 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetermination Of Structural Cracks Using Deep Learning Frameworks
Jul 03, 2025Structural crack detection is a critical task for public safety as it helps in preventing potential structural failures that could endanger lives. Manual detection by inexperienced personnel can be slow, inconsistent, and prone to human error, which may compromise the reliability of assessments. The current study addresses these challenges by introducing a novel deep-learning architecture designed to enhance the accuracy and efficiency of structural crack detection. In this research, various configurations of residual U-Net models were utilized. These models, due to their robustness in capturing fine details, were further integrated into an ensemble with a meta-model comprising convolutional blocks. This unique combination aimed to boost prediction efficiency beyond what individual models could achieve. The ensemble's performance was evaluated against well-established architectures such as SegNet and the traditional U-Net. Results demonstrated that the residual U-Net models outperformed their predecessors, particularly with low-resolution imagery, and the ensemble model exceeded the performance of individual models, proving it as the most effective. The assessment was based on the Intersection over Union (IoU) metric and DICE coefficient. The ensemble model achieved the highest scores, signifying superior accuracy. This advancement suggests way for more reliable automated systems in structural defects monitoring tasks.
Adversarial Text Generation with Dynamic Contextual Perturbation
Jun 10, 2025Adversarial attacks on Natural Language Processing (NLP) models expose vulnerabilities by introducing subtle perturbations to input text, often leading to misclassification while maintaining human readability. Existing methods typically focus on word-level or local text segment alterations, overlooking the broader context, which results in detectable or semantically inconsistent perturbations. We propose a novel adversarial text attack scheme named Dynamic Contextual Perturbation (DCP). DCP dynamically generates context-aware perturbations across sentences, paragraphs, and documents, ensuring semantic fidelity and fluency. Leveraging the capabilities of pre-trained language models, DCP iteratively refines perturbations through an adversarial objective function that balances the dual objectives of inducing model misclassification and preserving the naturalness of the text. This comprehensive approach allows DCP to produce more sophisticated and effective adversarial examples that better mimic natural language patterns. Our experimental results, conducted on various NLP models and datasets, demonstrate the efficacy of DCP in challenging the robustness of state-of-the-art NLP systems. By integrating dynamic contextual analysis, DCP significantly enhances the subtlety and impact of adversarial attacks. This study highlights the critical role of context in adversarial attacks and lays the groundwork for creating more robust NLP systems capable of withstanding sophisticated adversarial strategies.
* This is the accepted version of the paper, which was presented at IEEE CALCON. The conference was organized at Jadavpur University, Kolkata, from December 14 to 15, 2025. The paper is six pages long, and it consists of six tables and six figures. This is not the final camera-ready version of the paper
Context-Enhanced Contrastive Search for Improved LLM Text Generation
Apr 22, 2025Recently, Large Language Models (LLMs) have demonstrated remarkable advancements in Natural Language Processing (NLP). However, generating high-quality text that balances coherence, diversity, and relevance remains challenging. Traditional decoding methods, such as bean search and top-k sampling, often struggle with either repetitive or incoherent outputs, particularly in tasks that require long-form text generation. To address these limitations, the paper proposes a novel enhancement of the well-known Contrastive Search algorithm, Context-Enhanced Contrastive Search (CECS) with contextual calibration. The proposed scheme introduces several novelties including dynamic contextual importance weighting, multi-level Contrastive Search, and adaptive temperature control, to optimize the balance between fluency, creativity, and precision. The performance of CECS is evaluated using several standard metrics such as BLEU, ROUGE, and semantic similarity. Experimental results demonstrate significant improvements in both coherence and relevance of the generated texts by CECS outperforming the existing Contrastive Search techniques. The proposed algorithm has several potential applications in the real world including legal document drafting, customer service chatbots, and content marketing.
