 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARM: A Large Articulated-Object Reconstruction Model
Nov 14, 2025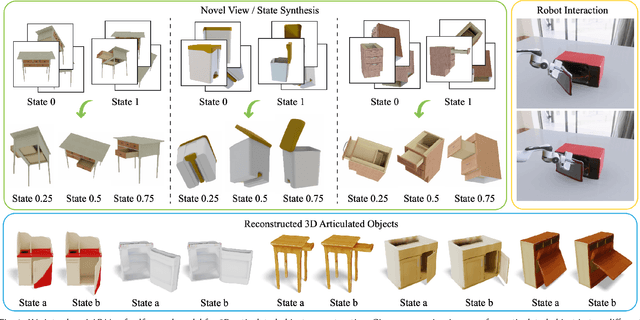
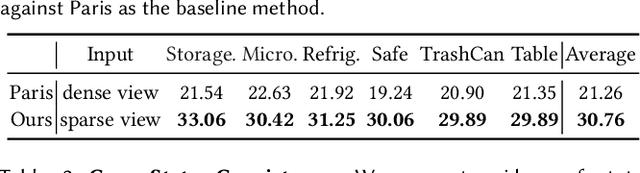


Modeling 3D articulated objects with realistic geometry, textures, and kinematics is essential for a wide range of applications. However, existing optimization-based reconstruction methods often require dense multi-view inputs and expensive per-instance optimization, limiting their scalability. Recent feedforward approaches offer faster alternatives but frequently produce coarse geometry, lack texture reconstruction, and rely on brittle, complex multi-stage pipelines. We introduce LARM, a unified feedforward framework that reconstructs 3D articulated objects from sparse-view images by jointly recovering detailed geometry, realistic textures, and accurate joint structures. LARM extends LVSM a recent novel view synthesis (NVS) approach for static 3D objects into the articulated setting by jointly reasoning over camera pose and articulation variation using a transformer-based architecture, enabling scalable and accurate novel view synthesis. In addition, LARM generates auxiliary outputs such as depth maps and part masks to facilitate explicit 3D mesh extraction and joint estimation. Our pipeline eliminates the need for dense supervision and supports high-fidelity reconstruction across diverse object categories. Extensive experiments demonstrate that LARM outperforms state-of-the-art methods in both novel view and state synthesis as well as 3D articulated object reconstruction, generating high-quality meshes that closely adhere to the input images. project page: https://sylviayuan-sy.github.io/larm-site/
