 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Mitigating Number Hallucinations in Large Vision-Language Models: A Consistency Perspective
Paper and Code
Mar 03, 2024
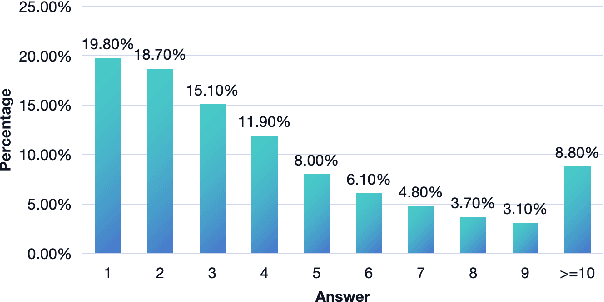
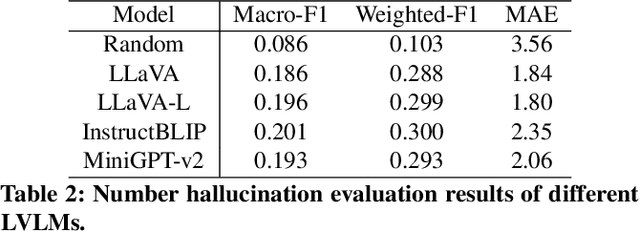
Large vision language models have demonstrated remarkable efficacy in addressing challenges related to both textual and visual content. Nevertheless, these models are susceptible to various hallucinations. In this paper, we focus on a new form of hallucination, specifically termed as number hallucination, which denotes instances where models fail to accurately identify the quantity of objects in an image. We establish a dataset and employ evaluation metrics to assess number hallucination, revealing a pronounced prevalence of this issue across mainstream large vision language models (LVLMs). Additionally, we delve into a thorough analysis of number hallucination, examining inner and outer inconsistency problem from two related perspectives. We assert that this inconsistency is one cause of number hallucination and propose a consistency training method as a means to alleviate such hallucination, which achieves an average improvement of 8\% compared with direct finetuning method.