 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePnP-U3D: Plug-and-Play 3D Framework Bridging Autoregression and Diffusion for Unified Understanding and Generation
Feb 03, 2026The rapid progress of large multimodal models has inspired efforts toward unified frameworks that couple understanding and generation. While such paradigms have shown remarkable success in 2D, extending them to 3D remains largely underexplored. Existing attempts to unify 3D tasks under a single autoregressive (AR) paradigm lead to significant performance degradation due to forced signal quantization and prohibitive training cost. Our key insight is that the essential challenge lies not in enforcing a unified autoregressive paradigm, but in enabling effective information interaction between generation and understanding while minimally compromising their inherent capabilities and leveraging pretrained models to reduce training cost. Guided by this perspective, we present the first unified framework for 3D understanding and generation that combines autoregression with diffusion. Specifically, we adopt an autoregressive next-token prediction paradigm for 3D understanding, and a continuous diffusion paradigm for 3D generation. A lightweight transformer bridges the feature space of large language models and the conditional space of 3D diffusion models, enabling effective cross-modal information exchange while preserving the priors learned by standalone models. Extensive experiments demonstrate that our framework achieves state-of-the-art performance across diverse 3D understanding and generation benchmarks, while also excelling in 3D editing tasks. These results highlight the potential of unified AR+diffusion models as a promising direction for building more general-purpose 3D intelligence.
VFMF: World Modeling by Forecasting Vision Foundation Model Features
Dec 12, 2025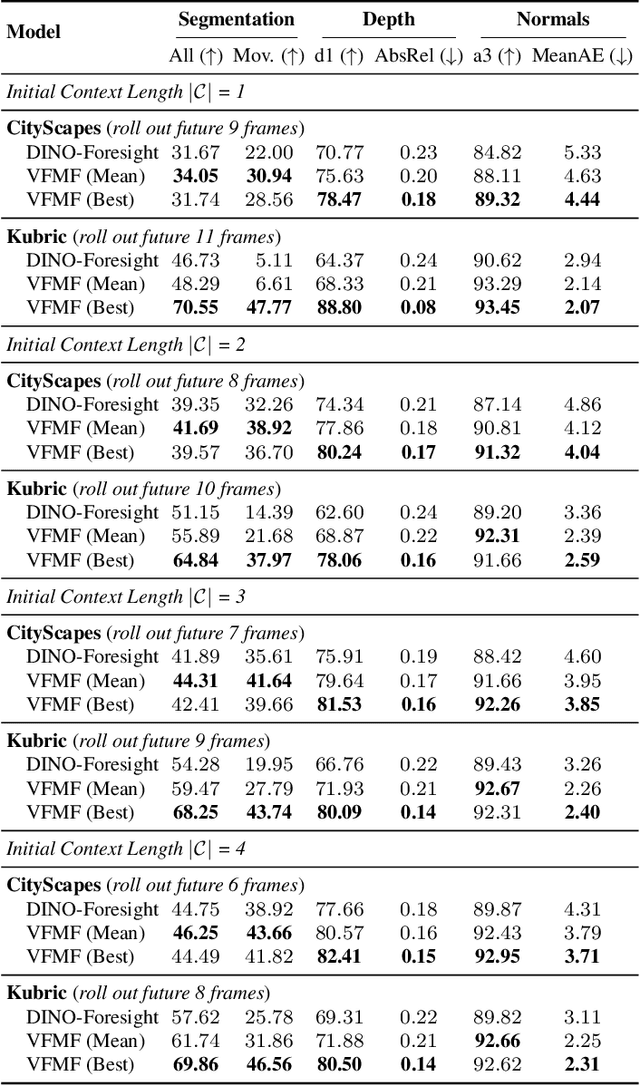

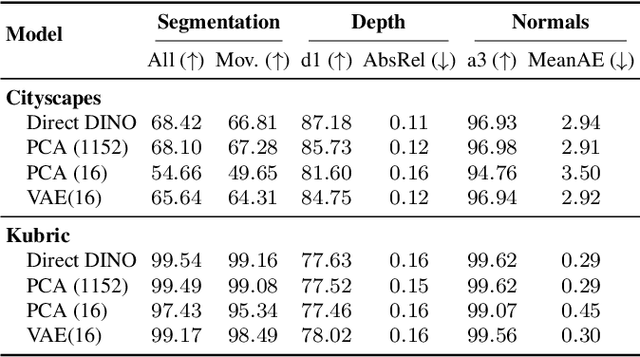
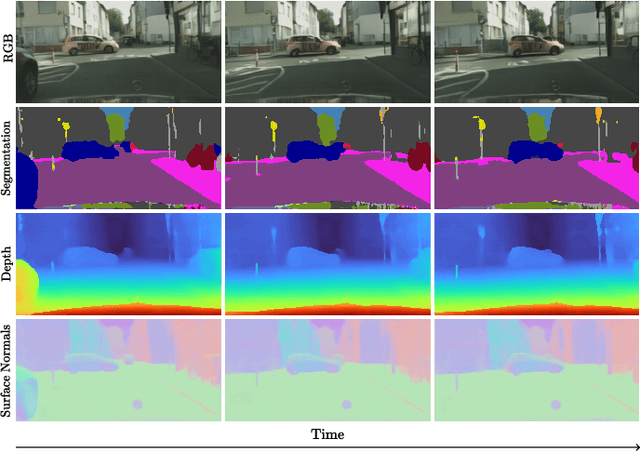
Forecasting from partial observations is central to world modeling. Many recent methods represent the world through images, and reduce forecasting to stochastic video generation. Although such methods excel at realism and visual fidelity, predicting pixels is computationally intensive and not directly useful in many applications, as it requires translating RGB into signals useful for decision making. An alternative approach uses features from vision foundation models (VFMs) as world representations, performing deterministic regression to predict future world states. These features can be directly translated into actionable signals such as semantic segmentation and depth, while remaining computationally efficient. However, deterministic regression averages over multiple plausible