 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWORLDMEM: Long-term Consistent World Simulation with Memory
Apr 16, 2025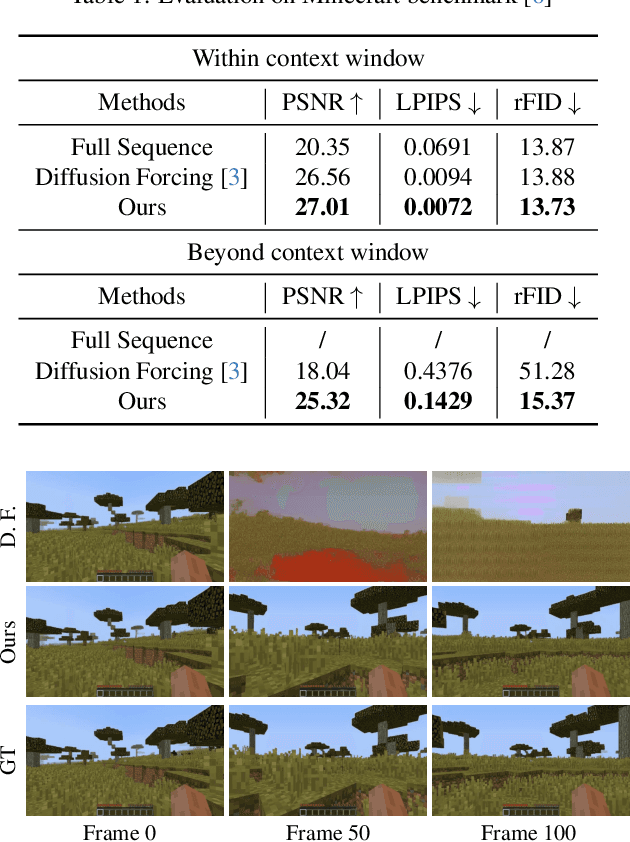
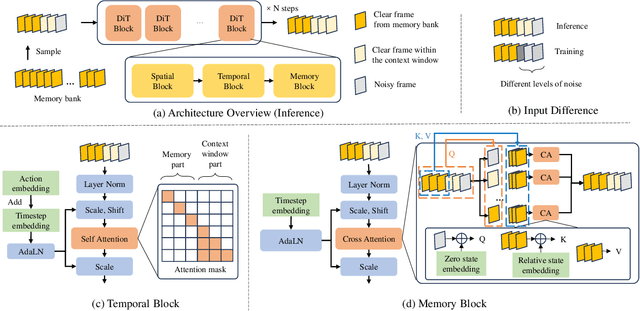
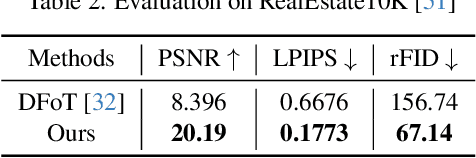
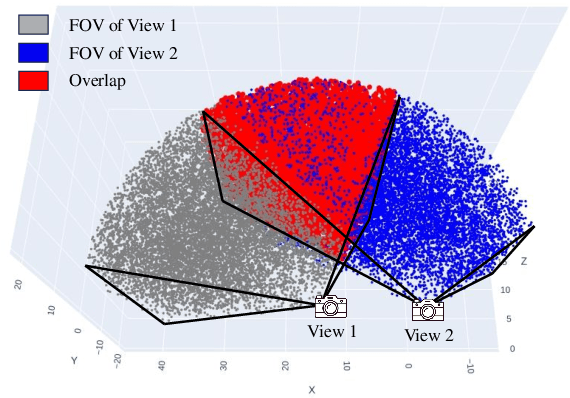
World simulation has gained increasing popularity due to its ability to model virtual environments and predict the consequences of actions. However, the limited temporal context window often leads to failures in maintaining long-term consistency, particularly in preserving 3D spatial consistency. In this work, we present WorldMem, a framework that enhances scene generation with a memory bank consisting of memory units that store memory frames and states (e.g., poses and timestamps). By employing a memory attention mechanism that effectively extracts relevant information from these memory frames based on their states, our method is capable of accurately reconstructing previously observed scenes, even under significant viewpoint or temporal gaps. Furthermore, by incorporating timestamps into the states, our framework not only models a static world but also captures its dynamic evolution over time, enabling both perception and interaction within the simulated world. Extensive experiments in both virtual and real scenarios validate the effectiveness of our approach.
Trajectory Attention for Fine-grained Video Motion Control
Nov 28, 2024
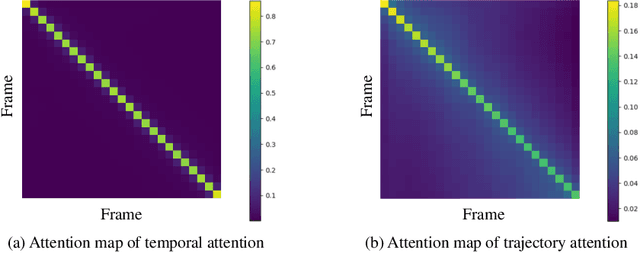

