 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceive-then-Plan: Layout-as-Policy for Monocular 3D Scene Layout Estimation
May 25, 2026Building structured 3D scene layouts from a single image requires reconciling visual observations with physical and spatial constraints, a challenge that is difficult to address with direct prediction alone. In this work, we formulate monocular 3D layout estimation as a perceive-then-plan problem with vision-language models, where a Perceiver first grounds the 3D objects and then a Planner iteratively refines the scene hypothesis through actions that improve physical plausibility while preserving consistency with the input image. We propose Layout-as-Policy (LaP), which casts the planning stage as a policy learning problem: 3D layouts are represented as structured states, and refined via discrete actions such as translation, rotation, and rescaling. Starting from an observation-aligned initialization with the geometry-enhanced Perceiver, the LaP Planner is trained to produce action sequences that progressively resolve geometric inconsistencies and enforce realistic spatial relations. To enable effective learning, we combine supervised trajectory initialization with preference-based optimization, allowing the model to learn corrective behaviors without requiring explicit reward engineering. This formulation transforms layout estimation from a one-shot prediction task into an iterative refinement process, enabling better handling of global constraints and complex object interactions. Experiments demonstrate that our approach produces layouts that are more physically coherent and better aligned with visual observations, while naturally supporting downstream tasks such as scene editing and manipulation.
Distributed Image Compression with Multimodal Side Information at Extremely Low Bitrates
May 21, 2026Distributed Image Compression (DIC) is crucial for multi-view transmission, especially when operating at extremely low bitrates (< 0.1 bpp). Its core challenge is effectively utilizing side information to achieve high-quality reconstruction under strict bitrate budgets. However, existing DIC approaches struggle to exploit global context and object-level details from side information, leading to local blurring and the loss of fine details in the reconstruction. To address these limitations, we propose a Multimodal DIC framework (MDIC), which, for the first time, leverages side information in a multimodal manner into the DIC paradigm, effectively preserving fine-grained local details and enhancing global perceptual quality in reconstructed images. Specifically, we introduce a text-to-image diffusion-based decoder conditioned on textual side information extracted from correlated images to capture shared global semantics. Moreover, we design a feature-mask generator, supervised by a multimodal fine-grained alignment task, to strengthen the exploitation of visual side information. The generated mask serves two purposes: first, it guides the extraction of fine-grained details from losslessly transmitted side information to preserve the semantic consistency of reconstructed details; second, it regulates the extraction of clustered feature representations from the quantized VQ-VAE embeddings, compensating for category information lost under the extreme compression of the primary image. Extensive experiments on the widely used KITTI Stereo and Cityscapes datasets demonstrate that MDIC achieves state-of-the-art perceptual quality at extremely low bitrates.
CoCo4D: Comprehensive and Complex 4D Scene Generation
Jun 24, 2025Existing 4D synthesis methods primarily focus on object-level generation or dynamic scene synthesis with limited novel views, restricting their ability to generate multi-view consistent and immersive dynamic 4D scenes. To address these constraints, we propose a framework (dubbed as CoCo4D) for generating detailed dynamic 4D scenes from text prompts, with the option to include images. Our method leverages the crucial observation that articulated motion typically characterizes foreground objects, whereas background alterations are less pronounced. Consequently, CoCo4D divides 4D scene synthesis into two responsibilities: modeling the dynamic foreground and creating the evolving background, both directed by a reference motion sequence. Given a text prompt and an optional reference image, CoCo4D first generates an initial motion sequence utilizing video diffusion models. This motion sequence then guides the synthesis of both the dynamic foreground object and the background using a novel progressive outpainting scheme. To ensure seamless integration of the moving foreground object within the dynamic background, CoCo4D optimizes a parametric trajectory for the foreground, resulting in realistic and coherent blending. Extensive experiments show that CoCo4D achieves comparable or superior performance in 4D scene generation compared to existing methods, demonstrating its effectiveness and efficiency. More results are presented on our website https://colezwhy.github.io/coco4d/.
R1-Code-Interpreter: Training LLMs to Reason with Code via Supervised and Reinforcement Learning
May 27, 2025



Despite advances in reasoning and planning of R1-like models, Large Language Models (LLMs) still struggle with tasks requiring precise computation, symbolic manipulation, optimization, and algorithmic reasoning, in which textual reasoning lacks the rigor of code execution. A key challenge is enabling LLMs to decide when to use textual reasoning versus code generation. While OpenAI trains models to invoke a Code Interpreter as needed, public research lacks guidance on aligning pre-trained LLMs to effectively leverage code and generalize across diverse tasks. We present R1-Code-Interpreter, an extension of a text-only LLM trained via multi-turn supervised fine-tuning (SFT) and reinforcement learning (RL) to autonomously generate multiple code queries during step-by-step reasoning. We curate 144 reasoning and planning tasks (107 for training, 37 for testing), each with over 200 diverse questions. We fine-tune Qwen-2.5 models (3B/7B/14B) using various SFT and RL strategies, investigating different answer formats, reasoning vs. non-reasoning models, cold vs. warm starts, GRPO vs. PPO, and masked vs. unmasked code outputs. Unlike prior RL work on narrow domains, we find that Code Interpreter training is significantly harder due to high task diversity and expensive code execution, highlighting the critical role of the SFT stage. Our final model, R1-CI-14B, improves average accuracy on the 37 test tasks from 44.0\% to 64.1\%, outperforming GPT-4o (text-only: 58.6\%) and approaching GPT-4o with Code Interpreter (70.9\%), with the emergent self-checking behavior via code generation. Datasets, Codes, and Models are available at https://github.com/yongchao98/R1-Code-Interpreter and https://huggingface.co/yongchao98.
Layout-your-3D: Controllable and Precise 3D Generation with 2D Blueprint
Oct 20, 2024



