 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Paper and Code


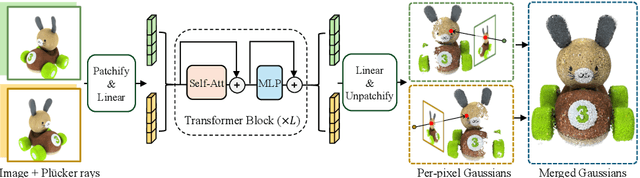
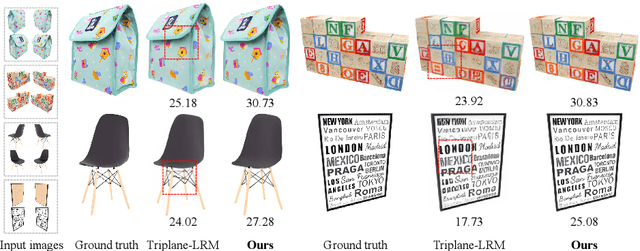
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .