 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadBEV: An Efficient Quadruple-Task Perception Framework via Bird's-Eye-View Representation
Oct 09, 2024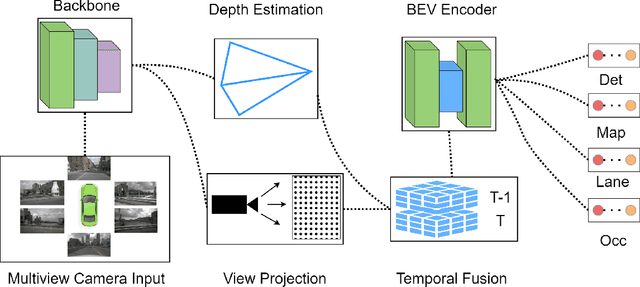
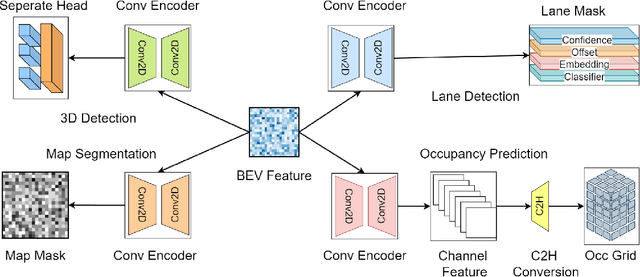
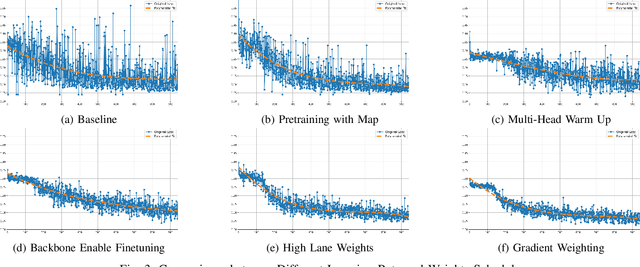
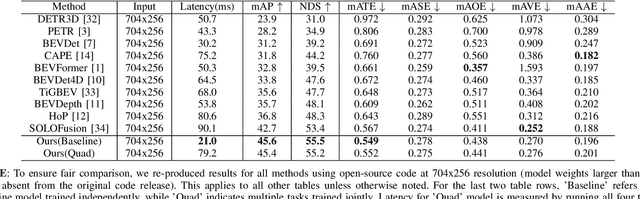
Bird's-Eye-View (BEV) perception has become a vital component of autonomous driving systems due to its ability to integrate multiple sensor inputs into a unified representation, enhancing performance in various downstream tasks. However, the computational demands of BEV models pose challenges for real-world deployment in vehicles with limited resources. To address these limitations, we propose QuadBEV, an efficient multitask perception framework that leverages the shared spatial and contextual information across four key tasks: 3D object detection, lane detection, map segmentation, and occupancy prediction. QuadBEV not only streamlines the integration of these tasks using a shared backbone and task-specific heads but also addresses common multitask learning challenges such as learning rate sensitivity and conflicting task objectives. Our framework reduces redundant computations, thereby enhancing system efficiency, making it particularly suited for embedded systems. We present comprehensive experiments that validate the effectiveness and robustness of QuadBEV, demonstrating its suitability for real-world applications.
