 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausal Flow Q-Learning for Robust Offline Reinforcement Learning
Feb 02, 2026Expressive policies based on flow-matching have been successfully applied in reinforcement learning (RL) more recently due to their ability to model complex action distributions from offline data. These algorithms build on standard policy gradients, which assume that there is no unmeasured confounding in the data. However, this condition does not necessarily hold for pixel-based demonstrations when a mismatch exists between the demonstrator's and the learner's sensory capabilities, leading to implicit confounding biases in offline data. We address the challenge by investigating the problem of confounded observations in offline RL from a causal perspective. We develop a novel causal offline RL objective that optimizes policies' worst-case performance that may arise due to confounding biases. Based on this new objective, we introduce a practical implementation that learns expressive flow-matching policies from confounded demonstrations, employing a deep discriminator to assess the discrepancy between the target policy and the nominal behavioral policy. Experiments across 25 pixel-based tasks demonstrate that our proposed confounding-robust augmentation procedure achieves a success rate 120\% that of confounding-unaware, state-of-the-art offline RL methods.
Causal discovery for linear causal model with correlated noise: an Adversarial Learning Approach
Jan 04, 2026Causal discovery from data with unmeasured confounding factors is a challenging problem. This paper proposes an approach based on the f-GAN framework, learning the binary causal structure independent of specific weight values. We reformulate the structure learning problem as minimizing Bayesian free energy and prove that this problem is equivalent to minimizing the f-divergence between the true data distribution and the model-generated distribution. Using the f-GAN framework, we transform this objective into a min-max adversarial optimization problem. We implement the gradient search in the discrete graph space using Gumbel-Softmax relaxation.
YODA: Yet Another One-step Diffusion-based Video Compressor
Jan 03, 2026While one-step diffusion models have recently excelled in perceptual image compression, their application to video remains limited. Prior efforts typically rely on pretrained 2D autoencoders that generate per-frame latent representations independently, thereby neglecting temporal dependencies. We present YODA--Yet Another One-step Diffusion-based Video Compressor--which embeds multiscale features from temporal references for both latent generation and latent coding to better exploit spatial-temporal correlations for more compact representation, and employs a linear Diffusion Transformer (DiT) for efficient one-step denoising. YODA achieves state-of-the-art perceptual performance, consistently outperforming traditional and deep-learning baselines on LPIPS, DISTS, FID, and KID. Source code will be publicly available at https://github.com/NJUVISION/YODA.
Exploring Causal Effect of Social Bias on Faithfulness Hallucinations in Large Language Models
Aug 11, 2025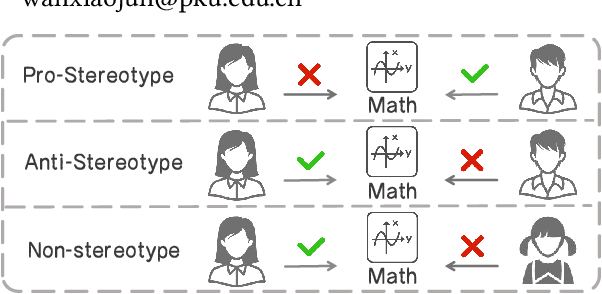



Large language models (LLMs) have achieved remarkable success in various tasks, yet they remain vulnerable to faithfulness hallucinations, where the output does not align with the input. In this study, we investigate whether social bias contributes to these hallucinations, a causal relationship that has not been explored. A key challenge is controlling confounders within the context, which complicates the isolation of causality between bias states and hallucinations. To address this, we utilize the Structural Causal Model (SCM) to establish and validate the causality and design bias interventions to control confounders. In addition, we develop the Bias Intervention Dataset (BID), which includes various social biases, enabling precise measurement of causal effects. Experiments on mainstream LLMs reveal that biases are significant causes of faithfulness hallucinations, and the effect of each bias state differs in direction. We further analyze the scope of these causal effects across various models, specifically focusing on unfairness hallucinations, which are primarily targeted by social bias, revealing the subtle yet significant causal effect of bias on hallucination generation.
ICR Probe: Tracking Hidden State Dynamics for Reliable Hallucination Detection in LLMs
Jul 22, 2025Large language models (LLMs) excel at various natural language processing tasks, but their tendency to generate hallucinations undermines their reliability. Existing hallucination detection methods leveraging hidden states predominantly focus on static and isolated representations, overlooking their dynamic evolution across layers, which limits efficacy. To address this limitation, we shift the focus to the hidden state update process and introduce a novel metric, the ICR Score (Information Contribution to Residual Stream), which quantifies the contribution of modules to the hidden states' update. We empirically validate that the ICR Score is effective and reliable in distinguishing hallucinations. Building on these insights, we propose a hallucination detection method, the ICR Probe, which captures the cross-layer evolution of hidden states. Experimental results show that the ICR Probe achieves superior performance with significantly fewer parameters. Furthermore, ablation studies and case analyses offer deeper insights into the underlying mechanism of this method, improving its interpretability.
