 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoding Agent Is Good As World Simulator
May 14, 2026World models have emerged as a powerful paradigm for building interactive simulation environments, with recent video-based approaches demonstrating impressive progress in generating visually plausible dynamics. However, because these models typically infer dynamics from video and represent them in latent states, they do not explicitly enforce physical constraints. As a result, the generated video rollouts are not physically plausible, exhibiting unstable contacts, distorted shapes, or inconsistent motion. In this paper, we present an agentic framework constructing physics-based world models through executable simulation code. The framework coordinates planning, code generation, visual review, and physics analysis agents. The planning agent converts the natural language prompt into a structured scene plan, the code agent implements it as executable simulation code, and the visual review agent provide visual feedback while the physics analysis agent checks physical consistency. The code is iteratively revised based on the feedback until the simulation matches the prompt reqirements and physical constraints. Experimental results show that our framework outperforms advanced video-based models in physical accuracy, instruction fidelity and visual quality, which could be applied to various scenarios including driving simulation and embodied robot tasks.
Chrono-Gymnasium: An Open-Source, Gymnasium-Compatible Distributed Simulation Framework
May 14, 2026High-fidelity physics simulation is essential for closing the sim-to-real gap in robotics and complex mechanical systems. However, the computational overhead of high-fidelity engines often limits their use in data-intensive tasks like Reinforcement Learning (RL) and global optimization. We introduce Chrono-Gymnasium, a distributed computing framework that scales the high-fidelity multi-body dynamics of Project Chrono across large-scale computing clusters. Built upon the Ray framework, Chrono-Gymnasium provides a standardized Gymnasium interface, enabling seamless integration with modern machine learning libraries while providing built-in synchronization and messaging primitives for distributed execution. We demonstrate the framework's capabilities through two distinct case studies: (1) the training of an RL agent for autonomous robotic navigation in complex terrains, and (2) the Bayesian Optimization of a planetary lander's design parameters to ensure landing stability. Our results show that Chrono-Gymnasium reduces wall-clock time for high-fidelity simulations without sacrificing physical accuracy, offering a scalable path for the design and control of complex robotic systems.
Active Learning for Communication Structure Optimization in LLM-Based Multi-Agent Systems
May 07, 2026Optimizing the communication structure of large language model based multi-agent systems (LLM-MAS) has been shown to improve downstream performance and reduce token usage. Existing methods typically rely on randomly sampled training tasks. However, tasks may differ substantially in difficulty and domain, and thus they are not equally informative for updating communication structure, making optimization under limited training budgets often unstable and highly sensitive to the particular training set. To actively identify the most valuable tasks for communication-structure optimization, we propose an ensemble-based information-theoretic task selection framework. The proposed method estimates task informativeness by how much a candidate task changes the distribution over graph parameters, using ensemble Kalman inversion as an efficient and derivative-free approximation of the corresponding Bayesian update. The resulting estimator is especially suitable for black-box and noisy multi-agent systems. To enhance scalability, we construct a compact candidate pool through embedding-based representative selection and combine the informative selection with surrogate modeling and batch Thompson sampling. We validate our method in both benign settings and settings with agent attacks, demonstrating its effectiveness for communication-structure optimization under constrained computational budgets.