Learning Content-Aware Multi-Modal Joint Input Pruning via Bird's-Eye-View Representation
Oct 09, 2024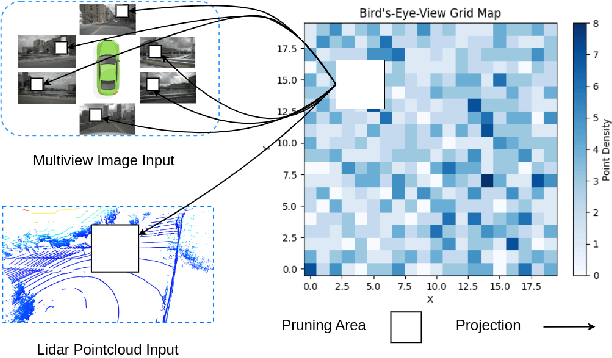
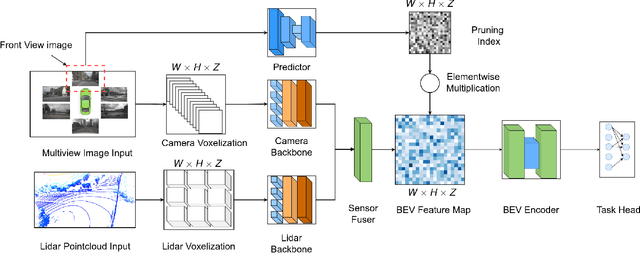
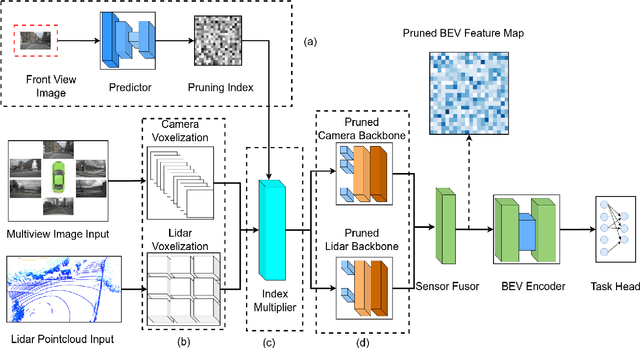
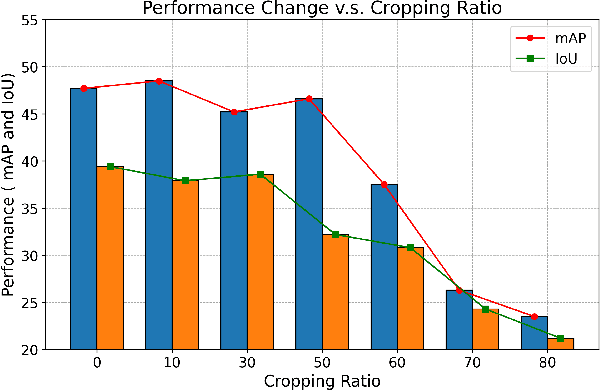
In the landscape of autonomous driving, Bird's-Eye-View (BEV) representation has recently garnered substantial academic attention, serving as a transformative framework for the fusion of multi-modal sensor inputs. This BEV paradigm effectively shifts the sensor fusion challenge from a rule-based methodology to a data-centric approach, thereby facilitating more nuanced feature extraction from an array of heterogeneous sensors. Notwithstanding its evident merits, the computational overhead associated with BEV-based techniques often mandates high-capacity hardware infrastructures, thus posing challenges for practical, real-world implementations. To mitigate this limitation, we introduce a novel content-aware multi-modal joint input pruning technique. Our method leverages BEV as a shared anchor to algorithmically identify and eliminate non-essential sensor regions prior to their introduction into the perception model's backbone. We validatethe efficacy of our approach through extensive experiments on the NuScenes dataset, demonstrating substantial computational efficiency without sacrificing perception accuracy. To the best of our knowledge, this work represents the first attempt to alleviate the computational burden from the input pruning point.