3D-Adapter: Geometry-Consistent Multi-View Diffusion for High-Quality 3D Generation
Oct 24, 2024
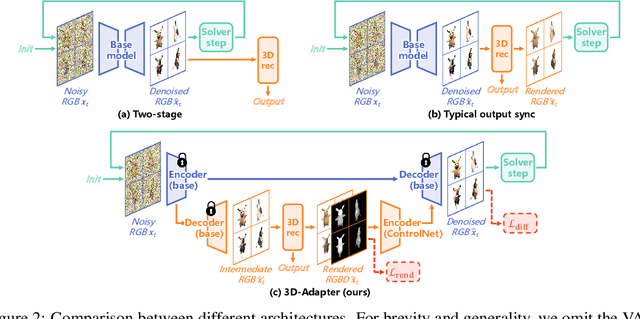
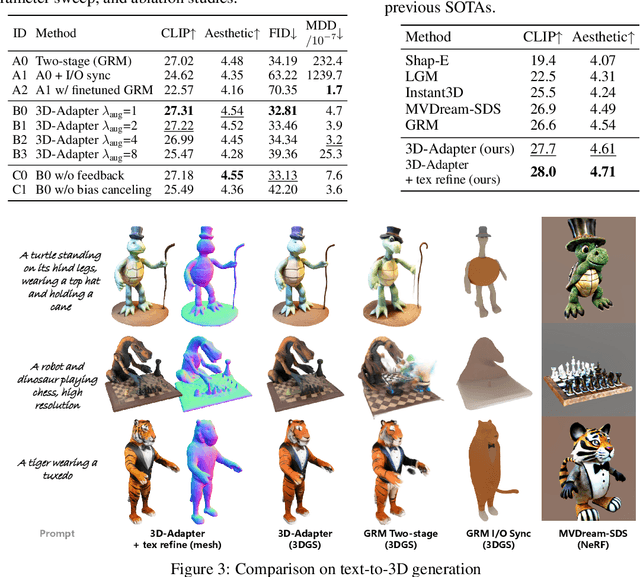
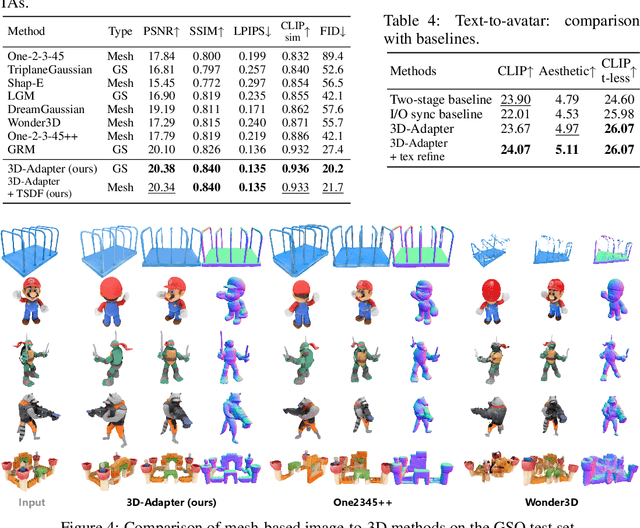
Multi-view image diffusion models have significantly advanced open-domain 3D object generation. However, most existing models rely on 2D network architectures that lack inherent 3D biases, resulting in compromised geometric consistency. To address this challenge, we introduce 3D-Adapter, a plug-in module designed to infuse 3D geometry awareness into pretrained image diffusion models. Central to our approach is the idea of 3D feedback augmentation: for each denoising step in the sampling loop, 3D-Adapter decodes intermediate multi-view features into a coherent 3D representation, then re-encodes the rendered RGBD views to augment the pretrained base model through feature addition. We study two variants of 3D-Adapter: a fast feed-forward version based on Gaussian splatting and a versatile training-free version utilizing neural fields and meshes. Our extensive experiments demonstrate that 3D-Adapter not only greatly enhances the geometry quality of text-to-multi-view models such as Instant3D and Zero123++, but also enables high-quality 3D generation using the plain text-to-image Stable Diffusion. Furthermore, we showcase the broad application potential of 3D-Adapter by presenting high quality results in text-to-3D, image-to-3D, text-to-texture, and text-to-avatar tasks.
