 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePnP-U3D: Plug-and-Play 3D Framework Bridging Autoregression and Diffusion for Unified Understanding and Generation
Feb 03, 2026The rapid progress of large multimodal models has inspired efforts toward unified frameworks that couple understanding and generation. While such paradigms have shown remarkable success in 2D, extending them to 3D remains largely underexplored. Existing attempts to unify 3D tasks under a single autoregressive (AR) paradigm lead to significant performance degradation due to forced signal quantization and prohibitive training cost. Our key insight is that the essential challenge lies not in enforcing a unified autoregressive paradigm, but in enabling effective information interaction between generation and understanding while minimally compromising their inherent capabilities and leveraging pretrained models to reduce training cost. Guided by this perspective, we present the first unified framework for 3D understanding and generation that combines autoregression with diffusion. Specifically, we adopt an autoregressive next-token prediction paradigm for 3D understanding, and a continuous diffusion paradigm for 3D generation. A lightweight transformer bridges the feature space of large language models and the conditional space of 3D diffusion models, enabling effective cross-modal information exchange while preserving the priors learned by standalone models. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across diverse 3D understanding and generation benchmarks, while also excelling in 3D editing tasks. These results highlight the potential of unified AR+diffusion models as a promising direction for building more general-purpose 3D intelligence.
PI-Light: Physics-Inspired Diffusion for Full-Image Relighting
Jan 29, 2026Full-image relighting remains a challenging problem due to the difficulty of collecting large-scale structured paired data, the difficulty of maintaining physical plausibility, and the limited generalizability imposed by data-driven priors. Existing attempts to bridge the synthetic-to-real gap for full-scene relighting remain suboptimal. To tackle these challenges, we introduce Physics-Inspired diffusion for full-image reLight ($π$-Light, or PI-Light), a two-stage framework that leverages physics-inspired diffusion models. Our design incorporates (i) batch-aware attention, which improves the consistency of intrinsic predictions across a collection of images, (ii) a physics-guided neural rendering module that enforces physically plausible light transport, (iii) physics-inspired losses that regularize training dynamics toward a physically meaningful landscape, thereby enhancing generalizability to real-world image editing, and (iv) a carefully curated dataset of diverse objects and scenes captured under controlled lighting conditions. Together, these components enable efficient finetuning of pretrained diffusion models while also providing a solid benchmark for downstream evaluation. Experiments demonstrate that $π$-Light synthesizes specular highlights and diffuse reflections across a wide variety of materials, achieving superior generalization to real-world scenes compared with prior approaches.
StoryMem: Multi-shot Long Video Storytelling with Memory
Dec 22, 2025
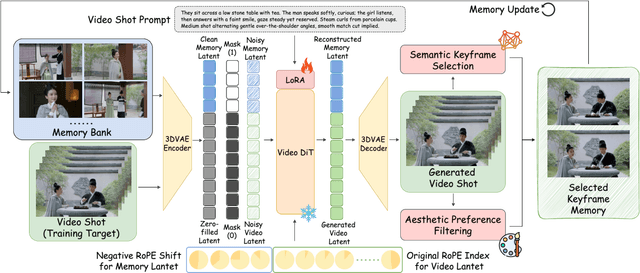

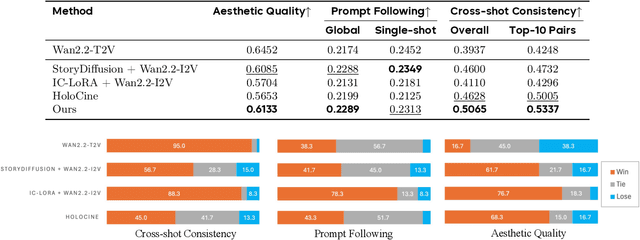
Visual storytelling requires generating multi-shot videos with cinematic quality and long-range consistency. Inspired by human memory, we propose StoryMem, a paradigm that reformulates long-form video storytelling as iterative shot synthesis conditioned on explicit visual memory, transforming pre-trained single-shot video diffusion models into multi-shot storytellers. This is achieved by a novel Memory-to-Video (M2V) design, which maintains a compact and dynamically updated memory bank of keyframes from historical generated shots. The stored memory is then injected into single-shot video diffusion models via latent concatenation and negative RoPE shifts with only LoRA fine-tuning. A semantic keyframe selection strategy, together with aesthetic preference filtering, further ensures informative and stable memory throughout generation. Moreover, the proposed framework naturally accommodates smooth shot transitions and customized story generation applications. To facilitate evaluation, we introduce ST-Bench, a diverse benchmark for multi-shot video storytelling. Extensive experiments demonstrate that StoryMem achieves superior cross-shot consistency over previous methods while preserving high aesthetic quality and prompt adherence, marking a significant step toward coherent minute-long video storytelling.
Trainable Log-linear Sparse Attention for Efficient Diffusion Transformers
Dec 18, 2025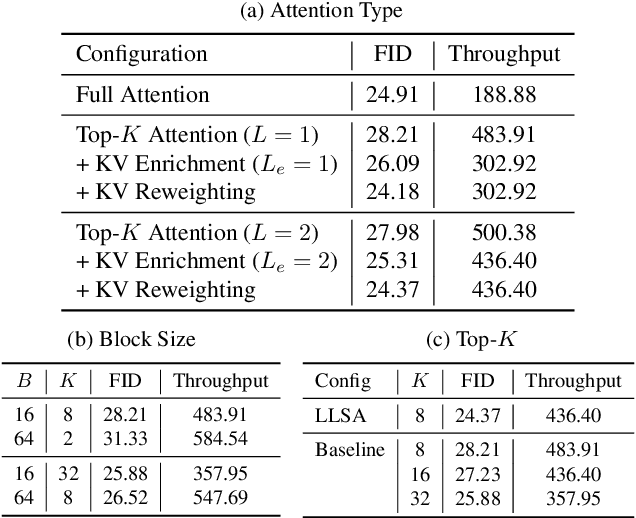
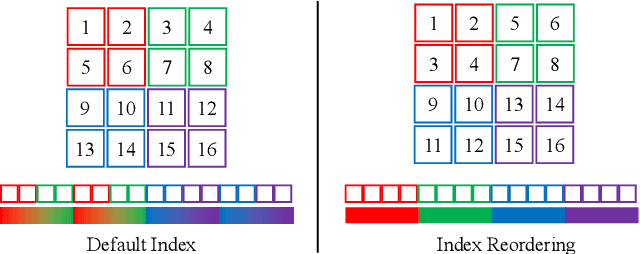
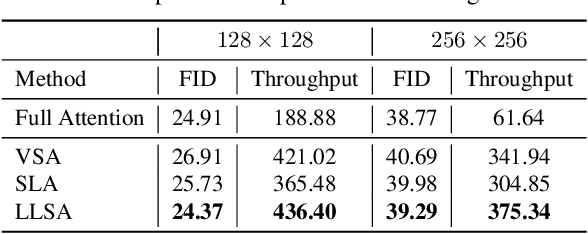
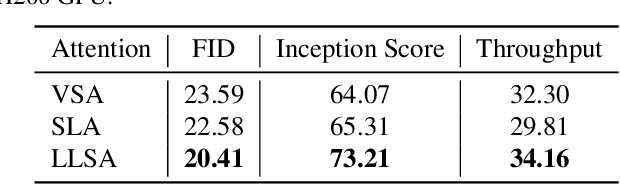
Diffusion Transformers (DiTs) set the state of the art in visual generation, yet their quadratic self-attention cost fundamentally limits scaling to long token sequences. Recent Top-K sparse attention approaches reduce the computation of DiTs by compressing tokens into block-wise representation and selecting a small set of relevant key blocks, but still suffer from (i) quadratic selection cost on compressed tokens and (ii) increasing K required to maintain model quality as sequences grow. We identify that their inefficiency is due to the single-level design, as a single coarse level is insufficient to represent the global structure. In this paper, we introduce Log-linear Sparse Attention (LLSA), a trainable sparse attention mechanism for extremely long token sequences that reduces both selection and attention costs from quadratic to log-linear complexity by utilizing a hierarchical structure. LLSA performs hierarchical Top-K selection, progressively adopting sparse Top-K selection with the indices found at the previous level, and introduces a Hierarchical KV Enrichment mechanism that preserves global context while using fewer tokens of different granularity during attention computation. To support efficient training, we develop a high-performance GPU implementation that uses only sparse indices for both the forward and backward passes, eliminating the need for dense attention masks. We evaluate LLSA on high-resolution pixel-space image generation without using patchification and VAE encoding. LLSA accelerates attention inference by 28.27x and DiT training by 6.09x on 256x256 pixel token sequences, while maintaining generation quality. The results demonstrate that LLSA offers a promising direction for training long-sequence DiTs efficiently. Code is available at: https://github.com/SingleZombie/LLSA
BokehDepth: Enhancing Monocular Depth Estimation through Bokeh Generation
Dec 13, 2025Bokeh and monocular depth estimation are tightly coupled through the same lens imaging geometry, yet current methods exploit this connection in incomplete ways. High-quality bokeh rendering pipelines typically depend on noisy depth maps, which amplify estimation errors into visible artifacts, while modern monocular metric depth models still struggle on weakly textured, distant and geometrically ambiguous regions where defocus cues are most informative. We introduce BokehDepth, a two-stage framework that decouples bokeh synthesis from depth prediction and treats defocus as an auxiliary supervision-free geometric cue. In Stage-1, a physically guided controllable bokeh generator, built on a powerful pretrained image editing backbone, produces depth-free bokeh stacks with calibrated bokeh strength from a single sharp input. In Stage-2, a lightweight defocus-aware aggregation module plugs into existing monocular depth encoders, fuses features along the defocus dimension, and exposes stable depth-sensitive variations while leaving downstream decoder unchanged. Across challenging benchmarks, BokehDepth improves visual fidelity over depth-map-based bokeh baselines and consistently boosts the metric accuracy and robustness of strong monocular depth foundation models.