Transferability of Representations Learned using Supervised Contrastive Learning Trained on a Multi-Domain Dataset
Sep 27, 2023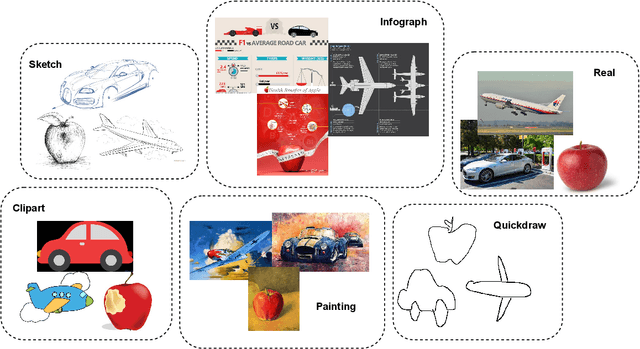
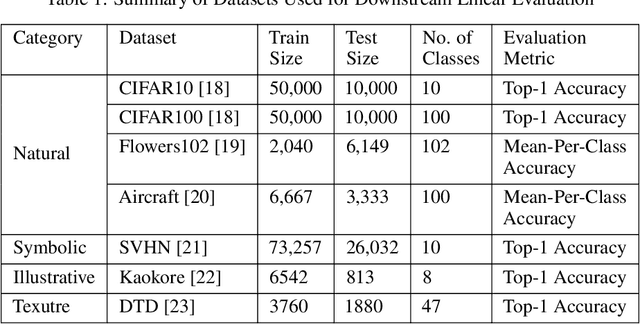
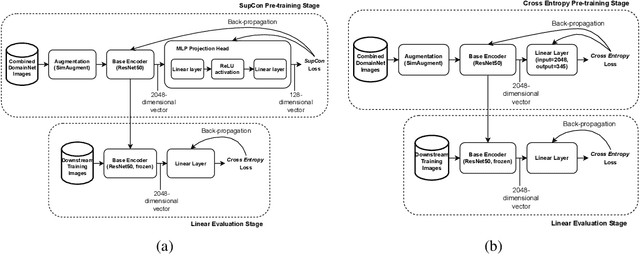

Contrastive learning has shown to learn better quality representations than models trained using cross-entropy loss. They also transfer better to downstream datasets from different domains. However, little work has been done to explore the transferability of representations learned using contrastive learning when trained on a multi-domain dataset. In this paper, a study has been conducted using the Supervised Contrastive Learning framework to learn representations from the multi-domain DomainNet dataset and then evaluate the transferability of the representations learned on other downstream datasets. The fixed feature linear evaluation protocol will be used to evaluate the transferability on 7 downstream datasets that were chosen across different domains. The results obtained are compared to a baseline model that was trained using the widely used cross-entropy loss. Empirical results from the experiments showed that on average, the Supervised Contrastive Learning model performed 6.05% better than the baseline model on the 7 downstream datasets. The findings suggest that Supervised Contrastive Learning models can potentially learn more robust representations that transfer better across domains than cross-entropy models when trained on a multi-domain dataset.
DeformToon3D: Deformable 3D Toonification from Neural Radiance Fields
Sep 08, 2023



In this paper, we address the challenging problem of 3D toonification, which involves transferring the style of an artistic domain onto a target 3D face with stylized geometry and texture. Although fine-tuning a pre-trained 3D GAN on the artistic domain can produce reasonable performance, this strategy has limitations in the 3D domain. In particular, fine-tuning can deteriorate the original GAN latent space, which affects subsequent semantic editing, and requires independent optimization and storage for each new style, limiting flexibility and efficient deployment. To overcome these challenges, we propose DeformToon3D, an effective toonification framework tailored for hierarchical 3D GAN. Our approach decomposes 3D toonification into subproblems of geometry and texture stylization to better preserve the original latent space. Specifically, we devise a novel StyleField that predicts conditional 3D deformation to align a real-space NeRF to the style space for geometry stylization. Thanks to the StyleField formulation, which already handles geometry stylization well, texture stylization can be achieved conveniently via adaptive style mixing that injects information of the artistic domain into the decoder of the pre-trained 3D GAN. Due to the unique design, our method enables flexible style degree control and shape-texture-specific style swap. Furthermore, we achieve efficient training without any real-world 2D-3D training pairs but proxy samples synthesized from off-the-shelf 2D toonification models.
Abductive Action Inference
Oct 24, 2022



Abductive reasoning aims to make the most likely inference for a given set of incomplete observations. In this work, given a situation or a scenario, we aim to answer the question 'what is the set of actions that were executed by the human in order to come to this current state?', which we coin as abductive action inference. We provide a solution based on the human-object relations and their states in the given scene. Specifically, we first detect objects and humans in the scene, and then generate representations for each human-centric relation. Using these human-centric relations, we derive the most likely set of actions the human may have executed to arrive in this state. To generate human-centric relational representations, we investigate several models such as Transformers, a novel graph neural network-based encoder-decoder, and a new relational bilinear pooling method. We obtain promising results using these new models on this challenging task on the Action Genome dataset.