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024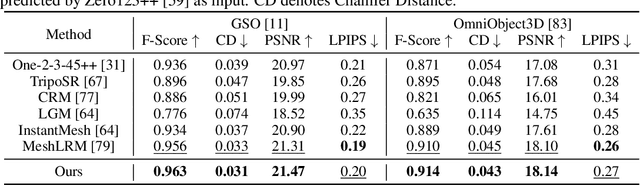
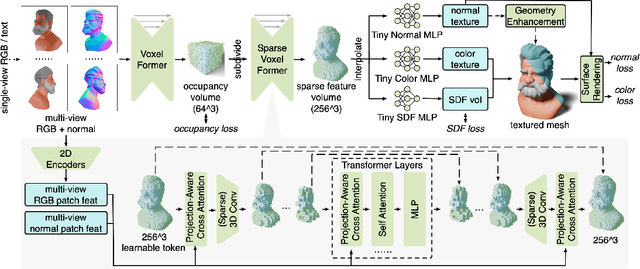


Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
SpaRP: Fast 3D Object Reconstruction and Pose Estimation from Sparse Views
Aug 19, 2024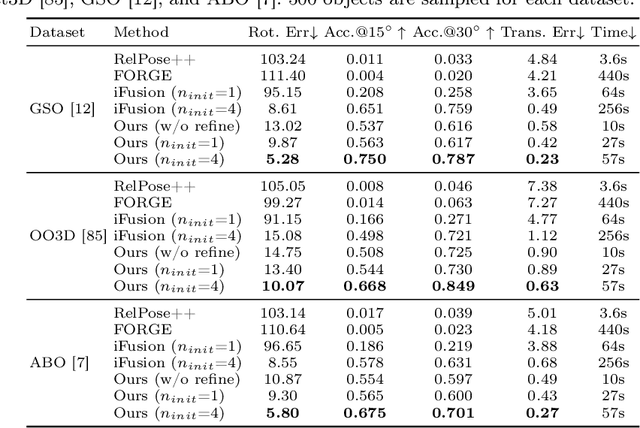

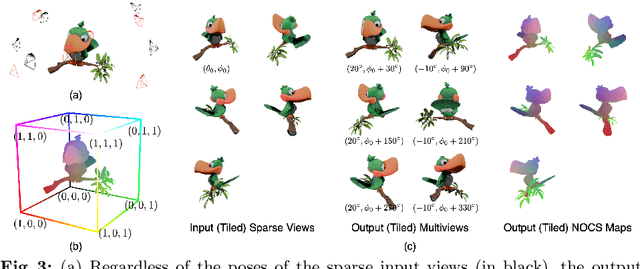

Open-world 3D generation has recently attracted considerable attention. While many single-image-to-3D methods have yielded visually appealing outcomes, they often lack sufficient controllability and tend to produce hallucinated regions that may not align with users' expectations. In this paper, we explore an important scenario in which the input consists of one or a few unposed 2D images of a single object, with little or no overlap. We propose a novel method, SpaRP, to reconstruct a 3D textured mesh and estimate the relative camera poses for these sparse-view images. SpaRP distills knowledge from 2D diffusion models and finetunes them to implicitly deduce the 3D spatial relationships between the sparse views. The diffusion model is trained to jointly predict surrogate representations for camera poses and multi-view images of the object under known poses, integrating all information from the input sparse views. These predictions are then leveraged to accomplish 3D reconstruction and pose estimation, and the reconstructed 3D model can be used to further refine the camera poses of input views. Through extensive experiments on three datasets, we demonstrate that our method not only significantly outperforms baseline methods in terms of 3D reconstruction quality and pose prediction accuracy but also exhibits strong efficiency. It requires only about 20 seconds to produce a textured mesh and camera poses for the input views. Project page: https://chaoxu.xyz/sparp.
Generic 3D Diffusion Adapter Using Controlled Multi-View Editing
Mar 19, 2024



Open-domain 3D object synthesis has been lagging behind image synthesis due to limited data and higher computational complexity. To bridge this gap, recent works have investigated multi-view diffusion but often fall short in either 3D consistency, visual quality, or efficiency. This paper proposes MVEdit, which functions as a 3D counterpart of SDEdit, employing ancestral sampling to jointly denoise multi-view images and output high-quality textured meshes. Built on off-the-shelf 2D diffusion models, MVEdit achieves 3D consistency through a training-free 3D Adapter, which lifts the 2D views of the last timestep into a coherent 3D representation, then conditions the 2D views of the next timestep using rendered views, without uncompromising visual quality. With an inference time of only 2-5 minutes, this framework achieves better trade-off between quality and speed than score distillation. MVEdit is highly versatile and extendable, with a wide range of applications including text/image-to-3D generation, 3D-to-3D editing, and high-quality texture synthesis. In particular, evaluations demonstrate state-of-the-art performance in both image-to-3D and text-guided texture generation tasks. Additionally, we introduce a method for fine-tuning 2D latent diffusion models on small 3D datasets with limited resources, enabling fast low-resolution text-to-3D initialization.
