 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurbo-GS: Accelerating 3D Gaussian Fitting for High-Quality Radiance Fields
Dec 18, 2024



Novel-view synthesis is an important problem in computer vision with applications in 3D reconstruction, mixed reality, and robotics. Recent methods like 3D Gaussian Splatting (3DGS) have become the preferred method for this task, providing high-quality novel views in real time. However, the training time of a 3DGS model is slow, often taking 30 minutes for a scene with 200 views. In contrast, our goal is to reduce the optimization time by training for fewer steps while maintaining high rendering quality. Specifically, we combine the guidance from both the position error and the appearance error to achieve a more effective densification. To balance the rate between adding new Gaussians and fitting old Gaussians, we develop a convergence-aware budget control mechanism. Moreover, to make the densification process more reliable, we selectively add new Gaussians from mostly visited regions. With these designs, we reduce the Gaussian optimization steps to one-third of the previous approach while achieving a comparable or even better novel view rendering quality. To further facilitate the rapid fitting of 4K resolution images, we introduce a dilation-based rendering technique. Our method, Turbo-GS, speeds up optimization for typical scenes and scales well to high-resolution (4K) scenarios on standard datasets. Through extensive experiments, we show that our method is significantly faster in optimization than other methods while retaining quality. Project page: https://ivl.cs.brown.edu/research/turbo-gs.
Proc-GS: Procedural Building Generation for City Assembly with 3D Gaussians
Dec 10, 2024



Buildings are primary components of cities, often featuring repeated elements such as windows and doors. Traditional 3D building asset creation is labor-intensive and requires specialized skills to develop design rules. Recent generative models for building creation often overlook these patterns, leading to low visual fidelity and limited scalability. Drawing inspiration from procedural modeling techniques used in the gaming and visual effects industry, our method, Proc-GS, integrates procedural code into the 3D Gaussian Splatting (3D-GS) framework, leveraging their advantages in high-fidelity rendering and efficient asset management from both worlds. By manipulating procedural code, we can streamline this process and generate an infinite variety of buildings. This integration significantly reduces model size by utilizing shared foundational assets, enabling scalable generation with precise control over building assembly. We showcase the potential for expansive cityscape generation while maintaining high rendering fidelity and precise control on both real and synthetic cases.
Doppelgangers++: Improved Visual Disambiguation with Geometric 3D Features
Dec 08, 2024



Accurate 3D reconstruction is frequently hindered by visual aliasing, where visually similar but distinct surfaces (aka, doppelgangers), are incorrectly matched. These spurious matches distort the structure-from-motion (SfM) process, leading to misplaced model elements and reduced accuracy. Prior efforts addressed this with CNN classifiers trained on curated datasets, but these approaches struggle to generalize across diverse real-world scenes and can require extensive parameter tuning. In this work, we present Doppelgangers++, a method to enhance doppelganger detection and improve 3D reconstruction accuracy. Our contributions include a diversified training dataset that incorporates geo-tagged images from everyday scenes to expand robustness beyond landmark-based datasets. We further propose a Transformer-based classifier that leverages 3D-aware features from the MASt3R model, achieving superior precision and recall across both in-domain and out-of-domain tests. Doppelgangers++ integrates seamlessly into standard SfM and MASt3R-SfM pipelines, offering efficiency and adaptability across varied scenes. To evaluate SfM accuracy, we introduce an automated, geotag-based method for validating reconstructed models, eliminating the need for manual inspection. Through extensive experiments, we demonstrate that Doppelgangers++ significantly enhances pairwise visual disambiguation and improves 3D reconstruction quality in complex and diverse scenarios.
Neural Gaffer: Relighting Any Object via Diffusion
Jun 11, 2024



