 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCo-Design of Rover Wheels and Control using Bayesian Optimization and Rover-Terrain Simulations
Feb 02, 2026While simulation is vital for optimizing robotic systems, the cost of modeling deformable terrain has long limited its use in full-vehicle studies of off-road autonomous mobility. For example, Discrete Element Method (DEM) simulations are often confined to single-wheel tests, which obscures coupled wheel-vehicle-controller interactions and prevents joint optimization of mechanical design and control. This paper presents a Bayesian optimization framework that co-designs rover wheel geometry and steering controller parameters using high-fidelity, full-vehicle closed-loop simulations on deformable terrain. Using the efficiency and scalability of a continuum-representation model (CRM) for terramechanics, we evaluate candidate designs on trajectories of varying complexity while towing a fixed load. The optimizer tunes wheel parameters (radius, width, and grouser features) and steering PID gains under a multi-objective formulation that balances traversal speed, tracking error, and energy consumption. We compare two strategies: simultaneous co-optimization of wheel and controller parameters versus a sequential approach that decouples mechanical and control design. We analyze trade-offs in performance and computational cost. Across 3,000 full-vehicle simulations, campaigns finish in five to nine days, versus months with the group's earlier DEM-based workflow. Finally, a preliminary hardware study suggests the simulation-optimized wheel designs preserve relative performance trends on the physical rover. Together, these results show that scalable, high-fidelity simulation can enable practical co-optimization of wheel design and control for off-road vehicles on deformable terrain without relying on prohibitively expensive DEM studies. The simulation infrastructure (scripts and models) is released as open source in a public repository to support reproducibility and further research.
SimBench: A Rule-Based Multi-Turn Interaction Benchmark for Evaluating an LLM's Ability to Generate Digital Twins
Aug 21, 2024We introduce SimBench, a benchmark designed to evaluate the proficiency of student large language models (S-LLMs) in generating digital twins (DTs) that can be used in simulators for virtual testing. Given a collection of S-LLMs, this benchmark enables the ranking of the S-LLMs based on their ability to produce high-quality DTs. We demonstrate this by comparing over 20 open- and closed-source S-LLMs. Using multi-turn interactions, SimBench employs a rule-based judge LLM (J-LLM) that leverages both predefined rules and human-in-the-loop guidance to assign scores for the DTs generated by the S-LLM, thus providing a consistent and expert-inspired evaluation protocol. The J-LLM is specific to a simulator, and herein the proposed benchmarking approach is demonstrated in conjunction with the Chrono multi-physics simulator. Chrono provided the backdrop used to assess an S-LLM in relation to the latter's ability to create digital twins for multibody dynamics, finite element analysis, vehicle dynamics, robotic dynamics, and sensor simulations. The proposed benchmarking principle is broadly applicable and enables the assessment of an S-LLM's ability to generate digital twins for other simulation packages. All code and data are available at https://github.com/uwsbel/SimBench.
Using a Bayesian-Inference Approach to Calibrating Models for Simulation in Robotics
May 11, 2023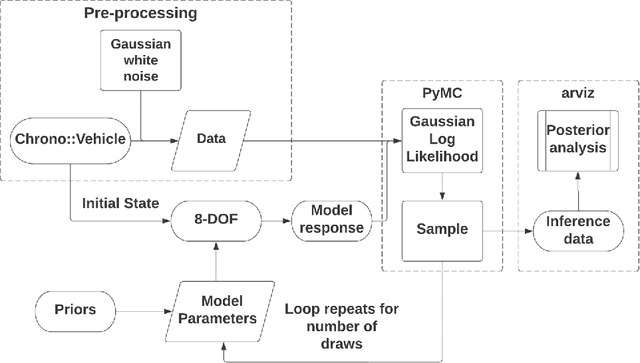


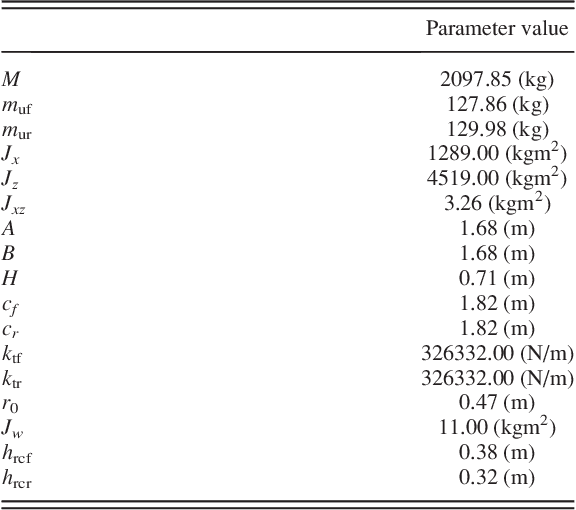
In robotics, simulation has the potential to reduce design time and costs, and lead to a more robust engineered solution and a safer development process. However, the use of simulators is predicated on the availability of good models. This contribution is concerned with improving the quality of these models via calibration, which is cast herein in a Bayesian framework. First, we discuss the Bayesian machinery involved in model calibration. Then, we demonstrate it in one example: calibration of a vehicle dynamics model that has low degree of freedom count and can be used for state estimation, model predictive control, or path planning. A high fidelity simulator is used to emulate the ``experiments'' and generate the data for the calibration. The merit of this work is not tied to a new Bayesian methodology for calibration, but to the demonstration of how the Bayesian machinery can establish connections among models in computational dynamics, even when the data in use is noisy. The software used to generate the results reported herein is available in a public repository for unfettered use and distribution.
* 19 pages, 42 figures