Towards Learning Geometric Eigen-Lengths Crucial for Fitting Tasks
Dec 25, 2023Some extremely low-dimensional yet crucial geometric eigen-lengths often determine the success of some geometric tasks. For example, the height of an object is important to measure to check if it can fit between the shelves of a cabinet, while the width of a couch is crucial when trying to move it through a doorway. Humans have materialized such crucial geometric eigen-lengths in common sense since they are very useful in serving as succinct yet effective, highly interpretable, and universal object representations. However, it remains obscure and underexplored if learning systems can be equipped with similar capabilities of automatically discovering such key geometric quantities from doing tasks. In this work, we therefore for the first time formulate and propose a novel learning problem on this question and set up a benchmark suite including tasks, data, and evaluation metrics for studying the problem. We focus on a family of common fitting tasks as the testbed for the proposed learning problem. We explore potential solutions and demonstrate the feasibility of learning eigen-lengths from simply observing successful and failed fitting trials. We also attempt geometric grounding for more accurate eigen-length measurement and study the reusability of the learned eigen-lengths across multiple tasks. Our work marks the first exploratory step toward learning crucial geometric eigen-lengths and we hope it can inspire future research in tackling this important yet underexplored problem.
* ICML 2023. Project page: https://yijiaweng.github.io/geo-eigen-length
PACE: Pose Annotations in Cluttered Environments
Dec 23, 2023Pose estimation is a crucial task in computer vision, enabling tracking and manipulating objects in images or videos. While several datasets exist for pose estimation, there is a lack of large-scale datasets specifically focusing on cluttered scenes with occlusions. This limitation is a bottleneck in the development and evaluation of pose estimation methods, particularly toward the goal of real-world application in environments where occlusions are common. Addressing this, we introduce PACE (Pose Annotations in Cluttered Environments), a large-scale benchmark designed to advance the development and evaluation of pose estimation methods in cluttered scenarios. PACE encompasses 54,945 frames with 257,673 annotations across 300 videos, covering 576 objects from 44 categories and featuring a mix of rigid and articulated items in cluttered scenes. To annotate the real-world data efficiently, we developed an innovative annotation system utilizing a calibrated 3-camera setup. We test state-of-the-art algorithms in PACE along two tracks: pose estimation, and object pose tracking, revealing the benchmark's challenges and research opportunities. We plan to release PACE as a public evaluation benchmark, along the annotations tools we developed, to stimulate further advancements in the field. Our code and data is available on https://github.com/qq456cvb/PACE.