Single-image relighting is a challenging task that involves reasoning about the complex interplay between geometry, materials, and lighting. Many prior methods either support only specific categories of images, such as portraits, or require special capture conditions, like using a flashlight. Alternatively, some methods explicitly decompose a scene into intrinsic components, such as normals and BRDFs, which can be inaccurate or under-expressive. In this work, we propose a novel end-to-end 2D relighting diffusion model, called Neural Gaffer, that takes a single image of any object and can synthesize an accurate, high-quality relit image under any novel environmental lighting condition, simply by conditioning an image generator on a target environment map, without an explicit scene decomposition. Our method builds on a pre-trained diffusion model, and fine-tunes it on a synthetic relighting dataset, revealing and harnessing the inherent understanding of lighting present in the diffusion model. We evaluate our model on both synthetic and in-the-wild Internet imagery and demonstrate its advantages in terms of generalization and accuracy. Moreover, by combining with other generative methods, our model enables many downstream 2D tasks, such as text-based relighting and object insertion. Our model can also operate as a strong relighting prior for 3D tasks, such as relighting a radiance field.
GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Apr 30, 2024

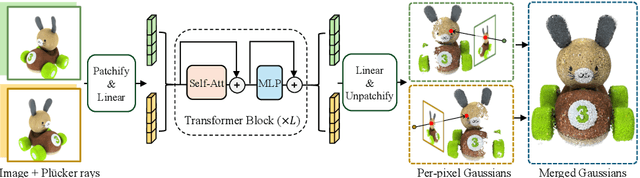
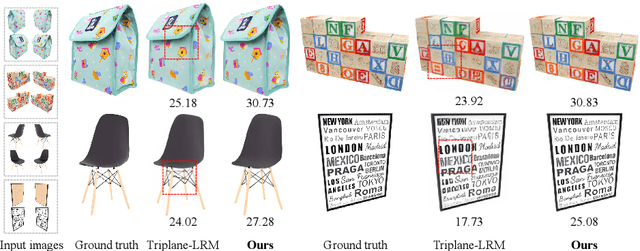
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
GSDF: 3DGS Meets SDF for Improved Rendering and Reconstruction
Mar 25, 2024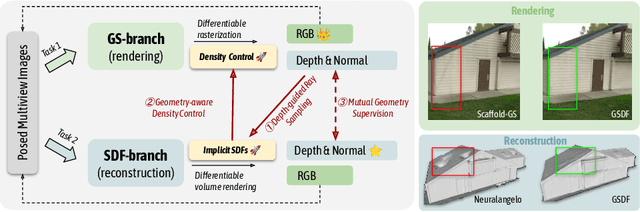
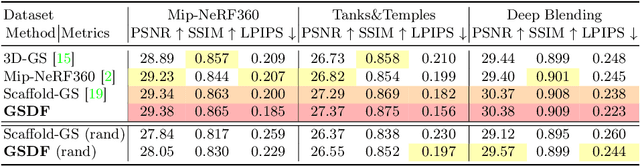
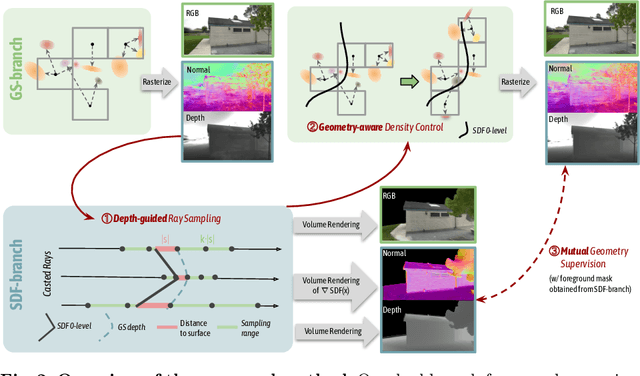