Monocular 3D Object Reconstruction with GAN Inversion
Jul 20, 2022
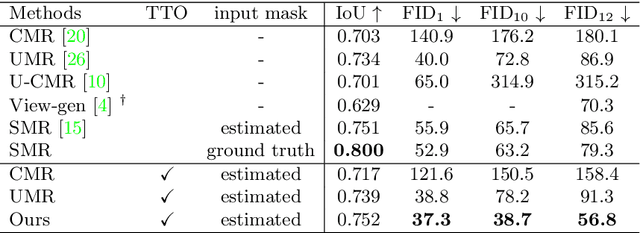
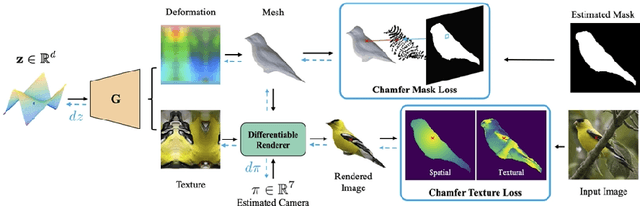

Recovering a textured 3D mesh from a monocular image is highly challenging, particularly for in-the-wild objects that lack 3D ground truths. In this work, we present MeshInversion, a novel framework to improve the reconstruction by exploiting the generative prior of a 3D GAN pre-trained for 3D textured mesh synthesis. Reconstruction is achieved by searching for a latent space in the 3D GAN that best resembles the target mesh in accordance with the single view observation. Since the pre-trained GAN encapsulates rich 3D semantics in terms of mesh geometry and texture, searching within the GAN manifold thus naturally regularizes the realness and fidelity of the reconstruction. Importantly, such regularization is directly applied in the 3D space, providing crucial guidance of mesh parts that are unobserved in the 2D space. Experiments on standard benchmarks show that our framework obtains faithful 3D reconstructions with consistent geometry and texture across both observed and unobserved parts. Moreover, it generalizes well to meshes that are less commonly seen, such as the extended articulation of deformable objects. Code is released at https://github.com/junzhezhang/mesh-inversion
NSGZero: Efficiently Learning Non-Exploitable Policy in Large-Scale Network Security Games with Neural Monte Carlo Tree Search
Jan 17, 2022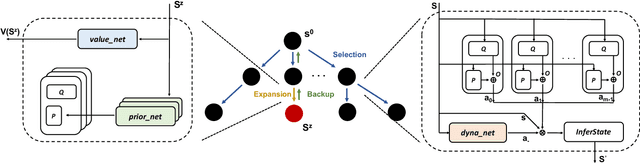

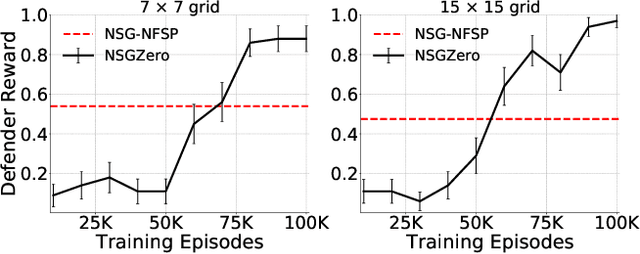
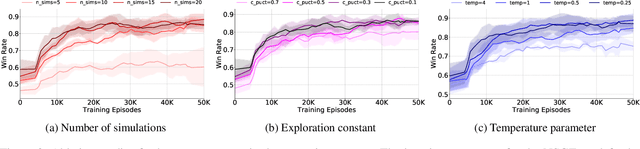
How resources are deployed to secure critical targets in networks can be modelled by Network Security Games (NSGs). While recent advances in deep learning (DL) provide a powerful approach to dealing with large-scale NSGs, DL methods such as NSG-NFSP suffer from the problem of data inefficiency. Furthermore, due to centralized control, they cannot scale to scenarios with a large number of resources. In this paper, we propose a novel DL-based method, NSGZero, to learn a non-exploitable policy in NSGs. NSGZero improves data efficiency by performing planning with neural Monte Carlo Tree Search (MCTS). Our main contributions are threefold. First, we design deep neural networks (DNNs) to perform neural MCTS in NSGs. Second, we enable neural MCTS with decentralized control, making NSGZero applicable to NSGs with many resources. Third, we provide an efficient learning paradigm, to achieve joint training of the DNNs in NSGZero. Compared to state-of-the-art algorithms, our method achieves significantly better data efficiency and scalability.