Co-Design of Rover Wheels and Control using Bayesian Optimization and Rover-Terrain Simulations
Feb 02, 2026While simulation is vital for optimizing robotic systems, the cost of modeling deformable terrain has long limited its use in full-vehicle studies of off-road autonomous mobility. For example, Discrete Element Method (DEM) simulations are often confined to single-wheel tests, which obscures coupled wheel-vehicle-controller interactions and prevents joint optimization of mechanical design and control. This paper presents a Bayesian optimization framework that co-designs rover wheel geometry and steering controller parameters using high-fidelity, full-vehicle closed-loop simulations on deformable terrain. Using the efficiency and scalability of a continuum-representation model (CRM) for terramechanics, we evaluate candidate designs on trajectories of varying complexity while towing a fixed load. The optimizer tunes wheel parameters (radius, width, and grouser features) and steering PID gains under a multi-objective formulation that balances traversal speed, tracking error, and energy consumption. We compare two strategies: simultaneous co-optimization of wheel and controller parameters versus a sequential approach that decouples mechanical and control design. We analyze trade-offs in performance and computational cost. Across 3,000 full-vehicle simulations, campaigns finish in five to nine days, versus months with the group's earlier DEM-based workflow. Finally, a preliminary hardware study suggests the simulation-optimized wheel designs preserve relative performance trends on the physical rover. Together, these results show that scalable, high-fidelity simulation can enable practical co-optimization of wheel design and control for off-road vehicles on deformable terrain without relying on prohibitively expensive DEM studies. The simulation infrastructure (scripts and models) is released as open source in a public repository to support reproducibility and further research.
ChronoDreamer: Action-Conditioned World Model as an Online Simulator for Robotic Planning
Dec 21, 2025We present ChronoDreamer, an action-conditioned world model for contact-rich robotic manipulation. Given a history of egocentric RGB frames, contact maps, actions, and joint states, ChronoDreamer predicts future video frames, contact distributions, and joint angles via a spatial-temporal transformer trained with MaskGIT-style masked prediction. Contact is encoded as depth-weighted Gaussian splat images that render 3D forces into a camera-aligned format suitable for vision backbones. At inference, predicted rollouts are evaluated by a vision-language model that reasons about collision likelihood, enabling rejection sampling of unsafe actions before execution. We train and evaluate on DreamerBench, a simulation dataset generated with Project Chrono that provides synchronized RGB, contact splat, proprioception, and physics annotations across rigid and deformable object scenarios. Qualitative results demonstrate that the model preserves spatial coherence during non-contact motion and generates plausible contact predictions, while the LLM-based judge distinguishes collision from non-collision trajectories.
DiffPhysCam: Differentiable Physics-Based Camera Simulation for Inverse Rendering and Embodied AI
Aug 12, 2025



We introduce DiffPhysCam, a differentiable camera simulator designed to support robotics and embodied AI applications by enabling gradient-based optimization in visual perception pipelines. Generating synthetic images that closely mimic those from real cameras is essential for training visual models and enabling end-to-end visuomotor learning. Moreover, differentiable rendering allows inverse reconstruction of real-world scenes as digital twins, facilitating simulation-based robotics training. However, existing virtual cameras offer limited control over intrinsic settings, poorly capture optical artifacts, and lack tunable calibration parameters -- hindering sim-to-real transfer. DiffPhysCam addresses these limitations through a multi-stage pipeline that provides fine-grained control over camera settings, models key optical effects such as defocus blur, and supports calibration with real-world data. It enables both forward rendering for image synthesis and inverse rendering for 3D scene reconstruction, including mesh and material texture optimization. We show that DiffPhysCam enhances robotic perception performance in synthetic image tasks. As an illustrative example, we create a digital twin of a real-world scene using inverse rendering, simulate it in a multi-physics environment, and demonstrate navigation of an autonomous ground vehicle using images generated by DiffPhysCam.
