 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSenseNova-U1: Unifying Multimodal Understanding and Generation with NEO-unify Architecture
May 12, 2026Recent large vision-language models (VLMs) remain fundamentally constrained by a persistent dichotomy: understanding and generation are treated as distinct problems, leading to fragmented architectures, cascaded pipelines, and misaligned representation spaces. We argue that this divide is not merely an engineering artifact, but a structural limitation that hinders the emergence of native multimodal intelligence. Hence, we introduce SenseNova-U1, a native unified multimodal paradigm built upon NEO-unify, in which understanding and generation evolve as synergistic views of a single underlying process. We launch two native unified variants, SenseNova-U1-8B-MoT and SenseNova-U1-A3B-MoT, built on dense (8B) and mixture-of-experts (30B-A3B) understanding baselines, respectively. Designed from first principles, they rival top-tier understanding-only VLMs across text understanding, vision-language perception, knowledge reasoning, agentic decision-making, and spatial intelligence. Meanwhile, they deliver strong semantic consistency and visual fidelity, excelling in conventional or knowledge-intensive any-to-image (X2I) synthesis, complex text-rich infographic generation, and interleaved vision-language generation, with or without think patterns. Beyond performance, we show detailed model design, data preprocessing, pre-/post-training, and inference strategies to support community research. Last but not least, preliminary evidence demonstrates that our models extend beyond perception and generation, performing strongly in vision-language-action (VLA) and world model (WM) scenarios. This points toward a broader roadmap where models do not translate between modalities, but think and act across them in a native manner. Multimodal AI is no longer about connecting separate systems, but about building a unified one and trusting the necessary capabilities to emerge from within.
MEDN: Motion-Emotion Feature Decoupling Network for Micro-Expression Recognition
Apr 20, 2026Unlike macro-expression, micro-expression does not follow a strictly consistent mapping rule between emotions and Action Units (AUs). As a result, some micro-expressions share identical AUs yet represent completely opposite emotional categories, making them highly visually similar. Existing microexpression recognition (MER) methods mostly rely on explicit facial motion cues (e.g., optical flow, frame differences, AU features) while ignoring implicit emotion information. To tackle this issue, this paper presents a Motion Emotion Feature Decoupling Network (MEDN) for MER. We design a dual-branch framework to separately extract motion and emotion features. In the motion branch, an AU-detection task restricts features to the explicit motion domain, and orthogonal loss is adopted to reduce motion emotion feature coupling. For implicit emotion modeling, we propose a Sparse Emotion Vision Transformer (SEVit) that sparsifies spatial tokens to highlight local temporal variations with multi-scale sparsity rates. A Collaborative Fusion Module (CoFM) is further developed to fuse disentangled motion and emotion features adaptively. Extensive experiments on three benchmark datasets validate that MEDN effectively decouples motion and emotion features and achieves superior recognition performance, offering a new perspective for enhancing recognition accuracy and generalization.
ProVG: Progressive Visual Grounding via Language Decoupling for Remote Sensing Imagery
Apr 02, 2026Remote sensing visual grounding (RSVG) aims to localize objects in remote sensing imagery according to natural language expressions. Previous methods typically rely on sentence-level vision-language alignment, which struggles to exploit fine-grained linguistic cues, such as \textit{spatial relations} and \textit{object attributes}, that are crucial for distinguishing objects with similar characteristics. Importantly, these cues play distinct roles across different grounding stages and should be leveraged accordingly to provide more explicit guidance. In this work, we propose \textbf{ProVG}, a novel RSVG framework that improves localization accuracy by decoupling language expressions into global context, spatial relations, and object attributes. To integrate these linguistic cues, ProVG employs a simple yet effective progressive cross-modal modulator, which dynamically modulates visual attention through a \textit{survey-locate-verify} scheme, enabling coarse-to-fine vision-language alignment. In addition, ProVG incorporates a cross-scale fusion module to mitigate the large-scale variations in remote sensing imagery, along with a language-guided calibration decoder to refine cross-modal alignment during prediction. A unified multi-task head further enables ProVG to support both referring expression comprehension and segmentation tasks. Extensive experiments on two benchmarks, \textit{i.e.}, RRSIS-D and RISBench, demonstrate that ProVG consistently outperforms existing methods, achieving new state-of-the-art performance.
FB-CLIP: Fine-Grained Zero-Shot Anomaly Detection with Foreground-Background Disentanglement
Mar 20, 2026Fine-grained anomaly detection is crucial in industrial and medical applications, but labeled anomalies are often scarce, making zero-shot detection challenging. While vision-language models like CLIP offer promising solutions, they struggle with foreground-background feature entanglement and coarse textual semantics. We propose FB-CLIP, a framework that enhances anomaly localization via multi-strategy textual representations and foreground-background separation. In the textual modality, it combines End-of-Text features, global-pooled representations, and attention-weighted token features for richer semantic cues. In the visual modality, multi-view soft separation along identity, semantic, and spatial dimensions, together with background suppression, reduces interference and improves discriminability. Semantic Consistency Regularization (SCR) aligns image features with normal and abnormal textual prototypes, suppressing uncertain matches and enlarging semantic gaps. Experiments show that FB-CLIP effectively distinguishes anomalies from complex backgrounds, achieving accurate fine-grained anomaly detection and localization under zero-shot settings.