futures, undermining forecast accuracy by failing to capture uncertainty. To address this crucial limitation, we introduce a generative forecaster that performs autoregressive flow matching in VFM feature space. Our key insight is that generative modeling in this space requires encoding VFM features into a compact latent space suitable for diffusion. We show that this latent space preserves information more effectively than previously used PCA-based alternatives, both for forecasting and other applications, such as image generation. Our latent predictions can be easily decoded into multiple useful and interpretable output modalities: semantic segmentation, depth, surface normals, and even RGB. With matched architecture and compute, our method produces sharper and more accurate predictions than regression across all modalities. Our results suggest that stochastic conditional generation of VFM features offers a promising and scalable foundation for future world models.
OmniVGGT: Omni-Modality Driven Visual Geometry Grounded Transformer
Nov 14, 2025General 3D foundation models have started to lead the trend of unifying diverse vision tasks, yet most assume RGB-only inputs and ignore readily available geometric cues (e.g., camera intrinsics, poses, and depth maps). To address this issue, we introduce OmniVGGT, a novel framework that can effectively benefit from an arbitrary number of auxiliary geometric modalities during both training and inference. In our framework, a GeoAdapter is proposed to encode depth and camera intrinsics/extrinsics into a spatial foundation model. It employs zero-initialized convolutions to progressively inject geometric information without disrupting the foundation model's representation space. This design ensures stable optimization with negligible overhead, maintaining inference speed comparable to VGGT even with multiple additional inputs. Additionally, a stochastic multimodal fusion regimen is proposed, which randomly samples modality subsets per instance during training. This enables an arbitrary number of modality inputs during testing and promotes learning robust spatial representations instead of overfitting to auxiliary cues. Comprehensive experiments on monocular/multi-view depth estimation, multi-view stereo, and camera pose estimation demonstrate that OmniVGGT outperforms prior methods with auxiliary inputs and achieves state-of-the-art results even with RGB-only input. To further highlight its practical utility, we integrated OmniVGGT into vision-language-action (VLA) models. The enhanced VLA model by OmniVGGT not only outperforms the vanilla point-cloud-based baseline on mainstream benchmarks, but also effectively leverages accessible auxiliary inputs to achieve consistent gains on robotic tasks.
