 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLARM: A Large Articulated-Object Reconstruction Model
Nov 14, 2025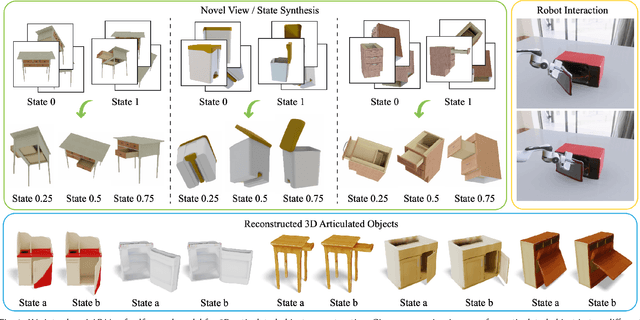
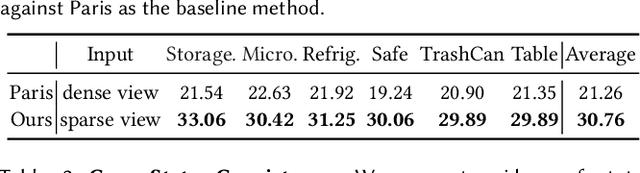


Modeling 3D articulated objects with realistic geometry, textures, and kinematics is essential for a wide range of applications. However, existing optimization-based reconstruction methods often require dense multi-view inputs and expensive per-instance optimization, limiting their scalability. Recent feedforward approaches offer faster alternatives but frequently produce coarse geometry, lack texture reconstruction, and rely on brittle, complex multi-stage pipelines. We introduce LARM, a unified feedforward framework that reconstructs 3D articulated objects from sparse-view images by jointly recovering detailed geometry, realistic textures, and accurate joint structures. LARM extends LVSM a recent novel view synthesis (NVS) approach for static 3D objects into the articulated setting by jointly reasoning over camera pose and articulation variation using a transformer-based architecture, enabling scalable and accurate novel view synthesis. In addition, LARM generates auxiliary outputs such as depth maps and part masks to facilitate explicit 3D mesh extraction and joint estimation. Our pipeline eliminates the need for dense supervision and supports high-fidelity reconstruction across diverse object categories. Extensive experiments demonstrate that LARM outperforms state-of-the-art methods in both novel view and state synthesis as well as 3D articulated object reconstruction, generating high-quality meshes that closely adhere to the input images. project page: https://sylviayuan-sy.github.io/larm-site/
FreeArt3D: Training-Free Articulated Object Generation using 3D Diffusion
Oct 29, 2025Articulated 3D objects are central to many applications in robotics, AR/VR, and animation. Recent approaches to modeling such objects either rely on optimization-based reconstruction pipelines that require dense-view supervision or on feed-forward generative models that produce coarse geometric approximations and often overlook surface texture. In contrast, open-world 3D generation of static objects has achieved remarkable success, especially with the advent of native 3D diffusion models such as Trellis. However, extending these methods to articulated objects by training native 3D diffusion models poses significant challenges. In this work, we present FreeArt3D, a training-free framework for articulated 3D object generation. Instead of training a new model on limited articulated data, FreeArt3D repurposes a pre-trained static 3D diffusion model (e.g., Trellis) as a powerful shape prior. It extends Score Distillation Sampling (SDS) into the 3D-to-4D domain by treating articulation as an additional generative dimension. Given a few images captured in different articulation states, FreeArt3D jointly optimizes the object's geometry, texture, and articulation parameters without requiring task-specific training or access to large-scale articulated datasets. Our method generates high-fidelity geometry and textures, accurately predicts underlying kinematic structures, and generalizes well across diverse object categories. Despite following a per-instance optimization paradigm, FreeArt3D completes in minutes and significantly outperforms prior state-of-the-art approaches in both quality and versatility.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024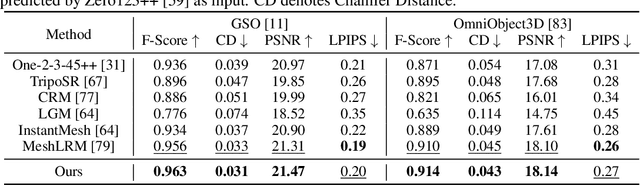
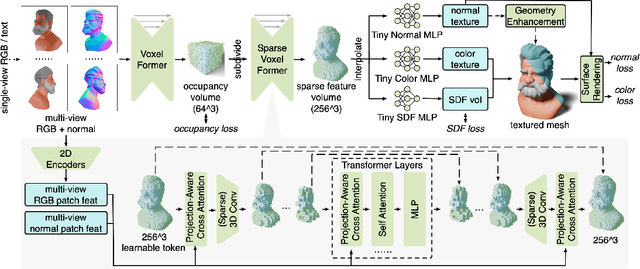


Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Apr 18, 2024



We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
ZeroRF: Fast Sparse View 360° Reconstruction with Zero Pretraining
Dec 14, 2023


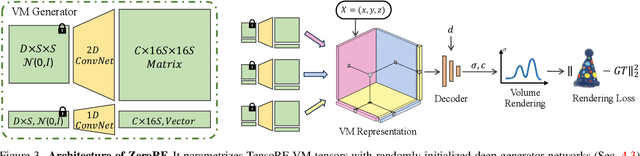
We present ZeroRF, a novel per-scene optimization method addressing the challenge of sparse view 360{\deg} reconstruction in neural field representations. Current breakthroughs like Neural Radiance Fields (NeRF) have demonstrated high-fidelity image synthesis but struggle with sparse input views. Existing methods, such as Generalizable NeRFs and per-scene optimization approaches, face limitations in data dependency, computational cost, and generalization across diverse scenarios. To overcome these challenges, we propose ZeroRF, whose key idea is to integrate a tailored Deep Image Prior into a factorized NeRF representation. Unlike traditional methods, ZeroRF parametrizes feature grids with a neural network generator, enabling efficient sparse view 360{\deg} reconstruction without any pretraining or additional regularization. Extensive experiments showcase ZeroRF's versatility and superiority in terms of both quality and speed, achieving state-of-the-art results on benchmark datasets. ZeroRF's significance extends to applications in 3D content generation and editing. Project page: https://sarahweiii.github.io/zerorf/
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023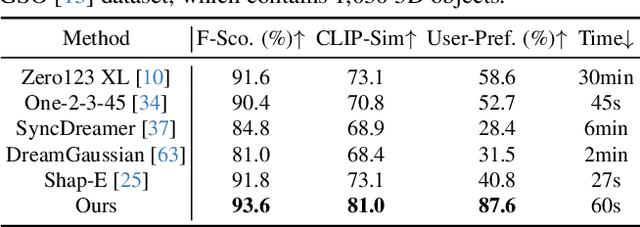
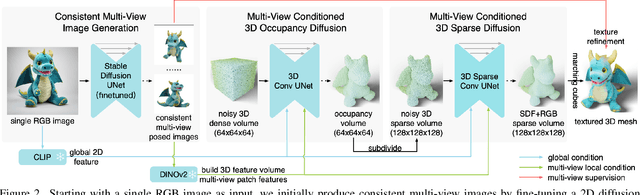
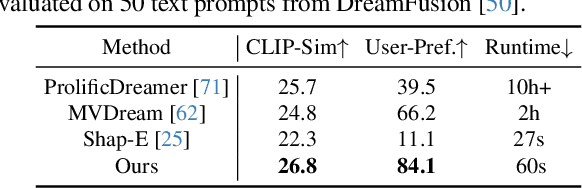
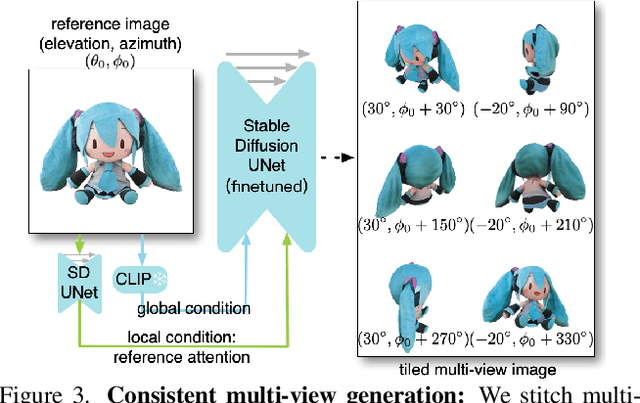
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
Oct 23, 2023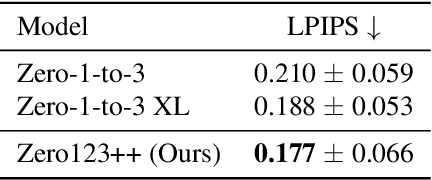
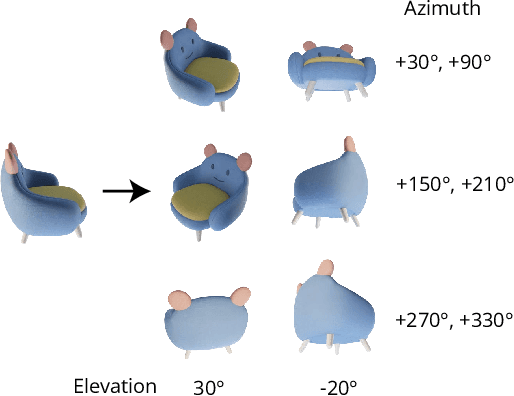
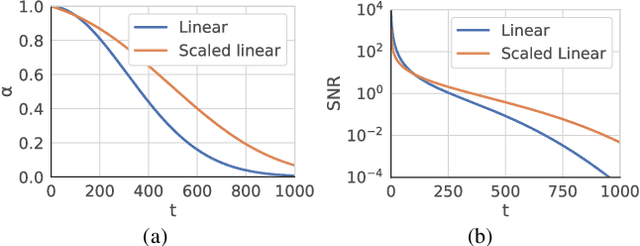