Improving Few-Shot Change Detection Visual Question Answering via Decision-Ambiguity-guided Reinforcement Fine-Tuning
Dec 31, 2025Change detection visual question answering (CDVQA) requires answering text queries by reasoning about semantic changes in bi-temporal remote sensing images. A straightforward approach is to boost CDVQA performance with generic vision-language models via supervised fine-tuning (SFT). Despite recent progress, we observe that a significant portion of failures do not stem from clearly incorrect predictions, but from decision ambiguity, where the model assigns similar confidence to the correct answer and strong distractors. To formalize this challenge, we define Decision-Ambiguous Samples (DAS) as instances with a small probability margin between the ground-truth answer and the most competitive alternative. We argue that explicitly optimizing DAS is crucial for improving the discriminability and robustness of CDVQA models. To this end, we propose DARFT, a Decision-Ambiguity-guided Reinforcement Fine-Tuning framework that first mines DAS using an SFT-trained reference policy and then applies group-relative policy optimization on the mined subset. By leveraging multi-sample decoding and intra-group relative advantages, DARFT suppresses strong distractors and sharpens decision boundaries without additional supervision. Extensive experiments demonstrate consistent gains over SFT baselines, particularly under few-shot settings.
The Prism Hypothesis: Harmonizing Semantic and Pixel Representations via Unified Autoencoding
Dec 22, 2025Deep representations across modalities are inherently intertwined. In this paper, we systematically analyze the spectral characteristics of various semantic and pixel encoders. Interestingly, our study uncovers a highly inspiring and rarely explored correspondence between an encoder's feature spectrum and its functional role: semantic encoders primarily capture low-frequency components that encode abstract meaning, whereas pixel encoders additionally retain high-frequency information that conveys fine-grained detail. This heuristic finding offers a unifying perspective that ties encoder behavior to its underlying spectral structure. We define it as the Prism Hypothesis, where each data modality can be viewed as a projection of the natural world onto a shared feature spectrum, just like the prism. Building on this insight, we propose Unified Autoencoding (UAE), a model that harmonizes semantic structure and pixel details via an innovative frequency-band modulator, enabling their seamless coexistence. Extensive experiments on ImageNet and MS-COCO benchmarks validate that our UAE effectively unifies semantic abstraction and pixel-level fidelity into a single latent space with state-of-the-art performance.
CheXPO-v2: Preference Optimization for Chest X-ray VLMs with Knowledge Graph Consistency
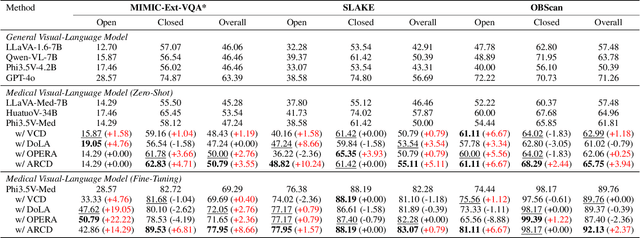
Dec 19, 2025Medical Vision-Language Models (VLMs) are prone to hallucinations, compromising clinical reliability. While reinforcement learning methods like Group Relative Policy Optimization (GRPO) offer a low-cost alignment solution, their reliance on sparse, outcome-based rewards inadvertently encourages models to "overthink" -- generating verbose, convoluted, and unverifiable Chain-of-Thought reasoning to justify answers. This focus on outcomes obscures factual errors and poses significant safety risks. To address this, we propose CheXPO-v2, a novel alignment framework that shifts from outcome to process supervision. Our core innovation is a Knowledge Graph Consistency Reward mechanism driven by Entity-Relation Matching. By explicitly parsing reasoning steps into structured "Disease, Relation, Anatomy" triplets, we provide fine-grained supervision that penalizes incoherent logic and hallucinations at the atomic level. Integrating this with a hard-example mining strategy, our approach significantly outperforms GRPO and state-of-the-art models on benchmarks like MIMIC-CXR-VQA. Crucially, CheXPO-v2 achieves new state-of-the-art accuracy using only 5k samples, demonstrating exceptional data efficiency while producing clinically sound and verifiable reasoning. The project source code is publicly available at: https://github.com/ecoxial2007/CheX-Phi4MM.