Presenting a 3D scene from multiview images remains a core and long-standing challenge in computer vision and computer graphics. Two main requirements lie in rendering and reconstruction. Notably, SOTA rendering quality is usually achieved with neural volumetric rendering techniques, which rely on aggregated point/primitive-wise color and neglect the underlying scene geometry. Learning of neural implicit surfaces is sparked from the success of neural rendering. Current works either constrain the distribution of density fields or the shape of primitives, resulting in degraded rendering quality and flaws on the learned scene surfaces. The efficacy of such methods is limited by the inherent constraints of the chosen neural representation, which struggles to capture fine surface details, especially for larger, more intricate scenes. To address these issues, we introduce GSDF, a novel dual-branch architecture that combines the benefits of a flexible and efficient 3D Gaussian Splatting (3DGS) representation with neural Signed Distance Fields (SDF). The core idea is to leverage and enhance the strengths of each branch while alleviating their limitation through mutual guidance and joint supervision. We show on diverse scenes that our design unlocks the potential for more accurate and detailed surface reconstructions, and at the meantime benefits 3DGS rendering with structures that are more aligned with the underlying geometry.
Scaffold-GS: Structured 3D Gaussians for View-Adaptive Rendering
Nov 30, 2023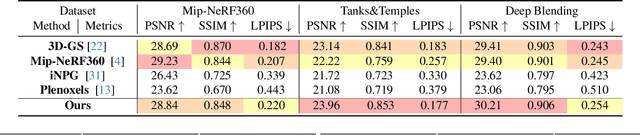

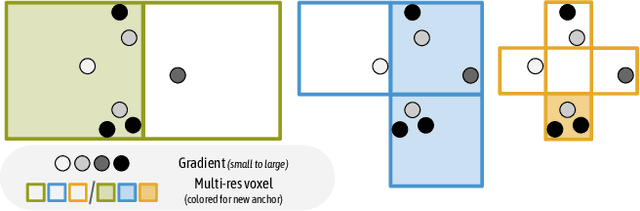

Neural rendering methods have significantly advanced photo-realistic 3D scene rendering in various academic and industrial applications. The recent 3D Gaussian Splatting method has achieved the state-of-the-art rendering quality and speed combining the benefits of both primitive-based representations and volumetric representations. However, it often leads to heavily redundant Gaussians that try to fit every training view, neglecting the underlying scene geometry. Consequently, the resulting model becomes less robust to significant view changes, texture-less area and lighting effects. We introduce Scaffold-GS, which uses anchor points to distribute local 3D Gaussians, and predicts their attributes on-the-fly based on viewing direction and distance within the view frustum. Anchor growing and pruning strategies are developed based on the importance of neural Gaussians to reliably improve the scene coverage. We show that our method effectively reduces redundant Gaussians while delivering high-quality rendering. We also demonstrates an enhanced capability to accommodate scenes with varying levels-of-detail and view-dependent observations, without sacrificing the rendering speed.
MatrixCity: A Large-scale City Dataset for City-scale Neural Rendering and Beyond
Sep 28, 2023



Neural radiance fields (NeRF) and its subsequent variants have led to remarkable progress in neural rendering. While most of recent neural rendering works focus on objects and small-scale scenes, developing neural rendering methods for city-scale scenes is of great potential in many real-world applications. However, this line of research is impeded by the absence of a comprehensive and high-quality dataset, yet collecting such a dataset over real city-scale scenes is costly, sensitive, and technically difficult. To this end, we build a large-scale, comprehensive, and high-quality synthetic dataset for city-scale neural rendering researches. Leveraging the Unreal Engine 5 City Sample project, we develop a pipeline to easily collect aerial and street city views, accompanied by ground-truth camera poses and a range of additional data modalities. Flexible controls over environmental factors like light, weather, human and car crowd are also available in our pipeline, supporting the need of various tasks covering city-scale neural rendering and beyond. The resulting pilot dataset, MatrixCity, contains 67k aerial images and 452k street images from two city maps of total size $28km^2$. On top of MatrixCity, a thorough benchmark is also conducted, which not only reveals unique challenges of the task of city-scale neural rendering, but also highlights potential improvements for future works. The dataset and code will be publicly available at our project page: https://city-super.github.io/matrixcity/.
Grid-guided Neural Radiance Fields for Large Urban Scenes
Mar 24, 2023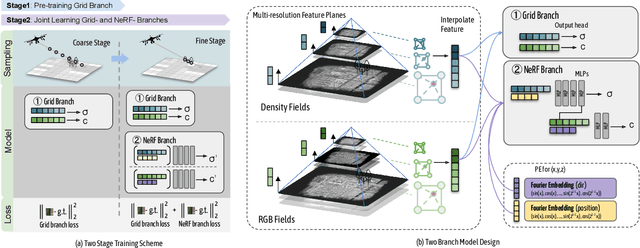