IGGT: Instance-Grounded Geometry Transformer for Semantic 3D Reconstruction
Oct 26, 2025Humans naturally perceive the geometric structure and semantic content of a 3D world as intertwined dimensions, enabling coherent and accurate understanding of complex scenes. However, most prior approaches prioritize training large geometry models for low-level 3D reconstruction and treat high-level spatial understanding in isolation, overlooking the crucial interplay between these two fundamental aspects of 3D-scene analysis, thereby limiting generalization and leading to poor performance in downstream 3D understanding tasks. Recent attempts have mitigated this issue by simply aligning 3D models with specific language models, thus restricting perception to the aligned model's capacity and limiting adaptability to downstream tasks. In this paper, we propose InstanceGrounded Geometry Transformer (IGGT), an end-to-end large unified transformer to unify the knowledge for both spatial reconstruction and instance-level contextual understanding. Specifically, we design a 3D-Consistent Contrastive Learning strategy that guides IGGT to encode a unified representation with geometric structures and instance-grounded clustering through only 2D visual inputs. This representation supports consistent lifting of 2D visual inputs into a coherent 3D scene with explicitly distinct object instances. To facilitate this task, we further construct InsScene-15K, a large-scale dataset with high-quality RGB images, poses, depth maps, and 3D-consistent instance-level mask annotations with a novel data curation pipeline.
FastMesh: Efficient Artistic Mesh Generation via Component Decoupling
Aug 27, 2025Recent mesh generation approaches typically tokenize triangle meshes into sequences of tokens and train autoregressive models to generate these tokens sequentially. Despite substantial progress, such token sequences inevitably reuse vertices multiple times to fully represent manifold meshes, as each vertex is shared by multiple faces. This redundancy leads to excessively long token sequences and inefficient generation processes. In this paper, we propose an efficient framework that generates artistic meshes by treating vertices and faces separately, significantly reducing redundancy. We employ an autoregressive model solely for vertex generation, decreasing the token count to approximately 23\% of that required by the most compact existing tokenizer. Next, we leverage a bidirectional transformer to complete the mesh in a single step by capturing inter-vertex relationships and constructing the adjacency matrix that defines the mesh faces. To further improve the generation quality, we introduce a fidelity enhancer to refine vertex positioning into more natural arrangements and propose a post-processing framework to remove undesirable edge connections. Experimental results show that our method achieves more than 8$\times$ faster speed on mesh generation compared to state-of-the-art approaches, while producing higher mesh quality.
STream3R: Scalable Sequential 3D Reconstruction with Causal Transformer
Aug 14, 2025We present STream3R, a novel approach to 3D reconstruction that reformulates pointmap prediction as a decoder-only Transformer problem. Existing state-of-the-art methods for multi-view reconstruction either depend on expensive global optimization or rely on simplistic memory mechanisms that scale poorly with sequence length. In contrast, STream3R introduces an streaming framework that processes image sequences efficiently using causal attention, inspired by advances in modern language modeling. By learning geometric priors from large-scale 3D datasets, STream3R generalizes well to diverse and challenging scenarios, including dynamic scenes where traditional methods often fail. Extensive experiments show that our method consistently outperforms prior work across both static and dynamic scene benchmarks. Moreover, STream3R is inherently compatible with LLM-style training infrastructure, enabling efficient large-scale pretraining and fine-tuning for various downstream 3D tasks. Our results underscore the potential of causal Transformer models for online 3D perception, paving the way for real-time 3D understanding in streaming environments. More details can be found in our project page: https://nirvanalan.github.io/projects/stream3r.