FastMesh: Efficient Artistic Mesh Generation via Component Decoupling
Aug 27, 2025Recent mesh generation approaches typically tokenize triangle meshes into sequences of tokens and train autoregressive models to generate these tokens sequentially. Despite substantial progress, such token sequences inevitably reuse vertices multiple times to fully represent manifold meshes, as each vertex is shared by multiple faces. This redundancy leads to excessively long token sequences and inefficient generation processes. In this paper, we propose an efficient framework that generates artistic meshes by treating vertices and faces separately, significantly reducing redundancy. We employ an autoregressive model solely for vertex generation, decreasing the token count to approximately 23\% of that required by the most compact existing tokenizer. Next, we leverage a bidirectional transformer to complete the mesh in a single step by capturing inter-vertex relationships and constructing the adjacency matrix that defines the mesh faces. To further improve the generation quality, we introduce a fidelity enhancer to refine vertex positioning into more natural arrangements and propose a post-processing framework to remove undesirable edge connections. Experimental results show that our method achieves more than 8$\times$ faster speed on mesh generation compared to state-of-the-art approaches, while producing higher mesh quality.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Aug 14, 2025We present STream3R, a novel approach to 3D reconstruction that reformulates pointmap prediction as a decoder-only Transformer problem. Existing state-of-the-art methods for multi-view reconstruction either depend on expensive global optimization or rely on simplistic memory mechanisms that scale poorly with sequence length. In contrast, STream3R introduces an streaming framework that processes image sequences efficiently using causal attention, inspired by advances in modern language modeling. By learning geometric priors from large-scale 3D datasets, STream3R generalizes well to diverse and challenging scenarios, including dynamic scenes where traditional methods often fail. Extensive experiments show that our method consistently outperforms prior work across both static and dynamic scene benchmarks. Moreover, STream3R is inherently compatible with LLM-style training infrastructure, enabling efficient large-scale pretraining and fine-tuning for various downstream 3D tasks. Our results underscore the potential of causal Transformer models for online 3D perception, paving the way for real-time 3D understanding in streaming environments. More details can be found in our project page: https://nirvanalan.github.io/projects/stream3r.