We report Zero123++, an image-conditioned diffusion model for generating 3D-consistent multi-view images from a single input view. To take full advantage of pretrained 2D generative priors, we develop various conditioning and training schemes to minimize the effort of finetuning from off-the-shelf image diffusion models such as Stable Diffusion. Zero123++ excels in producing high-quality, consistent multi-view images from a single image, overcoming common issues like texture degradation and geometric misalignment. Furthermore, we showcase the feasibility of training a ControlNet on Zero123++ for enhanced control over the generation process. The code is available at https://github.com/SUDO-AI-3D/zero123plus.
NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support
May 26, 2023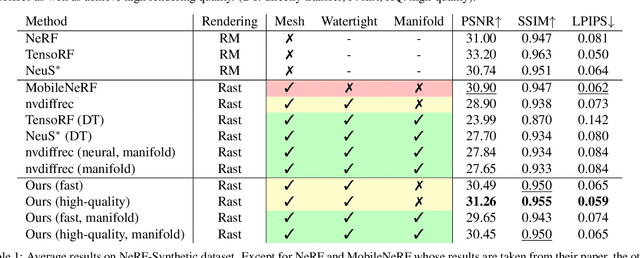
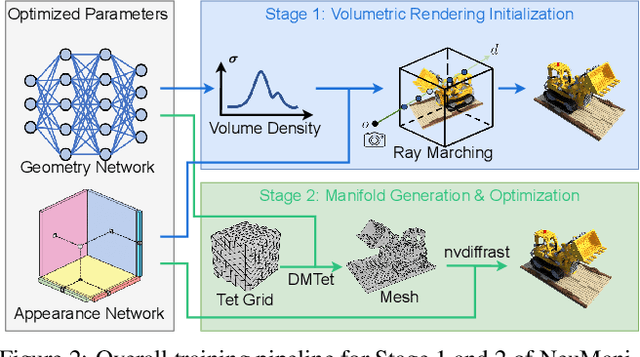


We present a method for generating high-quality watertight manifold meshes from multi-view input images. Existing volumetric rendering methods are robust in optimization but tend to generate noisy meshes with poor topology. Differentiable rasterization-based methods can generate high-quality meshes but are sensitive to initialization. Our method combines the benefits of both worlds; we take the geometry initialization obtained from neural volumetric fields, and further optimize the geometry as well as a compact neural texture representation with differentiable rasterizers. Through extensive experiments, we demonstrate that our method can generate accurate mesh reconstructions with faithful appearance that are comparable to previous volume rendering methods while being an order of magnitude faster in rendering. We also show that our generated mesh and neural texture reconstruction is compatible with existing graphics pipelines and enables downstream 3D applications such as simulation. Project page: https://sarahweiii.github.io/neumanifold/
ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills
Feb 09, 2023Generalizable manipulation skills, which can be composed to tackle long-horizon and complex daily chores, are one of the cornerstones of Embodied AI. However, existing benchmarks, mostly composed of a suite of simulatable environments, are insufficient to push cutting-edge research works because they lack object-level topological and geometric variations, are not based on fully dynamic simulation, or are short of native support for multiple types of manipulation tasks. To this end, we present ManiSkill2, the next generation of the SAPIEN ManiSkill benchmark, to address critical pain points often encountered by researchers when using benchmarks for generalizable manipulation skills. ManiSkill2 includes 20 manipulation task families with 2000+ object models and 4M+ demonstration frames, which cover stationary/mobile-base, single/dual-arm, and rigid/soft-body manipulation tasks with 2D/3D-input data simulated by fully dynamic engines. It defines a unified interface and evaluation protocol to support a wide range of algorithms (e.g., classic sense-plan-act, RL, IL), visual observations (point cloud, RGBD), and controllers (e.g., action type and parameterization). Moreover, it empowers fast visual input learning algorithms so that a CNN-based policy can collect samples at about 2000 FPS with 1 GPU and 16 processes on a regular workstation. It implements a render server infrastructure to allow sharing rendering resources across all environments, thereby significantly reducing memory usage. We open-source all codes of our benchmark (simulator, environments, and baselines) and host an online challenge open to interdisciplinary researchers.