Adversarial Robustness through Dynamic Ensemble Learning
Dec 20, 2024Adversarial attacks pose a significant threat to the reliability of pre-trained language models (PLMs) such as GPT, BERT, RoBERTa, and T5. This paper presents Adversarial Robustness through Dynamic Ensemble Learning (ARDEL), a novel scheme designed to enhance the robustness of PLMs against such attacks. ARDEL leverages the diversity of multiple PLMs and dynamically adjusts the ensemble configuration based on input characteristics and detected adversarial patterns. Key components of ARDEL include a meta-model for dynamic weighting, an adversarial pattern detection module, and adversarial training with regularization techniques. Comprehensive evaluations using standardized datasets and various adversarial attack scenarios demonstrate that ARDEL significantly improves robustness compared to existing methods. By dynamically reconfiguring the ensemble to prioritize the most robust models for each input, ARDEL effectively reduces attack success rates and maintains higher accuracy under adversarial conditions. This work contributes to the broader goal of developing more secure and trustworthy AI systems for real-world NLP applications, offering a practical and scalable solution to enhance adversarial resilience in PLMs.
A Comparative Study of Hyperparameter Tuning Methods
Aug 29, 2024The study emphasizes the challenge of finding the optimal trade-off between bias and variance, especially as hyperparameter optimization increases in complexity. Through empirical analysis, three hyperparameter tuning algorithms Tree-structured Parzen Estimator (TPE), Genetic Search, and Random Search are evaluated across regression and classification tasks. The results show that nonlinear models, with properly tuned hyperparameters, significantly outperform linear models. Interestingly, Random Search excelled in regression tasks, while TPE was more effective for classification tasks. This suggests that there is no one-size-fits-all solution, as different algorithms perform better depending on the task and model type. The findings underscore the importance of selecting the appropriate tuning method and highlight the computational challenges involved in optimizing machine learning models, particularly as search spaces expand.
Robust Image Classification: Defensive Strategies against FGSM and PGD Adversarial Attacks
Aug 20, 2024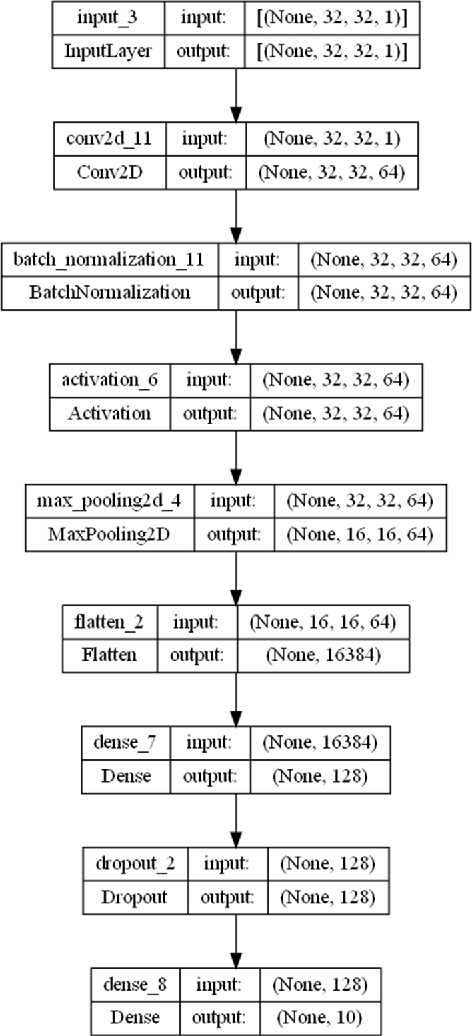

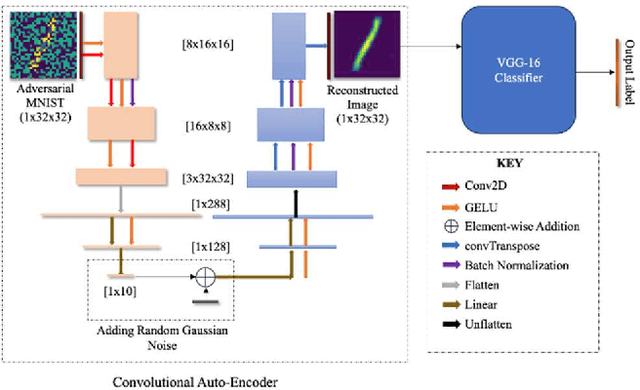
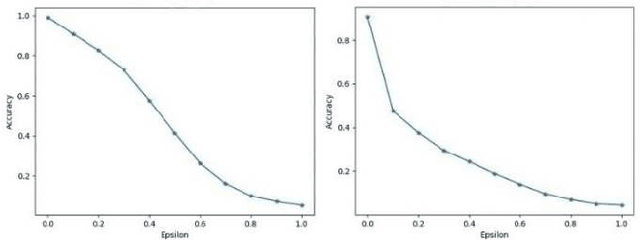
Adversarial attacks, particularly the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) pose significant threats to the robustness of deep learning models in image classification. This paper explores and refines defense mechanisms against these attacks to enhance the resilience of neural networks. We employ a combination of adversarial training and innovative preprocessing techniques, aiming to mitigate the impact of adversarial perturbations. Our methodology involves modifying input data before classification and investigating different model architectures and training strategies. Through rigorous evaluation of benchmark datasets, we demonstrate the effectiveness of our approach in defending against FGSM and PGD attacks. Our results show substantial improvements in model robustness compared to baseline methods, highlighting the potential of our defense strategies in real-world applications. This study contributes to the ongoing efforts to develop secure and reliable machine learning systems, offering practical insights and paving the way for future research in adversarial defense. By bridging theoretical advancements and practical implementation, we aim to enhance the trustworthiness of AI applications in safety-critical domains.