ChronoLLM: A Framework for Customizing Large Language Model for Digital Twins generalization based on PyChrono
Jan 07, 2025
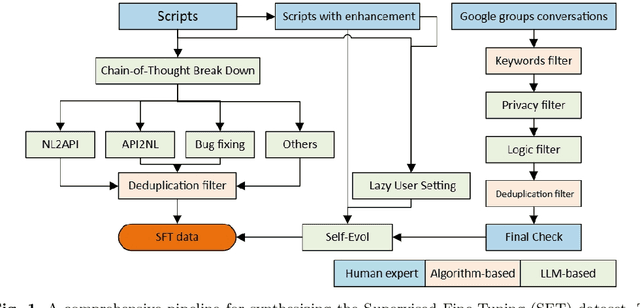

Recently, the integration of advanced simulation technologies with artificial intelligence (AI) is revolutionizing science and engineering research. ChronoLlama introduces a novel framework that customizes the open-source LLMs, specifically for code generation, paired with PyChrono for multi-physics simulations. This integration aims to automate and improve the creation of simulation scripts, thus enhancing model accuracy and efficiency. This combination harnesses the speed of AI-driven code generation with the reliability of physics-based simulations, providing a powerful tool for researchers and engineers. Empirical results indicate substantial enhancements in simulation setup speed, accuracy of the generated codes, and overall computational efficiency. ChronoLlama not only expedites the development and testing of multibody systems but also spearheads a scalable, AI-enhanced approach to managing intricate mechanical simulations. This pioneering integration of cutting-edge AI with traditional simulation platforms represents a significant leap forward in automating and optimizing design processes in engineering applications.
Instance Performance Difference: A Metric to Measure the Sim-To-Real Gap in Camera Simulation
Nov 11, 2024



In this contribution, we introduce the concept of Instance Performance Difference (IPD), a metric designed to measure the gap in performance that a robotics perception task experiences when working with real vs. synthetic pictures. By pairing synthetic and real instances in the pictures and evaluating their performance similarity using perception algorithms, IPD provides a targeted metric that closely aligns with the needs of real-world applications. We explain and demonstrate this metric through a rock detection task in lunar terrain images, highlighting the IPD's effectiveness in identifying the most realistic image synthesis method. The metric is thus instrumental in creating synthetic image datasets that perform in perception tasks like real-world photo counterparts. In turn, this supports robust sim-to-real transfer for perception algorithms in real-world robotics applications.
A physics-based sensor simulation environment for lunar ground operations
Oct 06, 2024This contribution reports on a software framework that uses physically-based rendering to simulate camera operation in lunar conditions. The focus is on generating synthetic images qualitatively similar to those produced by an actual camera operating on a vehicle traversing and/or actively interacting with lunar terrain, e.g., for construction operations. The highlights of this simulator are its ability to capture (i) light transport in lunar conditions and (ii) artifacts related to the vehicle-terrain interaction, which might include dust formation and transport. The simulation infrastructure is built within an in-house developed physics engine called Chrono, which simulates the dynamics of the deformable terrain-vehicle interaction, as well as fallout of this interaction. The Chrono::Sensor camera model draws on ray tracing and Hapke Photometric Functions. We analyze the performance of the simulator using two virtual experiments featuring digital twins of NASA's VIPER rover navigating a lunar environment, and of the NASA's RASSOR excavator engaged into a digging operation. The sensor simulation solution presented can be used for the design and testing of perception algorithms, or as a component of in-silico experiments that pertain to large lunar operations, e.g., traversability, construction tasks.
Enhancing Autonomous Navigation by Imaging Hidden Objects using Single-Photon LiDAR
Oct 04, 2024



Robust autonomous navigation in environments with limited visibility remains a critical challenge in robotics. We present a novel approach that leverages Non-Line-of-Sight (NLOS) sensing using single-photon LiDAR to improve visibility and enhance autonomous navigation. Our method enables mobile robots to "see around corners" by utilizing multi-bounce light information, effectively expanding their perceptual range without additional infrastructure. We propose a three-module pipeline: (1) Sensing, which captures multi-bounce histograms using SPAD-based LiDAR; (2) Perception, which estimates occupancy maps of hidden regions from these histograms using a convolutional neural network; and (3) Control, which allows a robot to follow safe paths based on the estimated occupancy. We evaluate our approach through simulations and real-world experiments on a mobile robot navigating an L-shaped corridor with hidden obstacles. Our work represents the first experimental demonstration of NLOS imaging for autonomous navigation, paving the way for safer and more efficient robotic systems operating in complex environments. We also contribute a novel dynamics-integrated transient rendering framework for simulating NLOS scenarios, facilitating future research in this domain.