 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSOLAR: AI-Powered Speed-of-Light Performance Analysis
Jun 24, 2026How fast could a deep-learning model run on target hardware, and how far is today's implementation from that limit? These questions are central to software, hardware, and algorithm optimizations. Speed-of-Light (SOL) analysis answers them by computing a workload's theoretical minimum execution time on a given architecture. Yet deriving SOL bounds remains manual, error-prone, and disconnected from rapid model development. To close this gap, we introduce SOLAR, a framework that automatically derives validated SOL bounds from PyTorch and JAX source code. SOLAR leverages both generative and deterministic components in its flow: an LLM frontend translates any source programs into an executable Affine Loop IR, validated by output comparison; a deterministic flow lifts the IR into an einsum graph; and an analytical backend computes unfused, fused, and cache-aware SOL bounds. SOLAR provides comprehensive operator and language coverage, produces validated bounds with zero observed SOL violations, and offers multi-fidelity analysis that tightens bounds and surfaces optimization insights. We evaluate SOLAR across KernelBench, JAX/Flax models, and robotics workloads. These experiments demonstrate four use cases: headroom analysis at multiple fidelity levels, identifying optimization opportunities, cross-platform exploration, and inverse-roofline hardware provisioning.
Nemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Chrono-Gymnasium: An Open-Source, Gymnasium-Compatible Distributed Simulation Framework
May 14, 2026High-fidelity physics simulation is essential for closing the sim-to-real gap in robotics and complex mechanical systems. However, the computational overhead of high-fidelity engines often limits their use in data-intensive tasks like Reinforcement Learning (RL) and global optimization. We introduce Chrono-Gymnasium, a distributed computing framework that scales the high-fidelity multi-body dynamics of Project Chrono across large-scale computing clusters. Built upon the Ray framework, Chrono-Gymnasium provides a standardized Gymnasium interface, enabling seamless integration with modern machine learning libraries while providing built-in synchronization and messaging primitives for distributed execution. We demonstrate the framework's capabilities through two distinct case studies: (1) the training of an RL agent for autonomous robotic navigation in complex terrains, and (2) the Bayesian Optimization of a planetary lander's design parameters to ensure landing stability. Our results show that Chrono-Gymnasium reduces wall-clock time for high-fidelity simulations without sacrificing physical accuracy, offering a scalable path for the design and control of complex robotic systems.
Coding Agent Is Good As World Simulator
May 14, 2026World models have emerged as a powerful paradigm for building interactive simulation environments, with recent video-based approaches demonstrating impressive progress in generating visually plausible dynamics. However, because these models typically infer dynamics from video and represent them in latent states, they do not explicitly enforce physical constraints. As a result, the generated video rollouts are not physically plausible, exhibiting unstable contacts, distorted shapes, or inconsistent motion. In this paper, we present an agentic framework constructing physics-based world models through executable simulation code. The framework coordinates planning, code generation, visual review, and physics analysis agents. The planning agent converts the natural language prompt into a structured scene plan, the code agent implements it as executable simulation code, and the visual review agent provide visual feedback while the physics analysis agent checks physical consistency. The code is iteratively revised based on the feedback until the simulation matches the prompt reqirements and physical constraints. Experimental results show that our framework outperforms advanced video-based models in physical accuracy, instruction fidelity and visual quality, which could be applied to various scenarios including driving simulation and embodied robot tasks.