Analyzing Consumer Reviews for Understanding Drivers of Hotels Ratings: An Indian Perspective
Aug 08, 2024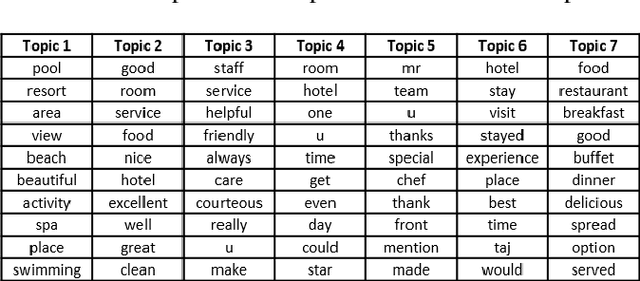
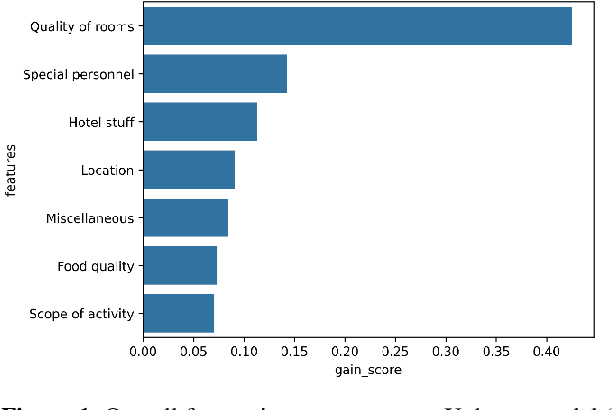
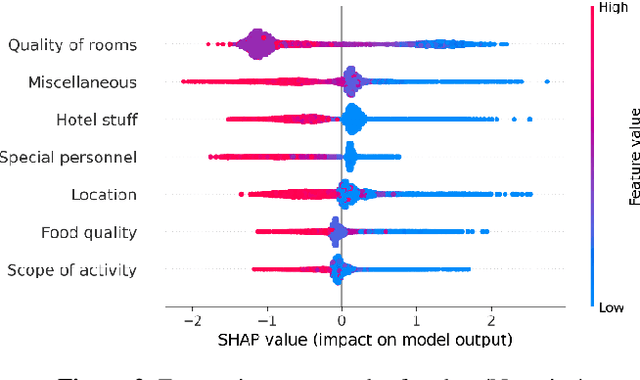
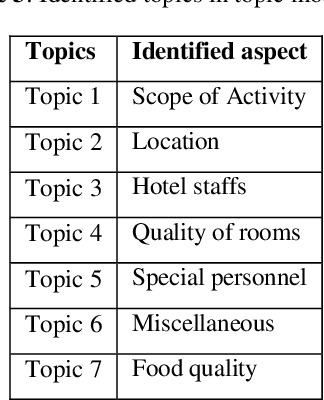
In the internet era, almost every business entity is trying to have its digital footprint in digital media and other social media platforms. For these entities, word of mouse is also very important. Particularly, this is quite crucial for the hospitality sector dealing with hotels, restaurants etc. Consumers do read other consumers reviews before making final decisions. This is where it becomes very important to understand which aspects are affecting most in the minds of the consumers while giving their ratings. The current study focuses on the consumer reviews of Indian hotels to extract aspects important for final ratings. The study involves gathering data using web scraping methods, analyzing the texts using Latent Dirichlet Allocation for topic extraction and sentiment analysis for aspect-specific sentiment mapping. Finally, it incorporates Random Forest to understand the importance of the aspects in predicting the final rating of a user.
