 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on the Use of Simulation in Synthesizing Path-Following Control Policies for Autonomous Ground Robots
Mar 26, 2024We report results obtained and insights gained while answering the following question: how effective is it to use a simulator to establish path following control policies for an autonomous ground robot? While the quality of the simulator conditions the answer to this question, we found that for the simulation platform used herein, producing four control policies for path planning was straightforward once a digital twin of the controlled robot was available. The control policies established in simulation and subsequently demonstrated in the real world are PID control, MPC, and two neural network (NN) based controllers. Training the two NN controllers via imitation learning was accomplished expeditiously using seven simple maneuvers: follow three circles clockwise, follow the same circles counter-clockwise, and drive straight. A test randomization process that employs random micro-simulations is used to rank the ``goodness'' of the four control policies. The policy ranking noted in simulation correlates well with the ranking observed when the control policies were tested in the real world. The simulation platform used is publicly available and BSD3-released as open source; a public Docker image is available for reproducibility studies. It contains a dynamics engine, a sensor simulator, a ROS2 bridge, and a ROS2 autonomy stack the latter employed both in the simulator and the real world experiments.
Quantifying the Sim2real Gap for GPS and IMU Sensors
Mar 16, 2024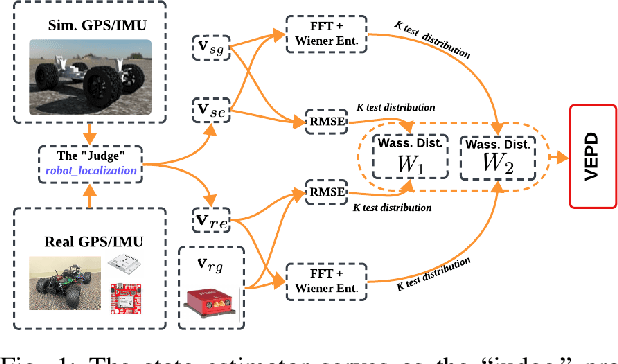

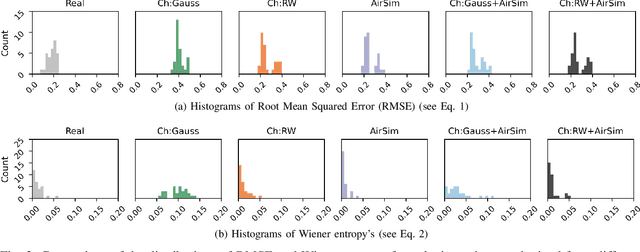
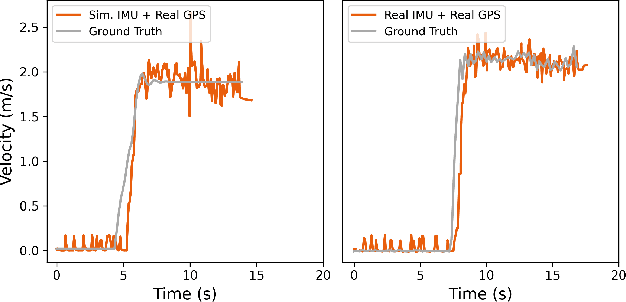
Simulation can and should play a critical role in the development and testing of algorithms for autonomous agents. What might reduce its impact is the ``sim2real'' gap -- the algorithm response differs between operation in simulated versus real-world environments. This paper introduces an approach to evaluate this gap, focusing on the accuracy of sensor simulation -- specifically IMU and GPS -- in velocity estimation tasks for autonomous agents. Using a scaled autonomous vehicle, we conduct 40 real-world experiments across diverse environments then replicate the experiments in simulation with five distinct sensor noise models. We note that direct comparison of raw simulation and real sensor data fails to quantify the sim2real gap for robotics applications. We demonstrate that by using a state of the art state-estimation package as a ``judge'', and by evaluating the performance of this state-estimator in both real and simulated scenarios, we can isolate the sim2real discrepancies stemming from sensor simulations alone. The dataset generated is open-source and publicly available for unfettered use.
Zero-Shot Policy Transferability for the Control of a Scale Autonomous Vehicle
Sep 18, 2023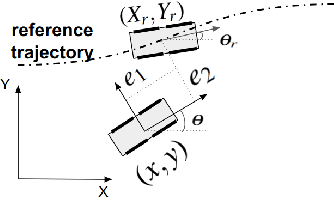
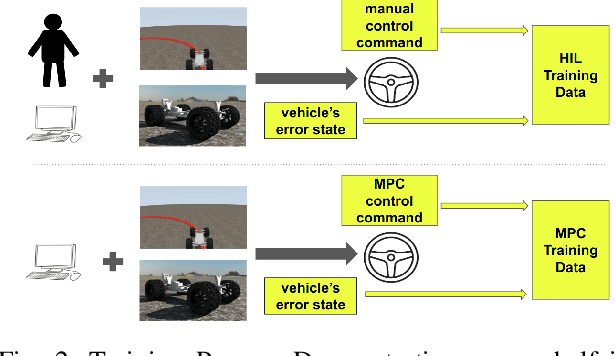
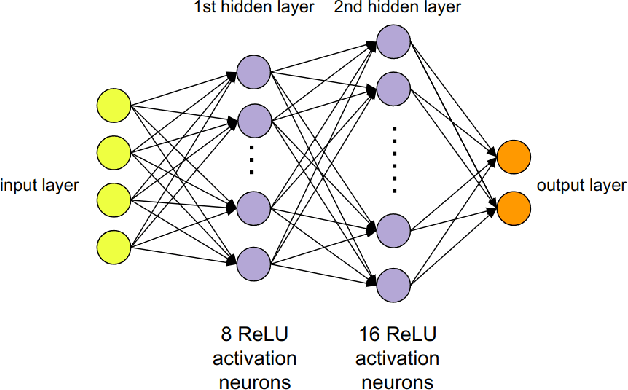
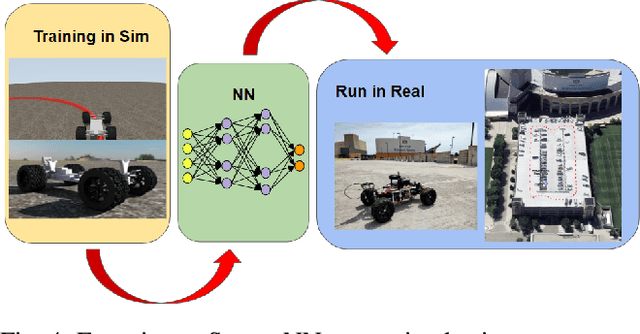
We report on a study that employs an in-house developed simulation infrastructure to accomplish zero shot policy transferability for a control policy associated with a scale autonomous vehicle. We focus on implementing policies that require no real world data to be trained (Zero-Shot Transfer), and are developed in-house as opposed to being validated by previous works. We do this by implementing a Neural Network (NN) controller that is trained only on a family of circular reference trajectories. The sensors used are RTK-GPS and IMU, the latter for providing heading. The NN controller is trained using either a human driver (via human in the loop simulation), or a Model Predictive Control (MPC) strategy. We demonstrate these two approaches in conjunction with two operation scenarios: the vehicle follows a waypoint-defined trajectory at constant speed; and the vehicle follows a speed profile that changes along the vehicle's waypoint-defined trajectory. The primary contribution of this work is the demonstration of Zero-Shot Transfer in conjunction with a novel feed-forward NN controller trained using a general purpose, in-house developed simulation platform.