SOL-ExecBench: Speed-of-Light Benchmarking for Real-World GPU Kernels Against Hardware Limits
Mar 19, 2026As agentic AI systems become increasingly capable of generating and optimizing GPU kernels, progress is constrained by benchmarks that reward speedup over software baselines rather than proximity to hardware-efficient execution. We present SOL-ExecBench, a benchmark of 235 CUDA kernel optimization problems extracted from 124 production and emerging AI models spanning language, diffusion, vision, audio, video, and hybrid architectures, targeting NVIDIA Blackwell GPUs. The benchmark covers forward and backward workloads across BF16, FP8, and NVFP4, including kernels whose best performance is expected to rely on Blackwell-specific capabilities. Unlike prior benchmarks that evaluate kernels primarily relative to software implementations, SOL-ExecBench measures performance against analytically derived Speed-of-Light (SOL) bounds computed by SOLAR, our pipeline for deriving hardware-grounded SOL bounds, yielding a fixed target for hardware-efficient optimization. We report a SOL Score that quantifies how much of the gap between a release-defined scoring baseline and the hardware SOL bound a candidate kernel closes. To support robust evaluation of agentic optimizers, we additionally provide a sandboxed harness with GPU clock locking, L2 cache clearing, isolated subprocess execution, and static analysis based checks against common reward-hacking strategies. SOL-ExecBench reframes GPU kernel benchmarking from beating a mutable software baseline to closing the remaining gap to hardware Speed-of-Light.
Learning Heat-based Equations in Self-similar variables
Feb 03, 2026We study solution learning for heat-based equations in self-similar variables (SSV). We develop an SSV training framework compatible with standard neural-operator training. We instantiate this framework on the two-dimensional incompressible Navier-Stokes equations and the one-dimensional viscous Burgers equation, and perform controlled comparisons between models trained in physical coordinates and in the corresponding self-similar coordinates using two simple fully connected architectures (standard multilayer perceptrons and a factorized fully connected network). Across both systems and both architectures, SSV-trained networks consistently deliver substantially more accurate and stable extrapolation beyond the training window and better capture qualitative long-time trends. These results suggest that self-similar coordinates provide a mathematically motivated inductive bias for learning the long-time dynamics of heat-based equations.
R1-Code-Interpreter: Training LLMs to Reason with Code via Supervised and Reinforcement Learning
May 27, 2025



Despite advances in reasoning and planning of R1-like models, Large Language Models (LLMs) still struggle with tasks requiring precise computation, symbolic manipulation, optimization, and algorithmic reasoning, in which textual reasoning lacks the rigor of code execution. A key challenge is enabling LLMs to decide when to use textual reasoning versus code generation. While OpenAI trains models to invoke a Code Interpreter as needed, public research lacks guidance on aligning pre-trained LLMs to effectively leverage code and generalize across diverse tasks. We present R1-Code-Interpreter, an extension of a text-only LLM trained via multi-turn supervised fine-tuning (SFT) and reinforcement learning (RL) to autonomously generate multiple code queries during step-by-step reasoning. We curate 144 reasoning and planning tasks (107 for training, 37 for testing), each with over 200 diverse questions. We fine-tune Qwen-2.5 models (3B/7B/14B) using various SFT and RL strategies, investigating different answer formats, reasoning vs. non-reasoning models, cold vs. warm starts, GRPO vs. PPO, and masked vs. unmasked code outputs. Unlike prior RL work on narrow domains, we find that Code Interpreter training is significantly harder due to high task diversity and expensive code execution, highlighting the critical role of the SFT stage. Our final model, R1-CI-14B, improves average accuracy on the 37 test tasks from 44.0\% to 64.1\%, outperforming GPT-4o (text-only: 58.6\%) and approaching GPT-4o with Code Interpreter (70.9\%), with the emergent self-checking behavior via code generation. Datasets, Codes, and Models are available at https://github.com/yongchao98/R1-Code-Interpreter and https://huggingface.co/yongchao98.