Anatomical Region-Guided Contrastive Decoding: A Plug-and-Play Strategy for Mitigating Hallucinations in Medical VLMs
Dec 19, 2025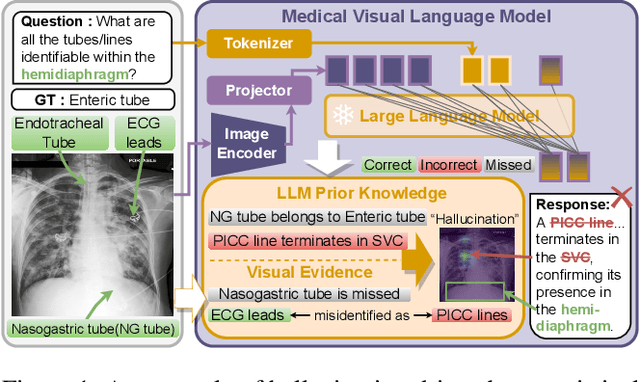
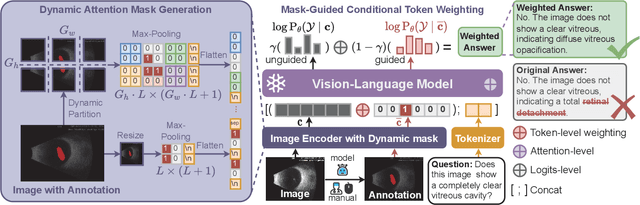

Medical Vision-Language Models (MedVLMs) show immense promise in clinical applicability. However, their reliability is hindered by hallucinations, where models often fail to derive answers from visual evidence, instead relying on learned textual priors. Existing mitigation strategies for MedVLMs have distinct limitations: training-based methods rely on costly expert annotations, limiting scalability, while training-free interventions like contrastive decoding, though data-efficient, apply a global, untargeted correction whose effects in complex real-world clinical settings can be unreliable. To address these challenges, we introduce Anatomical Region-Guided Contrastive Decoding (ARCD), a plug-and-play strategy that mitigates hallucinations by providing targeted, region-specific guidance. Our module leverages an anatomical mask to direct a three-tiered contrastive decoding process. By dynamically re-weighting at the token, attention, and logits levels, it verifiably steers the model's focus onto specified regions, reinforcing anatomical understanding and suppressing factually incorrect outputs. Extensive experiments across diverse datasets, including chest X-ray, CT, brain MRI, and ocular ultrasound, demonstrate our method's effectiveness in improving regional understanding, reducing hallucinations, and enhancing overall diagnostic accuracy.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
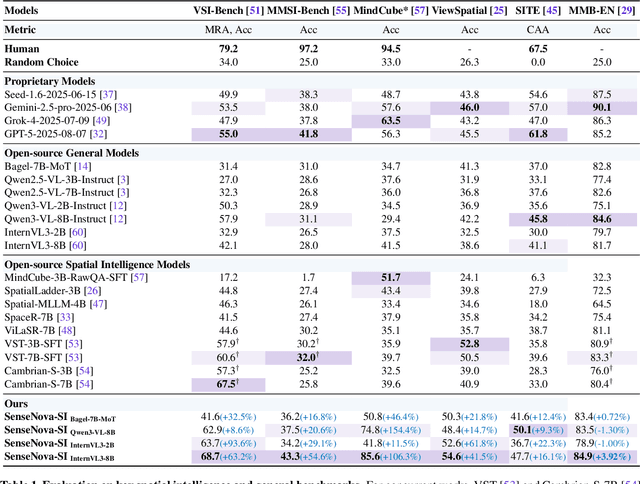


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
In-Token Rationality Optimization: Towards Accurate and Concise LLM Reasoning via Self-Feedback
Nov 13, 2025Training Large Language Models (LLMs) for chain-of-thought reasoning presents a significant challenge: supervised fine-tuning on a single "golden" rationale hurts generalization as it penalizes equally valid alternatives, whereas reinforcement learning with verifiable rewards struggles with credit assignment and prohibitive computational cost. To tackle these limitations, we introduce InTRO (In-Token Rationality Optimization), a new framework that enables both token-level exploration and self-feedback for accurate and concise reasoning. Instead of directly optimizing an intractable objective over all valid reasoning paths, InTRO leverages correction factors-token-wise importance weights estimated by the information discrepancy between the generative policy and its answer-conditioned counterpart, for informative next token selection. This approach allows the model to perform token-level exploration and receive self-generated feedback within a single forward pass, ultimately encouraging accurate and concise rationales. Across six math-reasoning benchmarks, InTRO consistently outperforms other baselines, raising solution accuracy by up to 20% relative to the base model. Its chains of thought are also notably more concise, exhibiting reduced verbosity. Beyond this, InTRO enables cross-domain transfer, successfully adapting to out-of-domain reasoning tasks that extend beyond the realm of mathematics, demonstrating robust generalization.