 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmortized Inference for Model Rocket Aerodynamics: Learning to Estimate Physical Parameters from Simulation
Dec 24, 2025Accurate prediction of model rocket flight performance requires estimating aerodynamic parameters that are difficult to measure directly. Traditional approaches rely on computational fluid dynamics or empirical correlations, while data-driven methods require extensive real flight data that is expensive and time-consuming to collect. We present a simulation-based amortized inference approach that trains a neural network on synthetic flight data generated from a physics simulator, then applies the learned model to real flights without any fine-tuning. Our method learns to invert the forward physics model, directly predicting drag coefficient and thrust correction factor from a single apogee measurement combined with motor and configuration features. In this proof-of-concept study, we train on 10,000 synthetic flights and evaluate on 8 real flights, achieving a mean absolute error of 12.3 m in apogee prediction - demonstrating promising sim-to-real transfer with zero real training examples. Analysis reveals a systematic positive bias in predictions, providing quantitative insight into the gap between idealized physics and real-world flight conditions. We additionally compare against OpenRocket baseline predictions, showing that our learned approach reduces apogee prediction error. Our implementation is publicly available to support reproducibility and adoption in the amateur rocketry community.
Context-Enhanced Contrastive Search for Improved LLM Text Generation
Apr 22, 2025Recently, Large Language Models (LLMs) have demonstrated remarkable advancements in Natural Language Processing (NLP). However, generating high-quality text that balances coherence, diversity, and relevance remains challenging. Traditional decoding methods, such as bean search and top-k sampling, often struggle with either repetitive or incoherent outputs, particularly in tasks that require long-form text generation. To address these limitations, the paper proposes a novel enhancement of the well-known Contrastive Search algorithm, Context-Enhanced Contrastive Search (CECS) with contextual calibration. The proposed scheme introduces several novelties including dynamic contextual importance weighting, multi-level Contrastive Search, and adaptive temperature control, to optimize the balance between fluency, creativity, and precision. The performance of CECS is evaluated using several standard metrics such as BLEU, ROUGE, and semantic similarity. Experimental results demonstrate significant improvements in both coherence and relevance of the generated texts by CECS outperforming the existing Contrastive Search techniques. The proposed algorithm has several potential applications in the real world including legal document drafting, customer service chatbots, and content marketing.
LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Sep 26, 2024
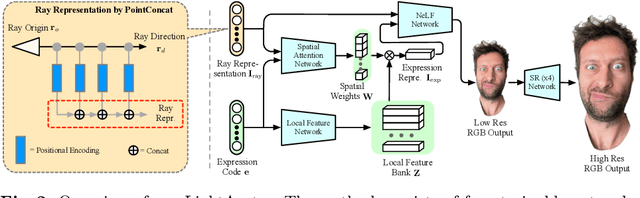


Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
Generative AI-Based Text Generation Methods Using Pre-Trained GPT-2 Model
Apr 02, 2024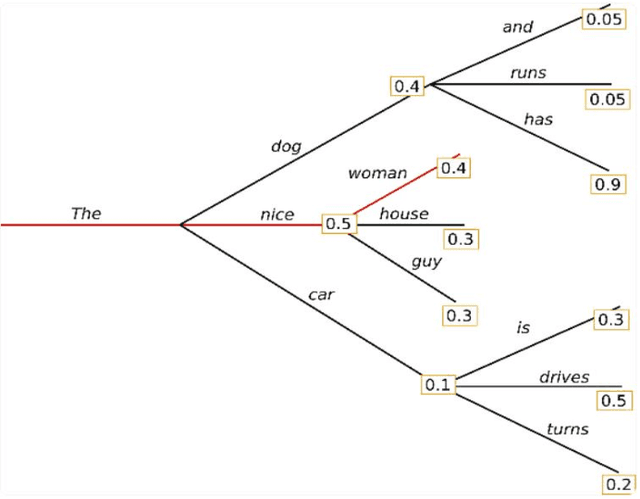
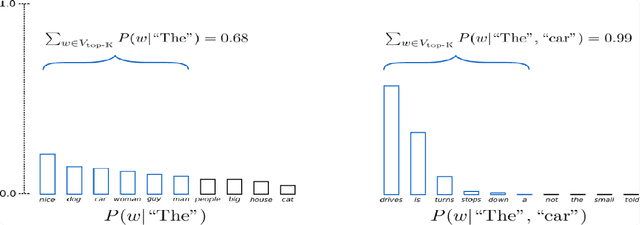
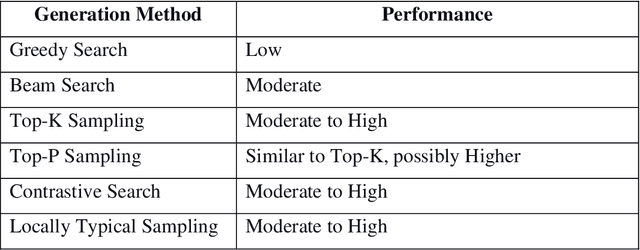
This work delved into the realm of automatic text generation, exploring a variety of techniques ranging from traditional deterministic approaches to more modern stochastic methods. Through analysis of greedy search, beam search, top-k sampling, top-p sampling, contrastive searching, and locally typical searching, this work has provided valuable insights into the strengths, weaknesses, and potential applications of each method. Each text-generating method is evaluated using several standard metrics and a comparative study has been made on the performance of the approaches. Finally, some future directions of research in the field of automatic text generation are also identified.
Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Apr 02, 20243D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
One2Avatar: Generative Implicit Head Avatar For Few-shot User Adaptation
Feb 19, 2024



Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for 3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative models, our prior is built with a 3DMM-anchored neural radiance field backbone, which we show to be more effective for avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient and personalized avatar creation.
Gaussian3Diff: 3D Gaussian Diffusion for 3D Full Head Synthesis and Editing
Dec 19, 2023
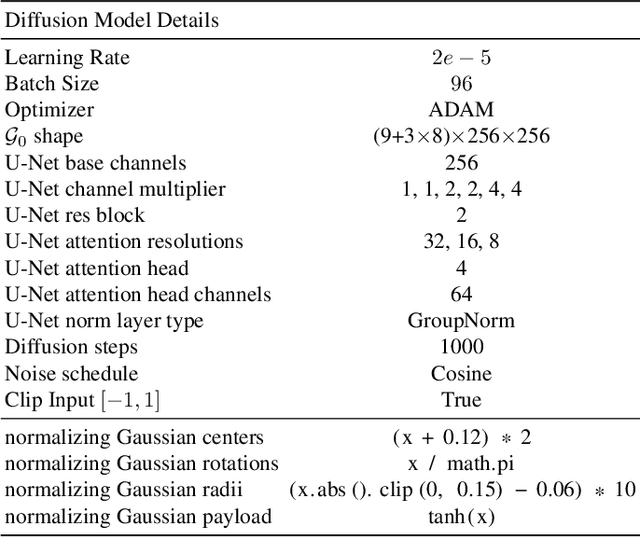
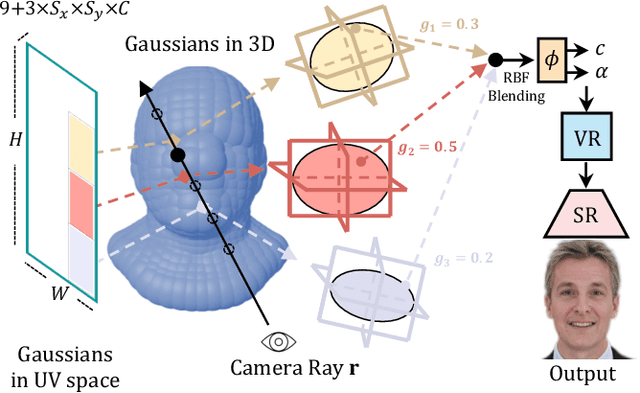

We present a novel framework for generating photorealistic 3D human head and subsequently manipulating and reposing them with remarkable flexibility. The proposed approach leverages an implicit function representation of 3D human heads, employing 3D Gaussians anchored on a parametric face model. To enhance representational capabilities and encode spatial information, we embed a lightweight tri-plane payload within each Gaussian rather than directly storing color and opacity. Additionally, we parameterize the Gaussians in a 2D UV space via a 3DMM, enabling effective utilization of the diffusion model for 3D head avatar generation. Our method facilitates the creation of diverse and realistic 3D human heads with fine-grained editing over facial features and expressions. Extensive experiments demonstrate the effectiveness of our method.
MVDD: Multi-View Depth Diffusion Models
Dec 19, 2023Denoising diffusion models have demonstrated outstanding results in 2D image generation, yet it remains a challenge to replicate its success in 3D shape generation. In this paper, we propose leveraging multi-view depth, which represents complex 3D shapes in a 2D data format that is easy to denoise. We pair this representation with a diffusion model, MVDD, that is capable of generating high-quality dense point clouds with 20K+ points with fine-grained details. To enforce 3D consistency in multi-view depth, we introduce an epipolar line segment attention that conditions the denoising step for a view on its neighboring views. Additionally, a depth fusion module is incorporated into diffusion steps to further ensure the alignment of depth maps. When augmented with surface reconstruction, MVDD can also produce high-quality 3D meshes. Furthermore, MVDD stands out in other tasks such as depth completion, and can serve as a 3D prior, significantly boosting many downstream tasks, such as GAN inversion. State-of-the-art results from extensive experiments demonstrate MVDD's excellent ability in 3D shape generation, depth completion, and its potential as a 3D prior for downstream tasks.