WORLDMEM: Long-term Consistent World Simulation with Memory
Apr 16, 2025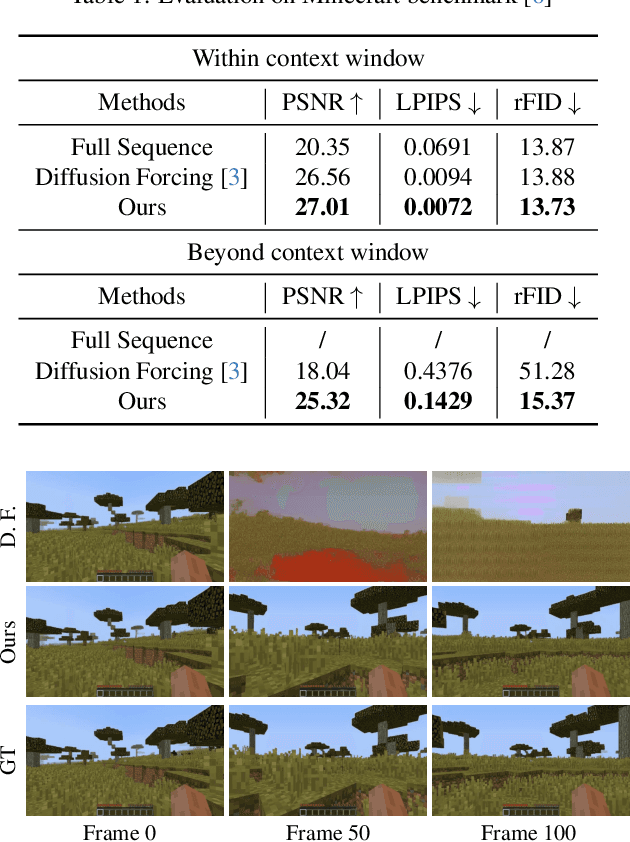
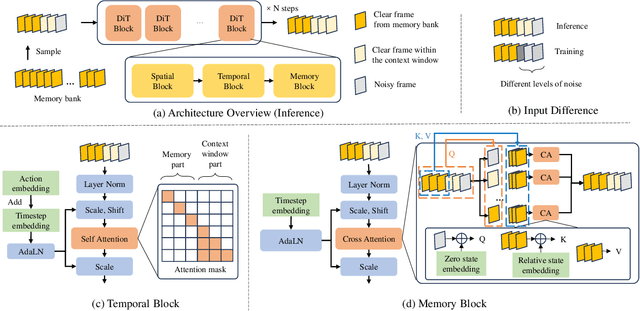
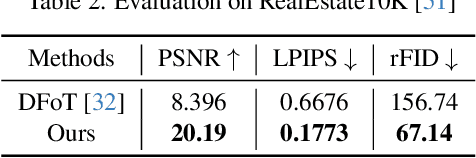
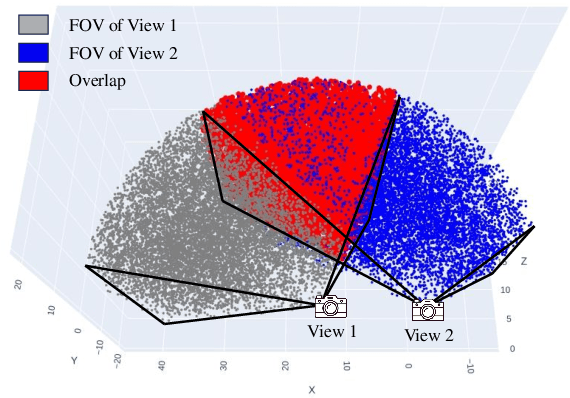
World simulation has gained increasing popularity due to its ability to model virtual environments and predict the consequences of actions. However, the limited temporal context window often leads to failures in maintaining long-term consistency, particularly in preserving 3D spatial consistency. In this work, we present WorldMem, a framework that enhances scene generation with a memory bank consisting of memory units that store memory frames and states (e.g., poses and timestamps). By employing a memory attention mechanism that effectively extracts relevant information from these memory frames based on their states, our method is capable of accurately reconstructing previously observed scenes, even under significant viewpoint or temporal gaps. Furthermore, by incorporating timestamps into the states, our framework not only models a static world but also captures its dynamic evolution over time, enabling both perception and interaction within the simulated world. Extensive experiments in both virtual and real scenarios validate the effectiveness of our approach.