Enhancing Adversarial Text Attacks on BERT Models with Projected Gradient Descent
Jul 29, 2024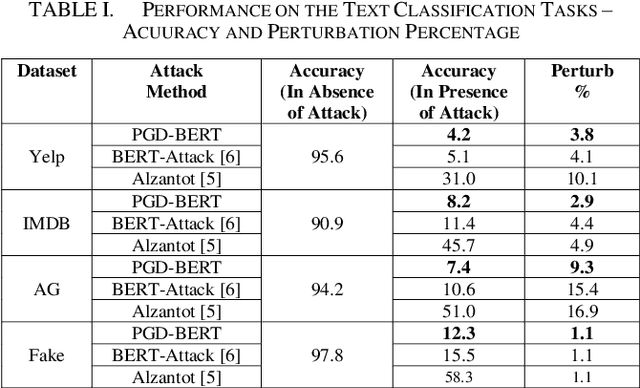
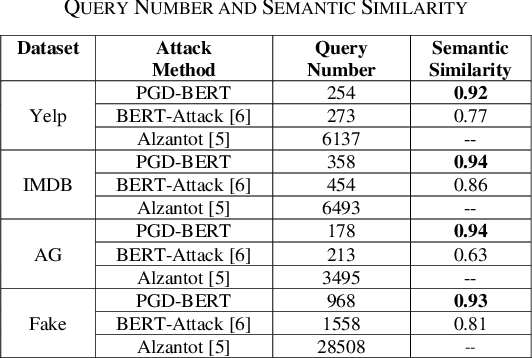
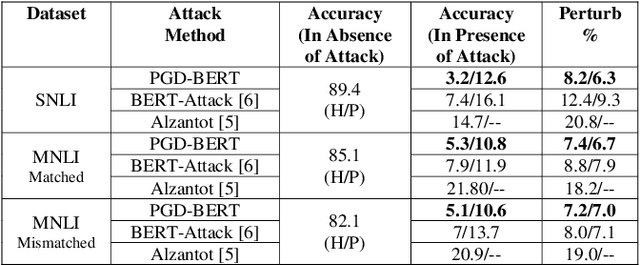

Adversarial attacks against deep learning models represent a major threat to the security and reliability of natural language processing (NLP) systems. In this paper, we propose a modification to the BERT-Attack framework, integrating Projected Gradient Descent (PGD) to enhance its effectiveness and robustness. The original BERT-Attack, designed for generating adversarial examples against BERT-based models, suffers from limitations such as a fixed perturbation budget and a lack of consideration for semantic similarity. The proposed approach in this work, PGD-BERT-Attack, addresses these limitations by leveraging PGD to iteratively generate adversarial examples while ensuring both imperceptibility and semantic similarity to the original input. Extensive experiments are conducted to evaluate the performance of PGD-BERT-Attack compared to the original BERT-Attack and other baseline methods. The results demonstrate that PGD-BERT-Attack achieves higher success rates in causing misclassification while maintaining low perceptual changes. Furthermore, PGD-BERT-Attack produces adversarial instances that exhibit greater semantic resemblance to the initial input, enhancing their applicability in real-world scenarios. Overall, the proposed modification offers a more effective and robust approach to adversarial attacks on BERT-based models, thus contributing to the advancement of defense against attacks on NLP systems.