WORLDMEM: Long-term Consistent World Simulation with Memory
Apr 16, 2025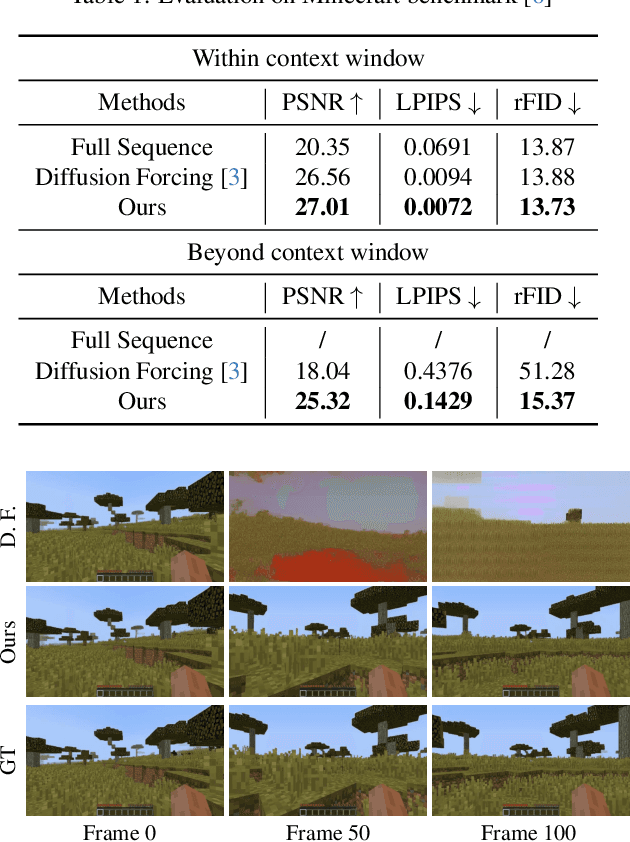
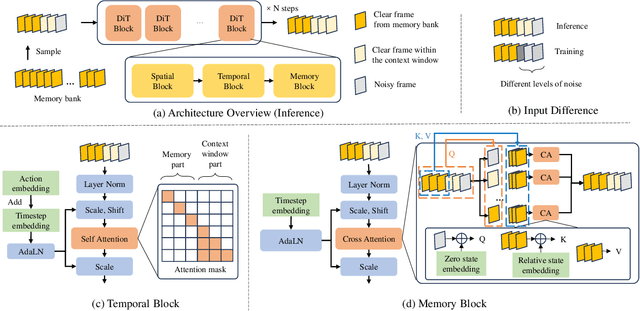
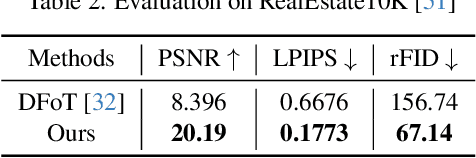
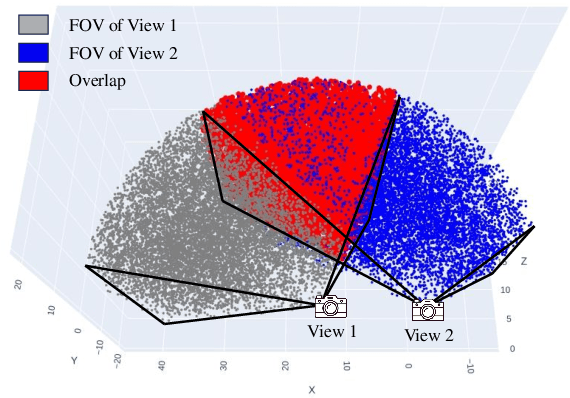
World simulation has gained increasing popularity due to its ability to model virtual environments and predict the consequences of actions. However, the limited temporal context window often leads to failures in maintaining long-term consistency, particularly in preserving 3D spatial consistency. In this work, we present WorldMem, a framework that enhances scene generation with a memory bank consisting of memory units that store memory frames and states (e.g., poses and timestamps). By employing a memory attention mechanism that effectively extracts relevant information from these memory frames based on their states, our method is capable of accurately reconstructing previously observed scenes, even under significant viewpoint or temporal gaps. Furthermore, by incorporating timestamps into the states, our framework not only models a static world but also captures its dynamic evolution over time, enabling both perception and interaction within the simulated world. Extensive experiments in both virtual and real scenarios validate the effectiveness of our approach.
