 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Image Classification: Defensive Strategies against FGSM and PGD Adversarial Attacks
Paper and Code
Aug 20, 2024

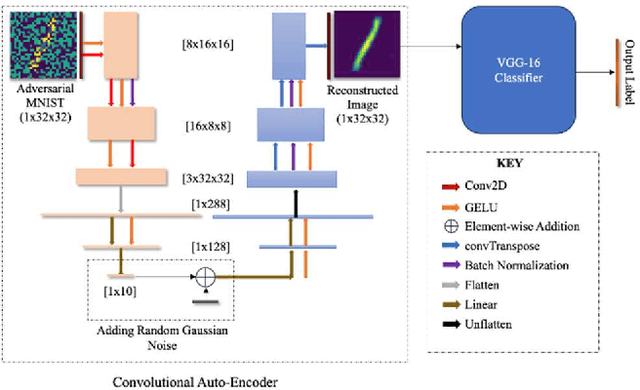
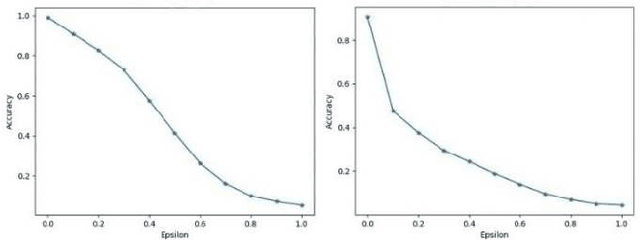
Adversarial attacks, particularly the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) pose significant threats to the robustness of deep learning models in image classification. This paper explores and refines defense mechanisms against these attacks to enhance the resilience of neural networks. We employ a combination of adversarial training and innovative preprocessing techniques, aiming to mitigate the impact of adversarial perturbations. Our methodology involves modifying input data before classification and investigating different model architectures and training strategies. Through rigorous evaluation of benchmark datasets, we demonstrate the effectiveness of our approach in defending against FGSM and PGD attacks. Our results show substantial improvements in model robustness compared to baseline methods, highlighting the potential of our defense strategies in real-world applications. This study contributes to the ongoing efforts to develop secure and reliable machine learning systems, offering practical insights and paving the way for future research in adversarial defense. By bridging theoretical advancements and practical implementation, we aim to enhance the trustworthiness of AI applications in safety-critical domains.