We present Layout-Your-3D, a framework that allows controllable and compositional 3D generation from text prompts. Existing text-to-3D methods often struggle to generate assets with plausible object interactions or require tedious optimization processes. To address these challenges, our approach leverages 2D layouts as a blueprint to facilitate precise and plausible control over 3D generation. Starting with a 2D layout provided by a user or generated from a text description, we first create a coarse 3D scene using a carefully designed initialization process based on efficient reconstruction models. To enforce coherent global 3D layouts and enhance the quality of instance appearances, we propose a collision-aware layout optimization process followed by instance-wise refinement. Experimental results demonstrate that Layout-Your-3D yields more reasonable and visually appealing compositional 3D assets while significantly reducing the time required for each prompt. Additionally, Layout-Your-3D can be easily applicable to downstream tasks, such as 3D editing and object insertion. Our project page is available at:https://colezwhy.github.io/layoutyour3d/
WeakSAM: Segment Anything Meets Weakly-supervised Instance-level Recognition
Feb 22, 2024Weakly supervised visual recognition using inexact supervision is a critical yet challenging learning problem. It significantly reduces human labeling costs and traditionally relies on multi-instance learning and pseudo-labeling. This paper introduces WeakSAM and solves the weakly-supervised object detection (WSOD) and segmentation by utilizing the pre-learned world knowledge contained in a vision foundation model, i.e., the Segment Anything Model (SAM). WeakSAM addresses two critical limitations in traditional WSOD retraining, i.e., pseudo ground truth (PGT) incompleteness and noisy PGT instances, through adaptive PGT generation and Region of Interest (RoI) drop regularization. It also addresses the SAM's problems of requiring prompts and category unawareness for automatic object detection and segmentation. Our results indicate that WeakSAM significantly surpasses previous state-of-the-art methods in WSOD and WSIS benchmarks with large margins, i.e. average improvements of 7.4% and 8.5%, respectively. The code is available at \url{https://github.com/hustvl/WeakSAM}.
PACE: Pose Annotations in Cluttered Environments
Dec 23, 2023Pose estimation is a crucial task in computer vision, enabling tracking and manipulating objects in images or videos. While several datasets exist for pose estimation, there is a lack of large-scale datasets specifically focusing on cluttered scenes with occlusions. This limitation is a bottleneck in the development and evaluation of pose estimation methods, particularly toward the goal of real-world application in environments where occlusions are common. Addressing this, we introduce PACE (Pose Annotations in Cluttered Environments), a large-scale benchmark designed to advance the development and evaluation of pose estimation methods in cluttered scenarios. PACE encompasses 54,945 frames with 257,673 annotations across 300 videos, covering 576 objects from 44 categories and featuring a mix of rigid and articulated items in cluttered scenes. To annotate the real-world data efficiently, we developed an innovative annotation system utilizing a calibrated 3-camera setup. We test state-of-the-art algorithms in PACE along two tracks: pose estimation, and object pose tracking, revealing the benchmark's challenges and research opportunities. We plan to release PACE as a public evaluation benchmark, along the annotations tools we developed, to stimulate further advancements in the field. Our code and data is available on https://github.com/qq456cvb/PACE.
Robust Facial Landmark Localization Based on Texture and Pose Correlated Initialization
May 15, 2018
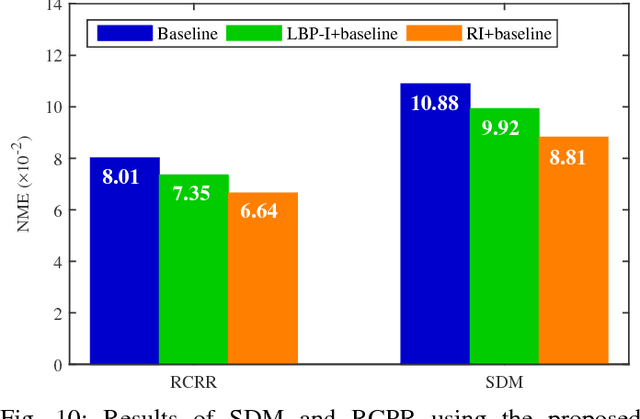

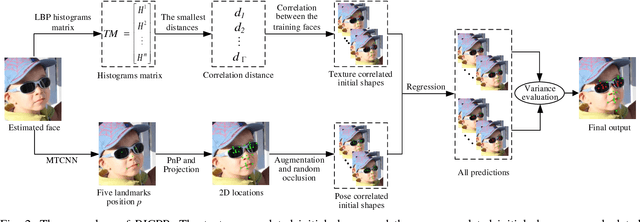
Robust facial landmark localization remains a challenging task when faces are partially occluded. Recently, the cascaded pose regression has attracted increasing attentions, due to it's superior performance in facial landmark localization and occlusion detection. However, such an approach is sensitive to initialization, where an improper initialization can severly degrade the performance. In this paper, we propose a Robust Initialization for Cascaded Pose Regression (RICPR) by providing texture and pose correlated initial shapes for the testing face. By examining the correlation of local binary patterns histograms between the testing face and the training faces, the shapes of the training faces that are most correlated with the testing face are selected as the texture correlated initialization. To make the initialization more robust to various poses, we estimate the rough pose of the testing face according to five fiducial landmarks located by multitask cascaded convolutional networks. Then the pose correlated initial shapes are constructed by the mean face's shape and the rough testing face pose. Finally, the texture correlated and the pose correlated initial shapes are joined together as the robust initialization. We evaluate RICPR on the challenging dataset of COFW. The experimental results demonstrate that the proposed scheme achieves better performances than the state-of-the-art methods in facial landmark localization and occlusion detection.