 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemember with Confidence: Uncertainty Quantification for Spatio-temporal Memory with Probabilistic Guarantees
Jun 06, 2026Long-horizon robot operation requires spatio-temporal memory to record the environment state and recall it for downstream reasoning. Scene graphs and retrieval-augmented systems ground VLM descriptions to persistent 3D entities with rich semantic descriptions. However, VLM captions are noisy and viewpoint-inconsistent, and existing systems treat them as an oracle with no mechanism to detect unreliable stored descriptions. We introduce object-level semantic uncertainty for multi-view VLM memory: a score that measures object-centric cross-view semantic scatter of captions and identifies semantically unresolved objects. Then, we include our uncertainty scores in an advanced spatial-semantic memory system, that we dub UQ-DAAAM. UQ-DAAAM uses this score to actively refine uncertain objects under a fixed query budget by selecting high-quality views and fusing the resulting multi-view captions into a single object description. We also derive probabilistic guarantees showing that higher-quality candidate views (as selected by our approach) are more likely to reduce uncertainty. Our experiments show that uncertainty quantification can make embodied 4D memory systems more reliable and more effective. In particular, on the OC-NaVQA benchmark, UQ-DAAAM achieves substantially larger uncertainty reduction and better spatio-temporal question answering performance than baselines.
Chrono-Gymnasium: An Open-Source, Gymnasium-Compatible Distributed Simulation Framework
May 14, 2026High-fidelity physics simulation is essential for closing the sim-to-real gap in robotics and complex mechanical systems. However, the computational overhead of high-fidelity engines often limits their use in data-intensive tasks like Reinforcement Learning (RL) and global optimization. We introduce Chrono-Gymnasium, a distributed computing framework that scales the high-fidelity multi-body dynamics of Project Chrono across large-scale computing clusters. Built upon the Ray framework, Chrono-Gymnasium provides a standardized Gymnasium interface, enabling seamless integration with modern machine learning libraries while providing built-in synchronization and messaging primitives for distributed execution. We demonstrate the framework's capabilities through two distinct case studies: (1) the training of an RL agent for autonomous robotic navigation in complex terrains, and (2) the Bayesian Optimization of a planetary lander's design parameters to ensure landing stability. Our results show that Chrono-Gymnasium reduces wall-clock time for high-fidelity simulations without sacrificing physical accuracy, offering a scalable path for the design and control of complex robotic systems.
State-of-the-Art Dysarthric Speech Recognition with MetaICL for on-the-fly Personalization
Sep 19, 2025Personalizing Automatic Speech Recognition (ASR) for dysarthric speech is crucial but challenging due to training and storing of individual user adapters. We propose a hybrid meta-training method for a single model, excelling in zero-shot and few-shot on-the-fly personalization via in-context learning (ICL). Measuring Word Error Rate (WER) on state-of-the-art subsets, the model achieves 13.9% WER on Euphonia which surpasses speaker-independent baselines (17.5% WER) and rivals user-specific personalized models. On SAP Test 1, its 5.3% WER significantly bests the 8% from even personalized adapters. We also demonstrate the importance of example curation, where an oracle text-similarity method shows 5 curated examples can achieve performance similar to 19 randomly selected ones, highlighting a key area for future efficiency gains. Finally, we conduct data ablations to measure the data efficiency of this approach. This work presents a practical, scalable, and personalized solution.
GraphemeAug: A Systematic Approach to Synthesized Hard Negative Keyword Spotting Examples
May 20, 2025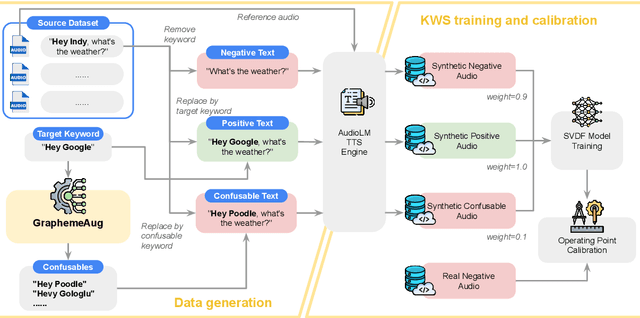