ChronoLLM: A Framework for Customizing Large Language Model for Digital Twins generalization based on PyChrono
Jan 07, 2025
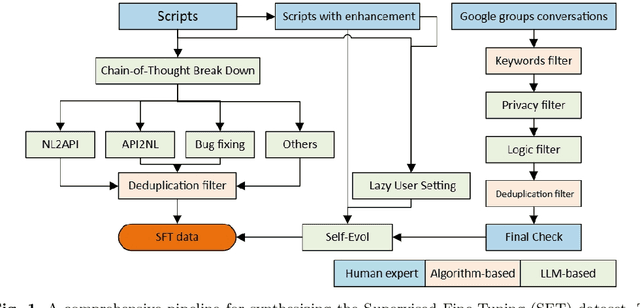

Recently, the integration of advanced simulation technologies with artificial intelligence (AI) is revolutionizing science and engineering research. ChronoLlama introduces a novel framework that customizes the open-source LLMs, specifically for code generation, paired with PyChrono for multi-physics simulations. This integration aims to automate and improve the creation of simulation scripts, thus enhancing model accuracy and efficiency. This combination harnesses the speed of AI-driven code generation with the reliability of physics-based simulations, providing a powerful tool for researchers and engineers. Empirical results indicate substantial enhancements in simulation setup speed, accuracy of the generated codes, and overall computational efficiency. ChronoLlama not only expedites the development and testing of multibody systems but also spearheads a scalable, AI-enhanced approach to managing intricate mechanical simulations. This pioneering integration of cutting-edge AI with traditional simulation platforms represents a significant leap forward in automating and optimizing design processes in engineering applications.
SimBench: A Rule-Based Multi-Turn Interaction Benchmark for Evaluating an LLM's Ability to Generate Digital Twins
Aug 21, 2024We introduce SimBench, a benchmark designed to evaluate the proficiency of student large language models (S-LLMs) in generating digital twins (DTs) that can be used in simulators for virtual testing. Given a collection of S-LLMs, this benchmark enables the ranking of the S-LLMs based on their ability to produce high-quality DTs. We demonstrate this by comparing over 20 open- and closed-source S-LLMs. Using multi-turn interactions, SimBench employs a rule-based judge LLM (J-LLM) that leverages both predefined rules and human-in-the-loop guidance to assign scores for the DTs generated by the S-LLM, thus providing a consistent and expert-inspired evaluation protocol. The J-LLM is specific to a simulator, and herein the proposed benchmarking approach is demonstrated in conjunction with the Chrono multi-physics simulator. Chrono provided the backdrop used to assess an S-LLM in relation to the latter's ability to create digital twins for multibody dynamics, finite element analysis, vehicle dynamics, robotic dynamics, and sensor simulations. The proposed benchmarking principle is broadly applicable and enables the assessment of an S-LLM's ability to generate digital twins for other simulation packages. All code and data are available at https://github.com/uwsbel/SimBench.
A Unified Weight Initialization Paradigm for Tensorial Convolutional Neural Networks
May 28, 2022
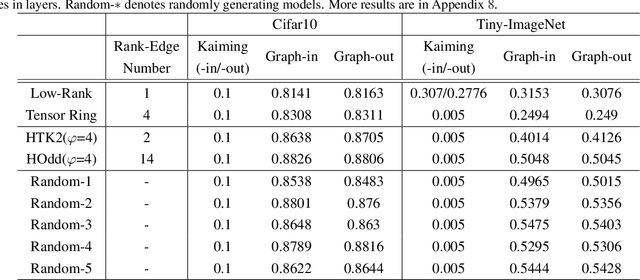

Tensorial Convolutional Neural Networks (TCNNs) have attracted much research attention for their power in reducing model parameters or enhancing the generalization ability. However, exploration of TCNNs is hindered even from weight initialization methods. To be specific, general initialization methods, such as Xavier or Kaiming initialization, usually fail to generate appropriate weights for TCNNs. Meanwhile, although there are ad-hoc approaches for specific architectures (e.g., Tensor Ring Nets), they are not applicable to TCNNs with other tensor decomposition methods (e.g., CP or Tucker decomposition). To address this problem, we propose a universal weight initialization paradigm, which generalizes Xavier and Kaiming methods and can be widely applicable to arbitrary TCNNs. Specifically, we first present the Reproducing Transformation to convert the backward process in TCNNs to an equivalent convolution process. Then, based on the convolution operators in the forward and backward processes, we build a unified paradigm to control the variance of features and gradients in TCNNs. Thus, we can derive fan-in and fan-out initialization for various TCNNs. We demonstrate that our paradigm can stabilize the training of TCNNs, leading to faster convergence and better results.