Saliency Attention and Semantic Similarity-Driven Adversarial Perturbation
Jun 18, 2024
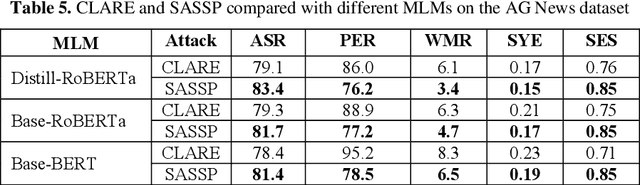
In this paper, we introduce an enhanced textual adversarial attack method, known as Saliency Attention and Semantic Similarity driven adversarial Perturbation (SASSP). The proposed scheme is designed to improve the effectiveness of contextual perturbations by integrating saliency, attention, and semantic similarity. Traditional adversarial attack methods often struggle to maintain semantic consistency and coherence while effectively deceiving target models. Our proposed approach addresses these challenges by incorporating a three-pronged strategy for word selection and perturbation. First, we utilize a saliency-based word selection to prioritize words for modification based on their importance to the model's prediction. Second, attention mechanisms are employed to focus perturbations on contextually significant words, enhancing the attack's efficacy. Finally, an advanced semantic similarity-checking method is employed that includes embedding-based similarity and paraphrase detection. By leveraging models like Sentence-BERT for embedding similarity and fine-tuned paraphrase detection models from the Sentence Transformers library, the scheme ensures that the perturbed text remains contextually appropriate and semantically consistent with the original. Empirical evaluations demonstrate that SASSP generates adversarial examples that not only maintain high semantic fidelity but also effectively deceive state-of-the-art natural language processing models. Moreover, in comparison to the original scheme of contextual perturbation CLARE, SASSP has yielded a higher attack success rate and lower word perturbation rate.
Boosting Digital Safeguards: Blending Cryptography and Steganography
Apr 11, 2024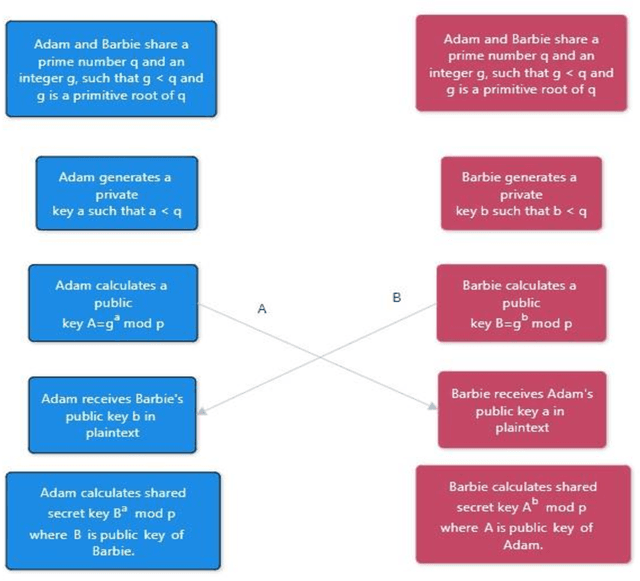
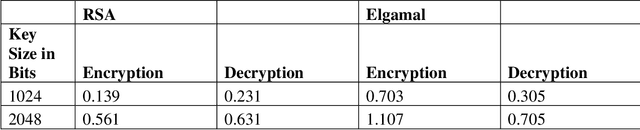
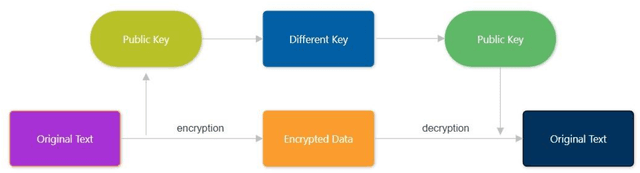

In today's digital age, the internet is essential for communication and the sharing of information, creating a critical need for sophisticated data security measures to prevent unauthorized access and exploitation. Cryptography encrypts messages into a cipher text that is incomprehensible to unauthorized readers, thus safeguarding data during its transmission. Steganography, on the other hand, originates from the Greek term for "covered writing" and involves the art of hiding data within another medium, thereby facilitating covert communication by making the message invisible. This proposed approach takes advantage of the latest advancements in Artificial Intelligence (AI) and Deep Learning (DL), especially through the application of Generative Adversarial Networks (GANs), to improve upon traditional steganographic methods. By embedding encrypted data within another medium, our method ensures that the communication remains hidden from prying eyes. The application of GANs enables a smart, secure system that utilizes the inherent sensitivity of neural networks to slight alterations in data, enhancing the protection against detection. By merging the encryption techniques of cryptography with the hiding capabilities of steganography, and augmenting these with the strengths of AI, we introduce a comprehensive security system designed to maintain both the privacy and integrity of information. This system is crafted not just to prevent unauthorized access or modification of data, but also to keep the existence of the data hidden. This fusion of technologies tackles the core challenges of data security in the current era of open digital communication, presenting an advanced solution with the potential to transform the landscape of information security.