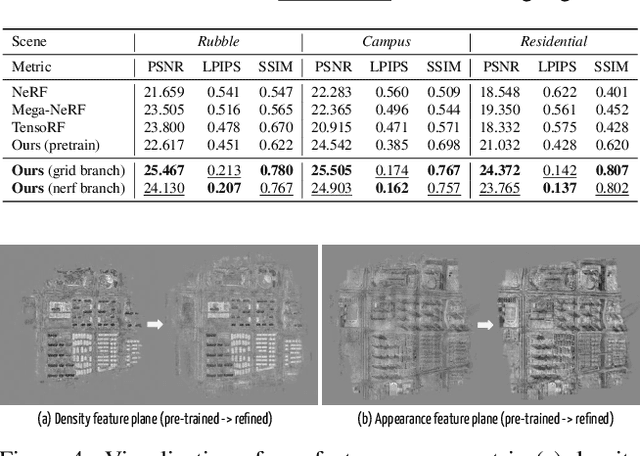

Purely MLP-based neural radiance fields (NeRF-based methods) often suffer from underfitting with blurred renderings on large-scale scenes due to limited model capacity. Recent approaches propose to geographically divide the scene and adopt multiple sub-NeRFs to model each region individually, leading to linear scale-up in training costs and the number of sub-NeRFs as the scene expands. An alternative solution is to use a feature grid representation, which is computationally efficient and can naturally scale to a large scene with increased grid resolutions. However, the feature grid tends to be less constrained and often reaches suboptimal solutions, producing noisy artifacts in renderings, especially in regions with complex geometry and texture. In this work, we present a new framework that realizes high-fidelity rendering on large urban scenes while being computationally efficient. We propose to use a compact multiresolution ground feature plane representation to coarsely capture the scene, and complement it with positional encoding inputs through another NeRF branch for rendering in a joint learning fashion. We show that such an integration can utilize the advantages of two alternative solutions: a light-weighted NeRF is sufficient, under the guidance of the feature grid representation, to render photorealistic novel views with fine details; and the jointly optimized ground feature planes, can meanwhile gain further refinements, forming a more accurate and compact feature space and output much more natural rendering results.
AssetField: Assets Mining and Reconfiguration in Ground Feature Plane Representation
Mar 24, 2023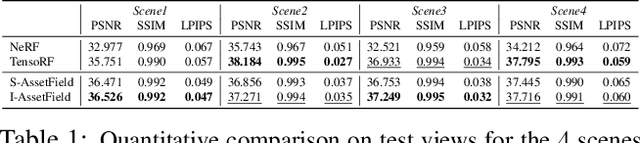

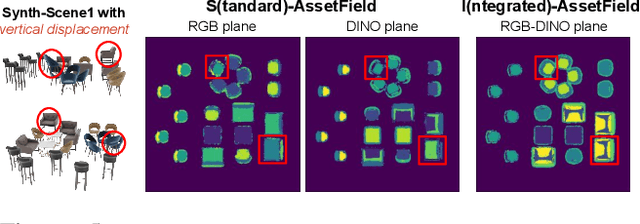

Both indoor and outdoor environments are inherently structured and repetitive. Traditional modeling pipelines keep an asset library storing unique object templates, which is both versatile and memory efficient in practice. Inspired by this observation, we propose AssetField, a novel neural scene representation that learns a set of object-aware ground feature planes to represent the scene, where an asset library storing template feature patches can be constructed in an unsupervised manner. Unlike existing methods which require object masks to query spatial points for object editing, our ground feature plane representation offers a natural visualization of the scene in the bird-eye view, allowing a variety of operations (e.g. translation, duplication, deformation) on objects to configure a new scene. With the template feature patches, group editing is enabled for scenes with many recurring items to avoid repetitive work on object individuals. We show that AssetField not only achieves competitive performance for novel-view synthesis but also generates realistic renderings for new scene configurations.