 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-RayZer: Self-supervised 3D Reconstruction as Spatial Visual Pre-training
Dec 11, 2025



Self-supervised pre-training has revolutionized foundation models for languages, individual 2D images and videos, but remains largely unexplored for learning 3D-aware representations from multi-view images. In this paper, we present E-RayZer, a self-supervised large 3D Vision model that learns truly 3D-aware representations directly from unlabeled images. Unlike prior self-supervised methods such as RayZer that infer 3D indirectly through latent-space view synthesis, E-RayZer operates directly in 3D space, performing self-supervised 3D reconstruction with Explicit geometry. This formulation eliminates shortcut solutions and yields representations that are geometrically grounded. To ensure convergence and scalability, we introduce a novel fine-grained learning curriculum that organizes training from easy to hard samples and harmonizes heterogeneous data sources in an entirely unsupervised manner. Experiments demonstrate that E-RayZer significantly outperforms RayZer on pose estimation, matches or sometimes surpasses fully supervised reconstruction models such as VGGT. Furthermore, its learned representations outperform leading visual pre-training models (e.g., DINOv3, CroCo v2, VideoMAE V2, and RayZer) when transferring to 3D downstream tasks, establishing E-RayZer as a new paradigm for 3D-aware visual pre-training.
4D-LRM: Large Space-Time Reconstruction Model From and To Any View at Any Time
Jun 23, 2025Can we scale 4D pretraining to learn general space-time representations that reconstruct an object from a few views at some times to any view at any time? We provide an affirmative answer with 4D-LRM, the first large-scale 4D reconstruction model that takes input from unconstrained views and timestamps and renders arbitrary novel view-time combinations. Unlike prior 4D approaches, e.g., optimization-based, geometry-based, or generative, that struggle with efficiency, generalization, or faithfulness, 4D-LRM learns a unified space-time representation and directly predicts per-pixel 4D Gaussian primitives from posed image tokens across time, enabling fast, high-quality rendering at, in principle, infinite frame rate. Our results demonstrate that scaling spatiotemporal pretraining enables accurate and efficient 4D reconstruction. We show that 4D-LRM generalizes to novel objects, interpolates across time, and handles diverse camera setups. It reconstructs 24-frame sequences in one forward pass with less than 1.5 seconds on a single A100 GPU.
Test-Time Training Done Right
May 29, 2025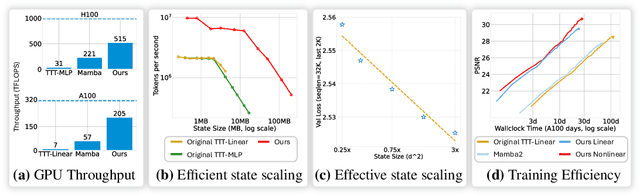