Mis-spoke or mis-lead: Achieving Robustness in Multi-Agent Communicative Reinforcement Learning
Aug 09, 2021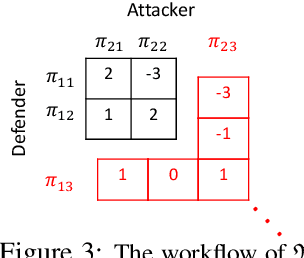
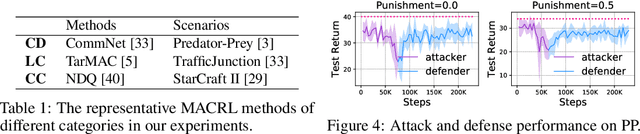
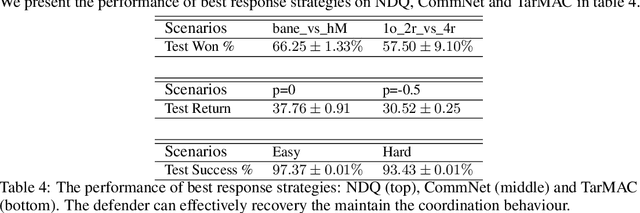

Recent studies in multi-agent communicative reinforcement learning (MACRL) demonstrate that multi-agent coordination can be significantly improved when communication between agents is allowed. Meanwhile, advances in adversarial machine learning (ML) have shown that ML and reinforcement learning (RL) models are vulnerable to a variety of attacks that significantly degrade the performance of learned behaviours. However, despite the obvious and growing importance, the combination of adversarial ML and MACRL remains largely uninvestigated. In this paper, we make the first step towards conducting message attacks on MACRL methods. In our formulation, one agent in the cooperating group is taken over by an adversary and can send malicious messages to disrupt a deployed MACRL-based coordinated strategy during the deployment phase. We further our study by developing a defence method via message reconstruction. Finally, we address the resulting arms race, i.e., we consider the ability of the malicious agent to adapt to the changing and improving defensive communicative policies of the benign agents. Specifically, we model the adversarial MACRL problem as a two-player zero-sum game and then utilize Policy-Space Response Oracle to achieve communication robustness. Empirically, we demonstrate that MACRL methods are vulnerable to message attacks while our defence method the game-theoretic framework can effectively improve the robustness of MACRL.
Solving Large-Scale Extensive-Form Network Security Games via Neural Fictitious Self-Play
Jun 02, 2021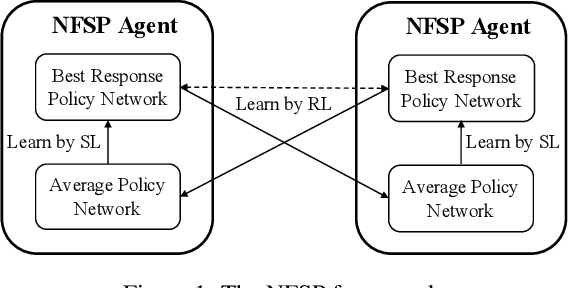
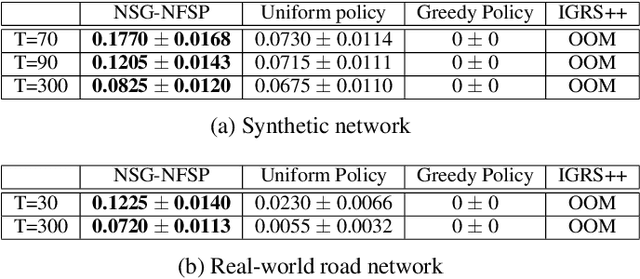
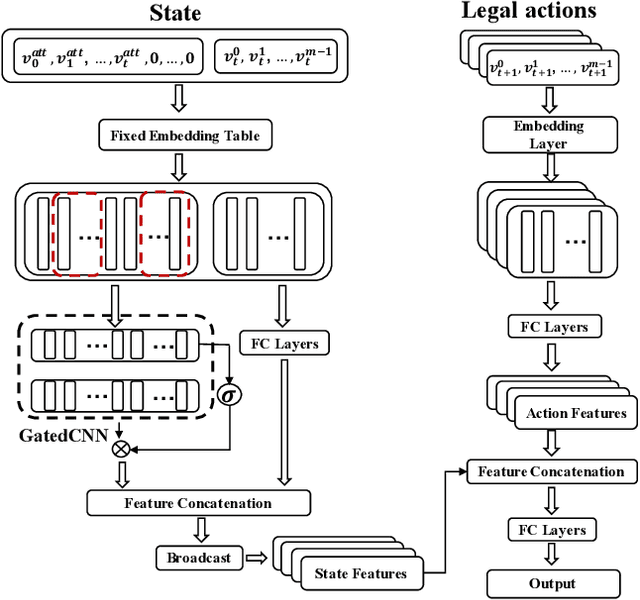

Securing networked infrastructures is important in the real world. The problem of deploying security resources to protect against an attacker in networked domains can be modeled as Network Security Games (NSGs). Unfortunately, existing approaches, including the deep learning-based approaches, are inefficient to solve large-scale extensive-form NSGs. In this paper, we propose a novel learning paradigm, NSG-NFSP, to solve large-scale