi-Category, Multi-Instance, Multi-Relation Text-to-Image Benchmark
Oct 27, 2025Text-to-image models are known to struggle with generating images that perfectly align with textual prompts. Several previous studies have focused on evaluating image-text alignment in text-to-image generation. However, these evaluations either address overly simple scenarios, especially overlooking the difficulty of prompts with multiple different instances belonging to the same category, or they introduce metrics that do not correlate well with human evaluation. In this study, we introduce M$^3$T2IBench, a large-scale, multi-category, multi-instance, multi-relation along with an object-detection-based evaluation metric, $AlignScore$, which aligns closely with human evaluation. Our findings reveal that current open-source text-to-image models perform poorly on this challenging benchmark. Additionally, we propose the Revise-Then-Enforce approach to enhance image-text alignment. This training-free post-editing method demonstrates improvements in image-text alignment across a broad range of diffusion models. \footnote{Our code and data has been released in supplementary material and will be made publicly available after the paper is accepted.}
UniAIDet: A Unified and Universal Benchmark for AI-Generated Image Content Detection and Localization
Oct 27, 2025With the rapid proliferation of image generative models, the authenticity of digital images has become a significant concern. While existing studies have proposed various methods for detecting AI-generated content, current benchmarks are limited in their coverage of diverse generative models and image categories, often overlooking end-to-end image editing and artistic images. To address these limitations, we introduce UniAIDet, a unified and comprehensive benchmark that includes both photographic and artistic images. UniAIDet covers a wide range of generative models, including text-to-image, image-to-image, image inpainting, image editing, and deepfake models. Using UniAIDet, we conduct a comprehensive evaluation of various detection methods and answer three key research questions regarding generalization capability and the relation between detection and localization. Our benchmark and analysis provide a robust foundation for future research.
JointCQ: Improving Factual Hallucination Detection with Joint Claim and Query Generation
Oct 22, 2025Current large language models (LLMs) often suffer from hallucination issues, i,e, generating content that appears factual but is actually unreliable. A typical hallucination detection pipeline involves response decomposition (i.e., claim extraction), query generation, evidence collection (i.e., search or retrieval), and claim verification. However, existing methods exhibit limitations in the first two stages, such as context loss during claim extraction and low specificity in query generation, resulting in degraded performance across the hallucination detection pipeline. In this work, we introduce JointCQ https://github.com/pku0xff/JointCQ, a joint claim-and-query generation framework designed to construct an effective and efficient claim-query generator. Our framework leverages elaborately designed evaluation criteria to filter synthesized training data, and finetunes a language model for joint claim extraction and query generation, providing reliable and informative inputs for downstream search and verification. Experimental results demonstrate that our method outperforms previous methods on multiple open-domain QA hallucination detection benchmarks, advancing the goal of more trustworthy and transparent language model systems.
ICR Probe: Tracking Hidden State Dynamics for Reliable Hallucination Detection in LLMs
Jul 22, 2025Large language models (LLMs) excel at various natural language processing tasks, but their tendency to generate hallucinations undermines their reliability. Existing hallucination detection methods leveraging hidden states predominantly focus on static and isolated representations, overlooking their dynamic evolution across layers, which limits efficacy. To address this limitation, we shift the focus to the hidden state update process and introduce a novel metric, the ICR Score (Information Contribution to Residual Stream), which quantifies the contribution of modules to the hidden states' update. We empirically validate that the ICR Score is effective and reliable in distinguishing hallucinations. Building on these insights, we propose a hallucination detection method, the ICR Probe, which captures the cross-layer evolution of hidden states. Experimental results show that the ICR Probe achieves superior performance with significantly fewer parameters. Furthermore, ablation studies and case analyses offer deeper insights into the underlying mechanism of this method, improving its interpretability.
How Much To Guide: Revisiting Adaptive Guidance in Classifier-Free Guidance Text-to-Vision Diffusion Models
Jun 10, 2025With the rapid development of text-to-vision generation diffusion models, classifier-free guidance has emerged as the most prevalent method for conditioning. However, this approach inherently requires twice as many steps for model forwarding compared to unconditional generation, resulting in significantly higher costs. While previous study has introduced the concept of adaptive guidance, it lacks solid analysis and empirical results, making previous method unable to be applied to general diffusion models. In this work, we present another perspective of applying adaptive guidance and propose Step AG, which is a simple, universally applicable adaptive guidance strategy. Our evaluations focus on both image quality and image-text alignment. whose results indicate that restricting classifier-free guidance to the first several denoising steps is sufficient for generating high-quality, well-conditioned images, achieving an average speedup of 20% to 30%. Such improvement is consistent across different settings such as inference steps, and various models including video generation models, highlighting the superiority of our method.
Re-Thinking the Automatic Evaluation of Image-Text Alignment in Text-to-Image Models
Jun 10, 2025Text-to-image models often struggle to generate images that precisely match textual prompts. Prior research has extensively studied the evaluation of image-text alignment in text-to-image generation. However, existing evaluations primarily focus on agreement with human assessments, neglecting other critical properties of a trustworthy evaluation framework. In this work, we first identify two key aspects that a reliable evaluation should address. We then empirically demonstrate that current mainstream evaluation frameworks fail to fully satisfy these properties across a diverse range of metrics and models. Finally, we propose recommendations for improving image-text alignment evaluation.