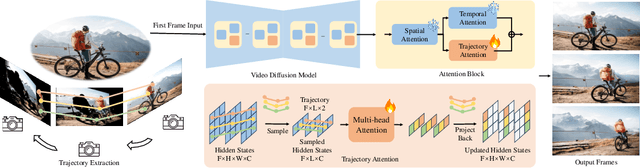
Recent advancements in video generation have been greatly driven by video diffusion models, with camera motion control emerging as a crucial challenge in creating view-customized visual content. This paper introduces trajectory attention, a novel approach that performs attention along available pixel trajectories for fine-grained camera motion control. Unlike existing methods that often yield imprecise outputs or neglect temporal correlations, our approach possesses a stronger inductive bias that seamlessly injects trajectory information into the video generation process. Importantly, our approach models trajectory attention as an auxiliary branch alongside traditional temporal attention. This design enables the original temporal attention and the trajectory attention to work in synergy, ensuring both precise motion control and new content generation capability, which is critical when the trajectory is only partially available. Experiments on camera motion control for images and videos demonstrate significant improvements in precision and long-range consistency while maintaining high-quality generation. Furthermore, we show that our approach can be extended to other video motion control tasks, such as first-frame-guided video editing, where it excels in maintaining content consistency over large spatial and temporal ranges.
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models
May 26, 2024



The remarkable generative capabilities of diffusion models have motivated extensive research in both image and video editing. Compared to video editing which faces additional challenges in the time dimension, image editing has witnessed the development of more diverse, high-quality approaches and more capable software like Photoshop. In light of this gap, we introduce a novel and generic solution that extends the applicability of image editing tools to videos by propagating edits from a single frame to the entire video using a pre-trained image-to-video model. Our method, dubbed I2VEdit, adaptively preserves the visual and motion integrity of the source video depending on the extent of the edits, effectively handling global edits, local edits, and moderate shape changes, which existing methods cannot fully achieve. At the core of our method are two main processes: Coarse Motion Extraction to align basic motion patterns with the original video, and Appearance Refinement for precise adjustments using fine-grained attention matching. We also incorporate a skip-interval strategy to mitigate quality degradation from auto-regressive generation across multiple video clips. Experimental results demonstrate our framework's superior performance in fine-grained video editing, proving its capability to produce high-quality, temporally consistent outputs.
RSFNet: A White-Box Image Retouching Approach using Region-Specific Color Filters
Mar 15, 2023

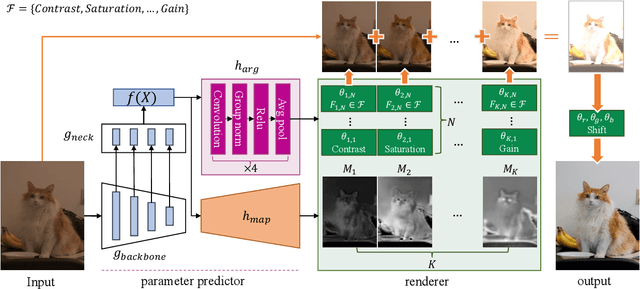

Retouching images is an essential aspect of enhancing the visual appeal of photos. Although users often share common aesthetic preferences, their retouching methods may vary based on their individual preferences. Therefore, there is a need for white-box approaches that produce satisfying results and enable users to conveniently edit their images simultaneously. Recent white-box retouching methods rely on cascaded global filters that provide image-level filter arguments but cannot perform fine-grained retouching. In contrast, colorists typically use a divide-and-conquer approach, performing a series of region-specific fine-grained enhancements when using traditional tools like Davinci Resolve. We draw on this insight to develop a white-box framework for photo retouching using parallel region-specific filters, called RSFNet. Our model generates filter arguments (e.g., saturation, contrast, hue) and attention maps of regions for each filter simultaneously. Instead of cascading filters, RSFNet employs linear summations of filters, allowing for a more diverse range of filter classes that can be trained more easily. Our experiments demonstrate that RSFNet achieves state-of-the-art results, offering satisfying aesthetic appeal and greater user convenience for editable white-box retouching.
DDColor: Towards Photo-Realistic and Semantic-Aware Image Colorization via Dual Decoders
Dec 23, 2022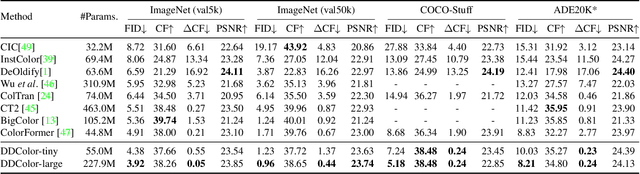



Automatic image colorization is a particularly challenging problem. Due to the high illness of the problem and multi-modal uncertainty, directly training a deep neural network usually leads to incorrect semantic colors and low color richness. Existing transformer-based methods can deliver better results but highly depend on hand-crafted dataset-level empirical distribution priors. In this work, we propose DDColor, a new end-to-end method with dual decoders, for image colorization. More specifically, we design a multi-scale image decoder and a transformer-based color decoder. The former manages to restore the spatial resolution of the image, while the latter establishes the correlation between semantic representations and color queries via cross-attention. The two decoders incorporate to learn semantic-aware color embedding by leveraging the multi-scale visual features. With the help of these two decoders, our method succeeds in producing semantically consistent and visually plausible colorization results without any additional priors. In addition, a simple but effective colorfulness loss is introduced to further improve the color richness of generated results. Our extensive experiments demonstrate that the proposed DDColor achieves significantly superior performance to existing state-of-the-art works both quantitatively and qualitatively. Codes will be made publicly available at https://github.com/piddnad/DDColor.