extensive-form NSGs based on Neural Fictitious Self-Play (NFSP). Our main contributions include: i) reforming the best response (BR) policy network in NFSP to be a mapping from action-state pair to action-value, to make the calculation of BR possible in NSGs; ii) converting the average policy network of an NFSP agent into a metric-based classifier, helping the agent to assign distributions only on legal actions rather than all actions; iii) enabling NFSP with high-level actions, which can benefit training efficiency and stability in NSGs; and iv) leveraging information contained in graphs of NSGs by learning efficient graph node embeddings. Our algorithm significantly outperforms state-of-the-art algorithms in both scalability and solution quality.
Unsupervised 3D Shape Completion through GAN Inversion
Apr 29, 2021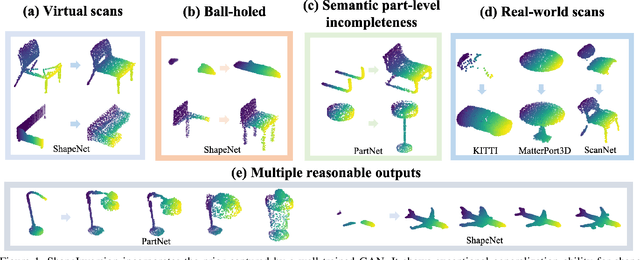
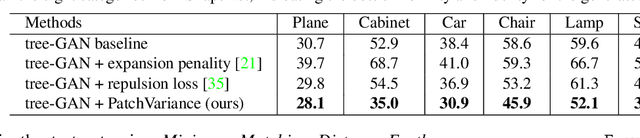


Most 3D shape completion approaches rely heavily on partial-complete shape pairs and learn in a fully supervised manner. Despite their impressive performances on in-domain data, when generalizing to partial shapes in other forms or real-world partial scans, they often obtain unsatisfactory results due to domain gaps. In contrast to previous fully supervised approaches, in this paper we present ShapeInversion, which introduces Generative Adversarial Network (GAN) inversion to shape completion for the first time. ShapeInversion uses a GAN pre-trained on complete shapes by searching for a latent code that gives a complete shape that best reconstructs the given partial input. In this way, ShapeInversion no longer needs paired training data, and is capable of incorporating the rich prior captured in a well-trained generative model. On the ShapeNet benchmark, the proposed ShapeInversion outperforms the SOTA unsupervised method, and is comparable with supervised methods that are learned using paired data. It also demonstrates remarkable generalization ability, giving robust results for real-world scans and partial inputs of various forms and incompleteness levels. Importantly, ShapeInversion naturally enables a series of additional abilities thanks to the involvement of a pre-trained GAN, such as producing multiple valid complete shapes for an ambiguous partial input, as well as shape manipulation and interpolation.