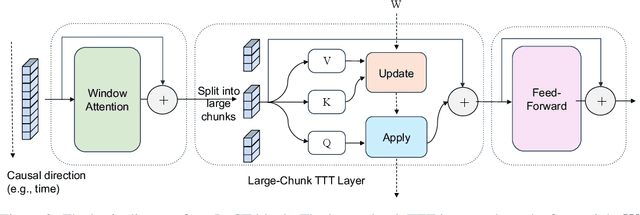
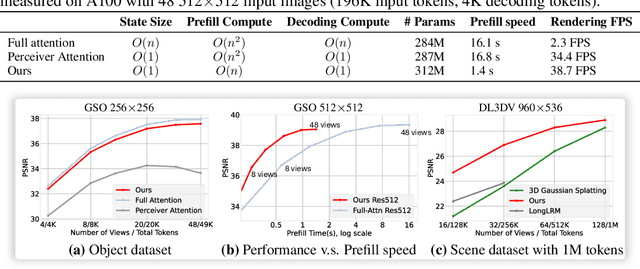
Test-Time Training (TTT) models context dependencies by adapting part of the model's weights (referred to as fast weights) during inference. This fast weight, akin to recurrent states in RNNs, stores temporary memories of past tokens in the current sequence. Existing TTT methods struggled to show effectiveness in handling long-context data, due to their inefficiency on modern GPUs. The TTT layers in many of these approaches operate with extremely low FLOPs utilization (often <5%) because they deliberately apply small online minibatch sizes (e.g., updating fast weights every 16 or 64 tokens). Moreover, a small minibatch implies fine-grained block-wise causal dependencies in the data, unsuitable for data beyond 1D ordered sequences, like sets or N-dimensional grids such as images or videos. In contrast, we pursue the opposite direction by using an extremely large chunk update, ranging from 2K to 1M tokens across tasks of varying modalities, which we refer to as Large Chunk Test-Time Training (LaCT). It improves hardware utilization by orders of magnitude, and more importantly, facilitates scaling of nonlinear state size (up to 40% of model parameters), hence substantially improving state capacity, all without requiring cumbersome and error-prone kernel implementations. It also allows easy integration of sophisticated optimizers, e.g. Muon for online updates. We validate our approach across diverse modalities and tasks, including novel view synthesis with image set, language models, and auto-regressive video diffusion. Our approach can scale up to 14B-parameter AR video diffusion model on sequences up to 56K tokens. In our longest sequence experiment, we perform novel view synthesis with 1 million context length. We hope this work will inspire and accelerate new research in the field of long-context modeling and test-time training. Website: https://tianyuanzhang.com/projects/ttt-done-right
RayZer: A Self-supervised Large View Synthesis Model
May 01, 2025