Textured 3D Regenerative Morphing with 3D Diffusion Prior
Feb 20, 2025Textured 3D morphing creates smooth and plausible interpolation sequences between two 3D objects, focusing on transitions in both shape and texture. This is important for creative applications like visual effects in filmmaking. Previous methods rely on establishing point-to-point correspondences and determining smooth deformation trajectories, which inherently restrict them to shape-only morphing on untextured, topologically aligned datasets. This restriction leads to labor-intensive preprocessing and poor generalization. To overcome these challenges, we propose a method for 3D regenerative morphing using a 3D diffusion prior. Unlike previous methods that depend on explicit correspondences and deformations, our method eliminates the additional need for obtaining correspondence and uses the 3D diffusion prior to generate morphing. Specifically, we introduce a 3D diffusion model and interpolate the source and target information at three levels: initial noise, model parameters, and condition features. We then explore an Attention Fusion strategy to generate more smooth morphing sequences. To further improve the plausibility of semantic interpolation and the generated 3D surfaces, we propose two strategies: (a) Token Reordering, where we match approximate tokens based on semantic analysis to guide implicit correspondences in the denoising process of the diffusion model, and (b) Low-Frequency Enhancement, where we enhance low-frequency signals in the tokens to improve the quality of generated surfaces. Experimental results show that our method achieves superior smoothness and plausibility in 3D morphing across diverse cross-category object pairs, offering a novel regenerative method for 3D morphing with textured representations.
3DEnhancer: Consistent Multi-View Diffusion for 3D Enhancement
Dec 24, 2024Despite advances in neural rendering, due to the scarcity of high-quality 3D datasets and the inherent limitations of multi-view diffusion models, view synthesis and 3D model generation are restricted to low resolutions with suboptimal multi-view consistency. In this study, we present a novel 3D enhancement pipeline, dubbed 3DEnhancer, which employs a multi-view latent diffusion model to enhance coarse 3D inputs while preserving multi-view consistency. Our method includes a pose-aware encoder and a diffusion-based denoiser to refine low-quality multi-view images, along with data augmentation and a multi-view attention module with epipolar aggregation to maintain consistent, high-quality 3D outputs across views. Unlike existing video-based approaches, our model supports seamless multi-view enhancement with improved coherence across diverse viewing angles. Extensive evaluations show that 3DEnhancer significantly outperforms existing methods, boosting both multi-view enhancement and per-instance 3D optimization tasks.
ObjCtrl-2.5D: Training-free Object Control with Camera Poses
Dec 10, 2024



This study aims to achieve more precise and versatile object control in image-to-video (I2V) generation. Current methods typically represent the spatial movement of target objects with 2D trajectories, which often fail to capture user intention and frequently produce unnatural results. To enhance control, we present ObjCtrl-2.5D, a training-free object control approach that uses a 3D trajectory, extended from a 2D trajectory with depth information, as a control signal. By modeling object movement as camera movement, ObjCtrl-2.5D represents the 3D trajectory as a sequence of camera poses, enabling object motion control using an existing camera motion control I2V generation model (CMC-I2V) without training. To adapt the CMC-I2V model originally designed for global motion control to handle local object motion, we introduce a module to isolate the target object from the background, enabling independent local control. In addition, we devise an effective way to achieve more accurate object control by sharing low-frequency warped latent within the object's region across frames. Extensive experiments demonstrate that ObjCtrl-2.5D significantly improves object control accuracy compared to training-free methods and offers more diverse control capabilities than training-based approaches using 2D trajectories, enabling complex effects like object rotation. Code and results are available at https://wzhouxiff.github.io/projects/ObjCtrl-2.5D/.