ZeroRF: Fast Sparse View 360° Reconstruction with Zero Pretraining
Dec 14, 2023


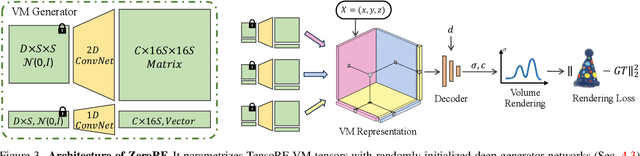
We present ZeroRF, a novel per-scene optimization method addressing the challenge of sparse view 360{\deg} reconstruction in neural field representations. Current breakthroughs like Neural Radiance Fields (NeRF) have demonstrated high-fidelity image synthesis but struggle with sparse input views. Existing methods, such as Generalizable NeRFs and per-scene optimization approaches, face limitations in data dependency, computational cost, and generalization across diverse scenarios. To overcome these challenges, we propose ZeroRF, whose key idea is to integrate a tailored Deep Image Prior into a factorized NeRF representation. Unlike traditional methods, ZeroRF parametrizes feature grids with a neural network generator, enabling efficient sparse view 360{\deg} reconstruction without any pretraining or additional regularization. Extensive experiments showcase ZeroRF's versatility and superiority in terms of both quality and speed, achieving state-of-the-art results on benchmark datasets. ZeroRF's significance extends to applications in 3D content generation and editing. Project page: https://sarahweiii.github.io/zerorf/
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023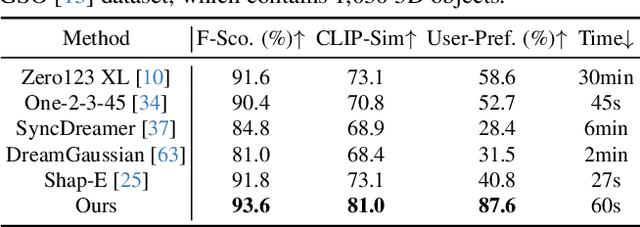
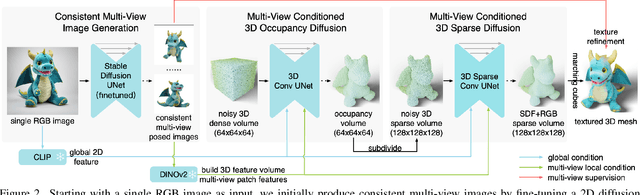
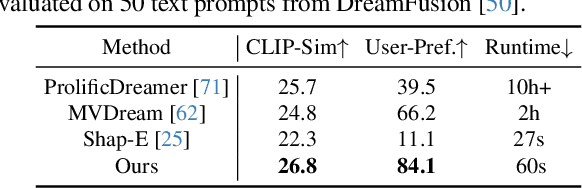
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
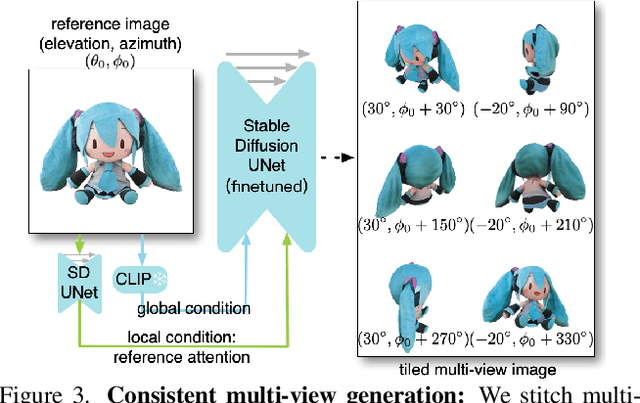
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Oct 23, 2023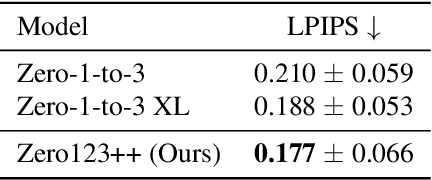
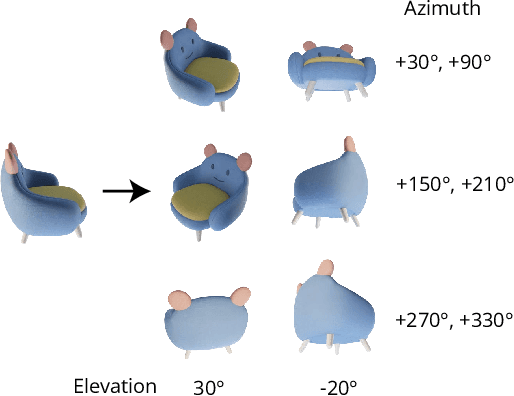

We report Zero123++, an image-conditioned diffusion model for generating 3D-consistent multi-view images from a single input view. To take full advantage of pretrained 2D generative priors, we develop various conditioning and training schemes to minimize the effort of finetuning from off-the-shelf image diffusion models such as Stable Diffusion. Zero123++ excels in producing high-quality, consistent multi-view images from a single image, overcoming common issues like texture degradation and geometric misalignment. Furthermore, we showcase the feasibility of training a ControlNet on Zero123++ for enhanced control over the generation process. The code is available at https://github.com/SUDO-AI-3D/zero123plus.