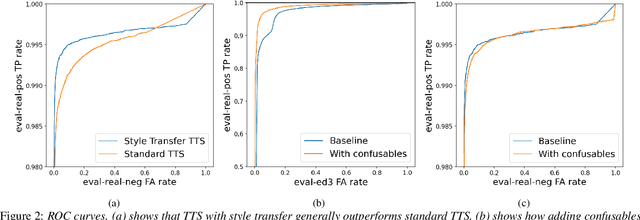

Spoken Keyword Spotting (KWS) is the task of distinguishing between the presence and absence of a keyword in audio. The accuracy of a KWS model hinges on its ability to correctly classify examples close to the keyword and non-keyword boundary. These boundary examples are often scarce in training data, limiting model performance. In this paper, we propose a method to systematically generate adversarial examples close to the decision boundary by making insertion/deletion/substitution edits on the keyword's graphemes. We evaluate this technique on held-out data for a popular keyword and show that the technique improves AUC on a dataset of synthetic hard negatives by 61% while maintaining quality on positives and ambient negative audio data.
ChronoLLM: A Framework for Customizing Large Language Model for Digital Twins generalization based on PyChrono
Jan 07, 2025
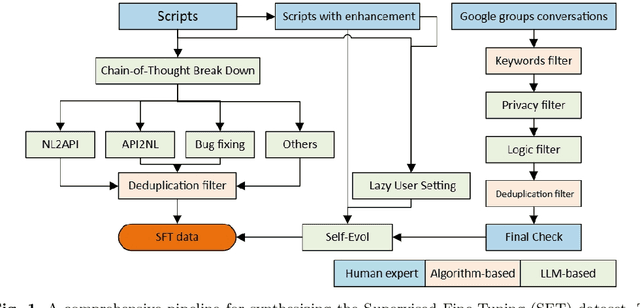

Recently, the integration of advanced simulation technologies with artificial intelligence (AI) is revolutionizing science and engineering research. ChronoLlama introduces a novel framework that customizes the open-source LLMs, specifically for code generation, paired with PyChrono for multi-physics simulations. This integration aims to automate and improve the creation of simulation scripts, thus enhancing model accuracy and efficiency. This combination harnesses the speed of AI-driven code generation with the reliability of physics-based simulations, providing a powerful tool for researchers and engineers. Empirical results indicate substantial enhancements in simulation setup speed, accuracy of the generated codes, and overall computational efficiency. ChronoLlama not only expedites the development and testing of multibody systems but also spearheads a scalable, AI-enhanced approach to managing intricate mechanical simulations. This pioneering integration of cutting-edge AI with traditional simulation platforms represents a significant leap forward in automating and optimizing design processes in engineering applications.
CUPS: Improving Human Pose-Shape Estimators with Conformalized Deep Uncertainty
Dec 11, 2024We introduce CUPS, a novel method for learning sequence-to-sequence 3D human shapes and poses from RGB videos with uncertainty quantification. To improve on top of prior work, we develop a method to generate and score multiple hypotheses during training, effectively integrating uncertainty quantification into the learning process. This process results in a deep uncertainty function that is trained end-to-end with the 3D pose estimator. Post-training, the learned deep uncertainty model is used as the conformity score, which can be used to calibrate a conformal predictor in order to assess the quality of the output prediction. Since the data in human pose-shape learning is not fully exchangeable, we also present two practical bounds for the coverage gap in conformal prediction, developing theoretical backing for the uncertainty bound of our model. Our results indicate that by taking advantage of deep uncertainty with conformal prediction, our method achieves state-of-the-art performance across various metrics and datasets while inheriting the probabilistic guarantees of conformal prediction.
CRISP: Object Pose and Shape Estimation with Test-Time Adaptation
Dec 02, 2024