FreeFlux: Understanding and Exploiting Layer-Specific Roles in RoPE-Based MMDiT for Versatile Image Editing
Mar 20, 2025
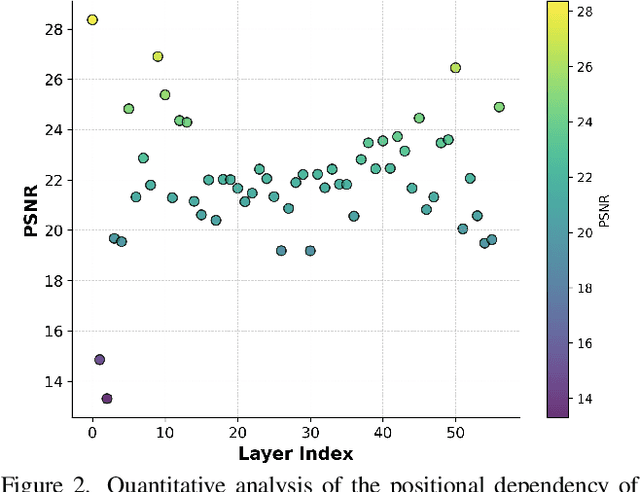
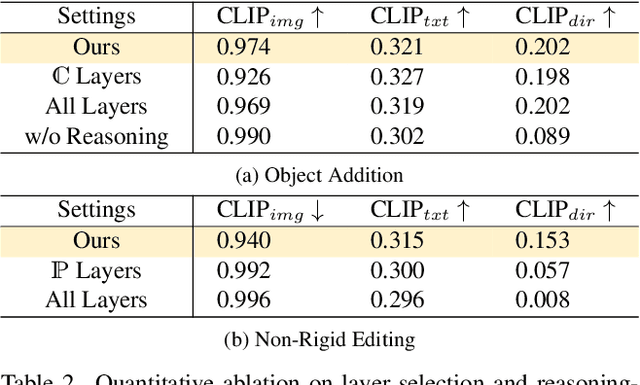

The integration of Rotary Position Embedding (RoPE) in Multimodal Diffusion Transformer (MMDiT) has significantly enhanced text-to-image generation quality. However, the fundamental reliance of self-attention layers on positional embedding versus query-key similarity during generation remains an intriguing question. We present the first mechanistic analysis of RoPE-based MMDiT models (e.g., FLUX), introducing an automated probing strategy that disentangles positional information versus content dependencies by strategically manipulating RoPE during generation. Our analysis reveals distinct dependency patterns that do not straightforwardly correlate with depth, offering new insights into the layer-specific roles in RoPE-based MMDiT. Based on these findings, we propose a training-free, task-specific image editing framework that categorizes editing tasks into three types: position-dependent editing (e.g., object addition), content similarity-dependent editing (e.g., non-rigid editing), and region-preserved editing (e.g., background replacement). For each type, we design tailored key-value injection strategies based on the characteristics of the editing task. Extensive qualitative and quantitative evaluations demonstrate that our method outperforms state-of-the-art approaches, particularly in preserving original semantic content and achieving seamless modifications.
Bokeh Diffusion: Defocus Blur Control in Text-to-Image Diffusion Models
Mar 13, 2025Recent advances in large-scale text-to-image models have revolutionized creative fields by generating visually captivating outputs from textual prompts; however, while traditional photography offers precise control over camera settings to shape visual aesthetics -- such as depth-of-field -- current diffusion models typically rely on prompt engineering to mimic such effects. This approach often results in crude approximations and inadvertently altering the scene content. In this work, we propose Bokeh Diffusion, a scene-consistent bokeh control framework that explicitly conditions a diffusion model on a physical defocus blur parameter. By grounding depth-of-field adjustments, our method preserves the underlying scene structure as the level of blur is varied. To overcome the scarcity of paired real-world images captured under different camera settings, we introduce a hybrid training pipeline that aligns in-the-wild images with synthetic blur augmentations. Extensive experiments demonstrate that our approach not only achieves flexible, lens-like blur control but also supports applications such as real image editing via inversion.