We present RayZer, a self-supervised multi-view 3D Vision model trained without any 3D supervision, i.e., camera poses and scene geometry, while exhibiting emerging 3D awareness. Concretely, RayZer takes unposed and uncalibrated images as input, recovers camera parameters, reconstructs a scene representation, and synthesizes novel views. During training, RayZer relies solely on its self-predicted camera poses to render target views, eliminating the need for any ground-truth camera annotations and allowing RayZer to be trained with 2D image supervision. The emerging 3D awareness of RayZer is attributed to two key factors. First, we design a self-supervised framework, which achieves 3D-aware auto-encoding of input images by disentangling camera and scene representations. Second, we design a transformer-based model in which the only 3D prior is the ray structure, connecting camera, pixel, and scene simultaneously. RayZer demonstrates comparable or even superior novel view synthesis performance than ``oracle'' methods that rely on pose annotations in both training and testing. Project: https://hwjiang1510.github.io/RayZer/
Neural Directional Encoding for Efficient and Accurate View-Dependent Appearance Modeling
May 23, 2024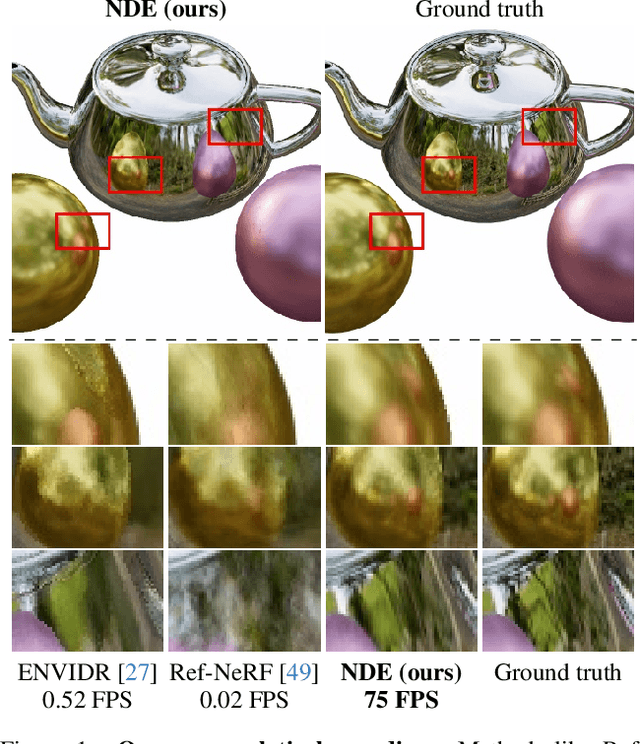
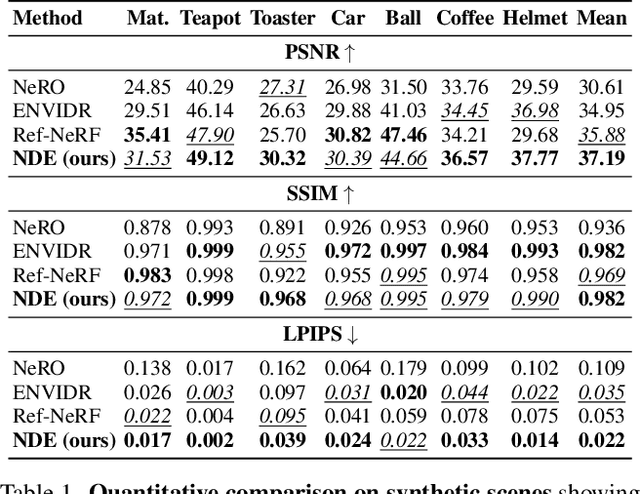
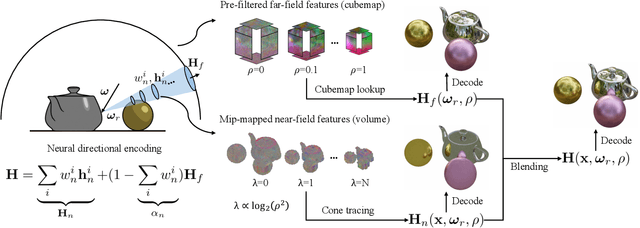
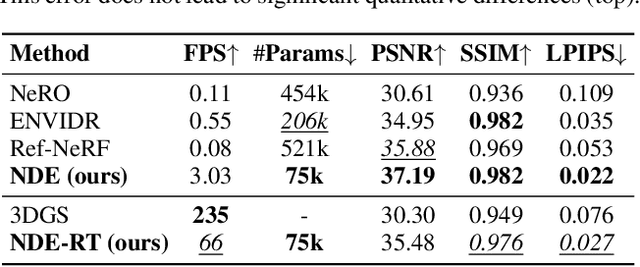
Novel-view synthesis of specular objects like shiny metals or glossy paints remains a significant challenge. Not only the glossy appearance but also global illumination effects, including reflections of other objects in the environment, are critical components to faithfully reproduce a scene. In this paper, we present Neural Directional Encoding (NDE), a view-dependent appearance encoding of neural radiance fields (NeRF) for rendering specular objects. NDE transfers the concept of feature-grid-based spatial encoding to the angular domain, significantly improving the ability to model high-frequency angular signals. In contrast to previous methods that use encoding functions with only angular input, we additionally cone-trace spatial features to obtain a spatially varying directional encoding, which addresses the challenging interreflection effects. Extensive experiments on both synthetic and real datasets show that a NeRF model with NDE (1) outperforms the state of the art on view synthesis of specular objects, and (2) works with small networks to allow fast (real-time) inference. The project webpage and source code are available at: \url{https://lwwu2.github.io/nde/}.
GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Apr 30, 2024

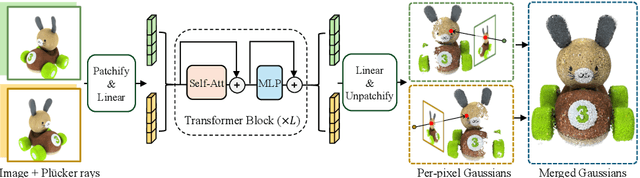
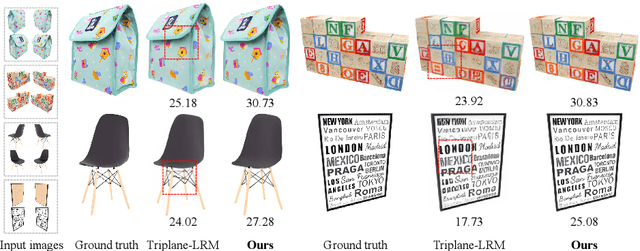
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
MeshLRM: Large Reconstruction Model for High-Quality Mesh
Apr 18, 2024