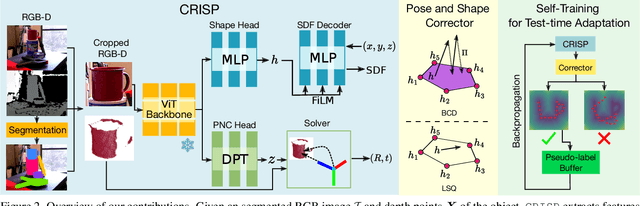

We consider the problem of estimating object pose and shape from an RGB-D image. Our first contribution is to introduce CRISP, a category-agnostic object pose and shape estimation pipeline. The pipeline implements an encoder-decoder model for shape estimation. It uses FiLM-conditioning for implicit shape reconstruction and a DPT-based network for estimating pose-normalized points for pose estimation. As a second contribution, we propose an optimization-based pose and shape corrector that can correct estimation errors caused by a domain gap. Observing that the shape decoder is well behaved in the convex hull of known shapes, we approximate the shape decoder with an active shape model, and show that this reduces the shape correction problem to a constrained linear least squares problem, which can be solved efficiently by an interior point algorithm. Third, we introduce a self-training pipeline to perform self-supervised domain adaptation of CRISP. The self-training is based on a correct-and-certify approach, which leverages the corrector to generate pseudo-labels at test time, and uses them to self-train CRISP. We demonstrate CRISP (and the self-training) on YCBV, SPE3R, and NOCS datasets. CRISP shows high performance on all the datasets. Moreover, our self-training is capable of bridging a large domain gap. Finally, CRISP also shows an ability to generalize to unseen objects. Code and pre-trained models will be available on https://web.mit.edu/sparklab/research/crisp_object_pose_shape/.
A physics-based sensor simulation environment for lunar ground operations
Oct 06, 2024This contribution reports on a software framework that uses physically-based rendering to simulate camera operation in lunar conditions. The focus is on generating synthetic images qualitatively similar to those produced by an actual camera operating on a vehicle traversing and/or actively interacting with lunar terrain, e.g., for construction operations. The highlights of this simulator are its ability to capture (i) light transport in lunar conditions and (ii) artifacts related to the vehicle-terrain interaction, which might include dust formation and transport. The simulation infrastructure is built within an in-house developed physics engine called Chrono, which simulates the dynamics of the deformable terrain-vehicle interaction, as well as fallout of this interaction. The Chrono::Sensor camera model draws on ray tracing and Hapke Photometric Functions. We analyze the performance of the simulator using two virtual experiments featuring digital twins of NASA's VIPER rover navigating a lunar environment, and of the NASA's RASSOR excavator engaged into a digging operation. The sensor simulation solution presented can be used for the design and testing of perception algorithms, or as a component of in-silico experiments that pertain to large lunar operations, e.g., traversability, construction tasks.
Enhancing Autonomous Navigation by Imaging Hidden Objects using Single-Photon LiDAR
Oct 04, 2024



Robust autonomous navigation in environments with limited visibility remains a critical challenge in robotics. We present a novel approach that leverages Non-Line-of-Sight (NLOS) sensing using single-photon LiDAR to improve visibility and enhance autonomous navigation. Our method enables mobile robots to "see around corners" by utilizing multi-bounce light information, effectively expanding their perceptual range without additional infrastructure. We propose a three-module pipeline: (1) Sensing, which captures multi-bounce histograms using SPAD-based LiDAR; (2) Perception, which estimates occupancy maps of hidden regions from these histograms using a convolutional neural network; and (3) Control, which allows a robot to follow safe paths based on the estimated occupancy. We evaluate our approach through simulations and real-world experiments on a mobile robot navigating an L-shaped corridor with hidden obstacles. Our work represents the first experimental demonstration of NLOS imaging for autonomous navigation, paving the way for safer and more efficient robotic systems operating in complex environments. We also contribute a novel dynamics-integrated transient rendering framework for simulating NLOS scenarios, facilitating future research in this domain.
SimBench: A Rule-Based Multi-Turn Interaction Benchmark for Evaluating an LLM's Ability to Generate Digital Twins
Aug 21, 2024We introduce SimBench, a benchmark designed to evaluate the proficiency of student large language models (S-LLMs) in generating digital twins (DTs) that can be used in simulators for virtual testing. Given a collection of S-LLMs, this benchmark enables the ranking of the S-LLMs based on their ability to produce high-quality DTs. We demonstrate this by comparing over 20 open- and closed-source S-LLMs. Using multi-turn interactions, SimBench employs a rule-based judge LLM (J-LLM) that leverages both predefined rules and human-in-the-loop guidance to assign scores for the DTs generated by the S-LLM, thus providing a consistent and expert-inspired evaluation protocol. The J-LLM is specific to a simulator, and herein the proposed benchmarking approach is demonstrated in conjunction with the Chrono multi-physics simulator. Chrono provided the backdrop used to assess an S-LLM in relation to the latter's ability to create digital twins for multibody dynamics, finite element analysis, vehicle dynamics, robotic dynamics, and sensor simulations. The proposed benchmarking principle is broadly applicable and enables the assessment of an S-LLM's ability to generate digital twins for other simulation packages. All code and data are available at https://github.com/uwsbel/SimBench.