How Much To Guide: Revisiting Adaptive Guidance in Classifier-Free Guidance Text-to-Vision Diffusion Models
Jun 10, 2025With the rapid development of text-to-vision generation diffusion models, classifier-free guidance has emerged as the most prevalent method for conditioning. However, this approach inherently requires twice as many steps for model forwarding compared to unconditional generation, resulting in significantly higher costs. While previous study has introduced the concept of adaptive guidance, it lacks solid analysis and empirical results, making previous method unable to be applied to general diffusion models. In this work, we present another perspective of applying adaptive guidance and propose Step AG, which is a simple, universally applicable adaptive guidance strategy. Our evaluations focus on both image quality and image-text alignment. whose results indicate that restricting classifier-free guidance to the first several denoising steps is sufficient for generating high-quality, well-conditioned images, achieving an average speedup of 20% to 30%. Such improvement is consistent across different settings such as inference steps, and various models including video generation models, highlighting the superiority of our method.
Selftok: Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 18, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
Automatic Reward Shaping from Confounded Offline Data
May 16, 2025A key task in Artificial Intelligence is learning effective policies for controlling agents in unknown environments to optimize performance measures. Off-policy learning methods, like Q-learning, allow learners to make optimal decisions based on past experiences. This paper studies off-policy learning from biased data in complex and high-dimensional domains where \emph{unobserved confounding} cannot be ruled out a priori. Building on the well-celebrated Deep Q-Network (DQN), we propose a novel deep reinforcement learning algorithm robust to confounding biases in observed data. Specifically, our algorithm attempts to find a safe policy for the worst-case environment compatible with the observations. We apply our method to twelve confounded Atari games, and find that it consistently dominates the standard DQN in all games where the observed input to the behavioral and target policies mismatch and unobserved confounders exist.
Discrete Visual Tokens of Autoregression, by Diffusion, and for Reasoning
May 12, 2025We completely discard the conventional spatial prior in image representation and introduce a novel discrete visual tokenizer: Self-consistency Tokenizer (Selftok). At its design core, we compose an autoregressive (AR) prior -- mirroring the causal structure of language -- into visual tokens by using the reverse diffusion process of image generation. The AR property makes Selftok fundamentally distinct from traditional spatial tokens in the following two key ways: - Selftok offers an elegant and minimalist approach to unify diffusion and AR for vision-language models (VLMs): By representing images with Selftok tokens, we can train a VLM using a purely discrete autoregressive architecture -- like that in LLMs -- without requiring additional modules or training objectives. - We theoretically show that the AR prior satisfies the Bellman equation, whereas the spatial prior does not. Therefore, Selftok supports reinforcement learning (RL) for visual generation with effectiveness comparable to that achieved in LLMs. Besides the AR property, Selftok is also a SoTA tokenizer that achieves a favorable trade-off between high-quality reconstruction and compression rate. We use Selftok to build a pure AR VLM for both visual comprehension and generation tasks. Impressively, without using any text-image training pairs, a simple policy gradient RL working in the visual tokens can significantly boost the visual generation benchmark, surpassing all the existing models by a large margin. Therefore, we believe that Selftok effectively addresses the long-standing challenge that visual tokens cannot support effective RL. When combined with the well-established strengths of RL in LLMs, this brings us one step closer to realizing a truly multimodal LLM. Project Page: https://selftok-team.github.io/report/.
C-FAITH: A Chinese Fine-Grained Benchmark for Automated Hallucination Evaluation
Apr 14, 2025Despite the rapid advancement of large language models, they remain highly susceptible to generating hallucinations, which significantly hinders their widespread application. Hallucination research requires dynamic and fine-grained evaluation. However, most existing hallucination benchmarks (especially in Chinese language) rely on human annotations, making automatical and cost-effective hallucination evaluation challenging. To address this, we introduce HaluAgent, an agentic framework that automatically constructs fine-grained QA dataset based on some knowledge documents. Our experiments demonstrate that the manually designed rules and prompt optimization can improve the quality of generated data. Using HaluAgent, we construct C-FAITH, a Chinese QA hallucination benchmark created from 1,399 knowledge documents obtained from web scraping, totaling 60,702 entries. We comprehensively evaluate 16 mainstream LLMs with our proposed C-FAITH, providing detailed experimental results and analysis.