C-FAITH: A Chinese Fine-Grained Benchmark for Automated Hallucination Evaluation
Apr 14, 2025Despite the rapid advancement of large language models, they remain highly susceptible to generating hallucinations, which significantly hinders their widespread application. Hallucination research requires dynamic and fine-grained evaluation. However, most existing hallucination benchmarks (especially in Chinese language) rely on human annotations, making automatical and cost-effective hallucination evaluation challenging. To address this, we introduce HaluAgent, an agentic framework that automatically constructs fine-grained QA dataset based on some knowledge documents. Our experiments demonstrate that the manually designed rules and prompt optimization can improve the quality of generated data. Using HaluAgent, we construct C-FAITH, a Chinese QA hallucination benchmark created from 1,399 knowledge documents obtained from web scraping, totaling 60,702 entries. We comprehensively evaluate 16 mainstream LLMs with our proposed C-FAITH, providing detailed experimental results and analysis.
PaCoST: Paired Confidence Significance Testing for Benchmark Contamination Detection in Large Language Models
Jun 26, 2024Large language models (LLMs) are known to be trained on vast amounts of data, which may unintentionally or intentionally include data from commonly used benchmarks. This inclusion can lead to cheatingly high scores on model leaderboards, yet result in disappointing performance in real-world applications. To address this benchmark contamination problem, we first propose a set of requirements that practical contamination detection methods should follow. Following these proposed requirements, we introduce PaCoST, a Paired Confidence Significance Testing to effectively detect benchmark contamination in LLMs. Our method constructs a counterpart for each piece of data with the same distribution, and performs statistical analysis of the corresponding confidence to test whether the model is significantly more confident under the original benchmark. We validate the effectiveness of PaCoST and apply it on popular open-source models and benchmarks. We find that almost all models and benchmarks we tested are suspected contaminated more or less. We finally call for new LLM evaluation methods.
MC-MKE: A Fine-Grained Multimodal Knowledge Editing Benchmark Emphasizing Modality Consistency
Jun 19, 2024



Multimodal large language models (MLLMs) are prone to non-factual or outdated knowledge issues, which can manifest as misreading and misrecognition errors due to the complexity of multimodal knowledge. Previous benchmarks have not systematically analyzed the performance of editing methods in correcting these two error types. To better represent and correct these errors, we decompose multimodal knowledge into its visual and textual components. Different error types correspond to different editing formats, which edits distinct part of the multimodal knowledge. We present MC-MKE, a fine-grained Multimodal Knowledge Editing benchmark emphasizing Modality Consistency. Our benchmark facilitates independent correction of misreading and misrecognition errors by editing the corresponding knowledge component. We evaluate three multimodal knowledge editing methods on MC-MKE, revealing their limitations, particularly in terms of modality consistency. Our work highlights the challenges posed by multimodal knowledge editing and motivates further research in developing effective techniques for this task.
Evaluating and Mitigating Number Hallucinations in Large Vision-Language Models: A Consistency Perspective
Mar 03, 2024
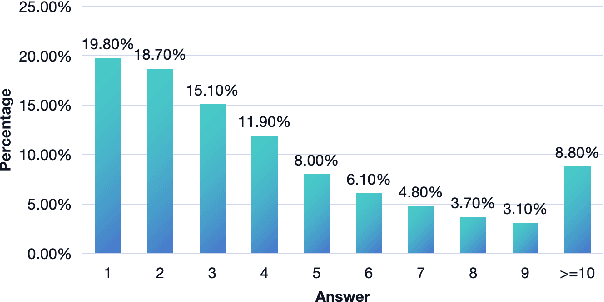
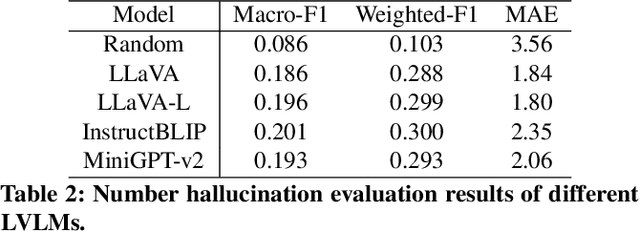
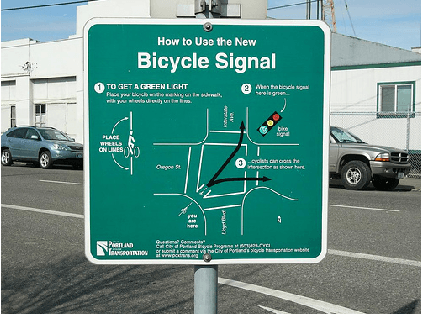
Large vision language models have demonstrated remarkable efficacy in addressing challenges related to both textual and visual content. Nevertheless, these models are susceptible to various hallucinations. In this paper, we focus on a new form of hallucination, specifically termed as number hallucination, which denotes instances where models fail to accurately identify the quantity of objects in an image. We establish a dataset and employ evaluation metrics to assess number hallucination, revealing a pronounced prevalence of this issue across mainstream large vision language models (LVLMs). Additionally, we delve into a thorough analysis of number hallucination, examining inner and outer inconsistency problem from two related perspectives. We assert that this inconsistency is one cause of number hallucination and propose a consistency training method as a means to alleviate such hallucination, which achieves an average improvement of 8\% compared with direct finetuning method.