Controllable Light Diffusion for Portraits
May 08, 2023



We introduce light diffusion, a novel method to improve lighting in portraits, softening harsh shadows and specular highlights while preserving overall scene illumination. Inspired by professional photographers' diffusers and scrims, our method softens lighting given only a single portrait photo. Previous portrait relighting approaches focus on changing the entire lighting environment, removing shadows (ignoring strong specular highlights), or removing shading entirely. In contrast, we propose a learning based method that allows us to control the amount of light diffusion and apply it on in-the-wild portraits. Additionally, we design a method to synthetically generate plausible external shadows with sub-surface scattering effects while conforming to the shape of the subject's face. Finally, we show how our approach can increase the robustness of higher level vision applications, such as albedo estimation, geometry estimation and semantic segmentation.
Learning Personalized High Quality Volumetric Head Avatars from Monocular RGB Videos
Apr 04, 2023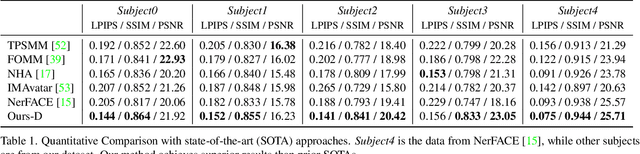
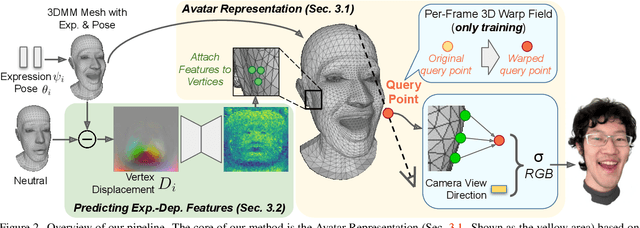
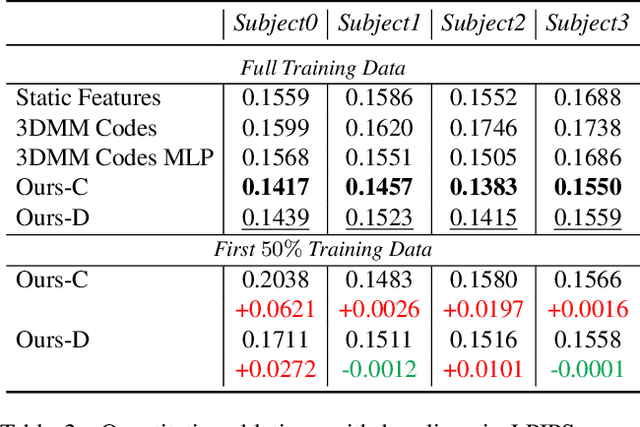
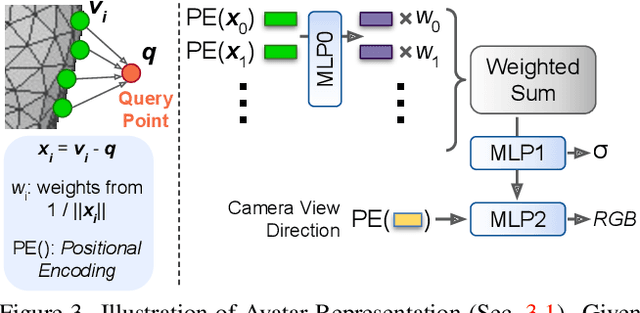
We propose a method to learn a high-quality implicit 3D head avatar from a monocular RGB video captured in the wild. The learnt avatar is driven by a parametric face model to achieve user-controlled facial expressions and head poses. Our hybrid pipeline combines the geometry prior and dynamic tracking of a 3DMM with a neural radiance field to achieve fine-grained control and photorealism. To reduce over-smoothing and improve out-of-model expressions synthesis, we propose to predict local features anchored on the 3DMM geometry. These learnt features are driven by 3DMM deformation and interpolated in 3D space to yield the volumetric radiance at a designated query point. We further show that using a Convolutional Neural Network in the UV space is critical in incorporating spatial context and producing representative local features. Extensive experiments show that we are able to reconstruct high-quality avatars, with more accurate expression-dependent details, good generalization to out-of-training expressions, and quantitatively superior renderings compared to other state-of-the-art approaches.