We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
LightIt: Illumination Modeling and Control for Diffusion Models
Mar 25, 2024We introduce LightIt, a method for explicit illumination control for image generation. Recent generative methods lack lighting control, which is crucial to numerous artistic aspects of image generation such as setting the overall mood or cinematic appearance. To overcome these limitations, we propose to condition the generation on shading and normal maps. We model the lighting with single bounce shading, which includes cast shadows. We first train a shading estimation module to generate a dataset of real-world images and shading pairs. Then, we train a control network using the estimated shading and normals as input. Our method demonstrates high-quality image generation and lighting control in numerous scenes. Additionally, we use our generated dataset to train an identity-preserving relighting model, conditioned on an image and a target shading. Our method is the first that enables the generation of images with controllable, consistent lighting and performs on par with specialized relighting state-of-the-art methods.
PF-LRM: Pose-Free Large Reconstruction Model for Joint Pose and Shape Prediction
Nov 23, 2023


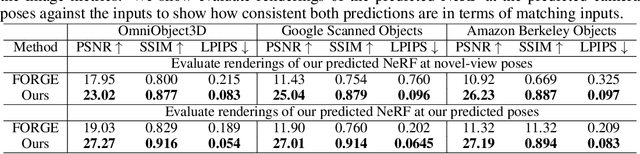
We propose a Pose-Free Large Reconstruction Model (PF-LRM) for reconstructing a 3D object from a few unposed images even with little visual overlap, while simultaneously estimating the relative camera poses in ~1.3 seconds on a single A100 GPU. PF-LRM is a highly scalable method utilizing the self-attention blocks to exchange information between 3D object tokens and 2D image tokens; we predict a coarse point cloud for each view, and then use a differentiable Perspective-n-Point (PnP) solver to obtain camera poses. When trained on a huge amount of multi-view posed data of ~1M objects, PF-LRM shows strong cross-dataset generalization ability, and outperforms baseline methods by a large margin in terms of pose prediction accuracy and 3D reconstruction quality on various unseen evaluation datasets. We also demonstrate our model's applicability in downstream text/image-to-3D task with fast feed-forward inference. Our project website is at: https://totoro97.github.io/pf-lrm .
Instant3D: Fast Text-to-3D with Sparse-View Generation and Large Reconstruction Model
Nov 23, 2023

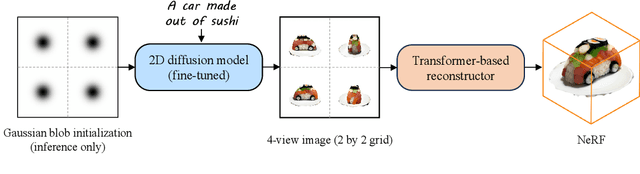
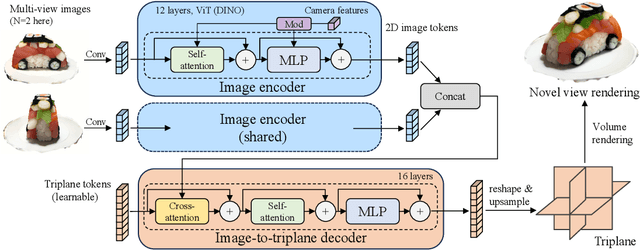
Text-to-3D with diffusion models has achieved remarkable progress in recent years. However, existing methods either rely on score distillation-based optimization which suffer from slow inference, low diversity and Janus problems, or are feed-forward methods that generate low-quality results due to the scarcity of 3D training data. In this paper, we propose Instant3D, a novel method that generates high-quality and diverse 3D assets from text prompts in a feed-forward manner. We adopt a two-stage paradigm, which first generates a sparse set of four structured and consistent views from text in one shot with a fine-tuned 2D text-to-image diffusion model, and then directly regresses the NeRF from the generated images with a novel transformer-based sparse-view reconstructor. Through extensive experiments, we demonstrate that our method can generate diverse 3D assets of high visual quality within 20 seconds, which is two orders of magnitude faster than previous optimization-based methods that can take 1 to 10 hours. Our project webpage: https://jiahao.ai/instant3d/.