 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Text Generation with Dynamic Contextual Perturbation
Jun 10, 2025Adversarial attacks on Natural Language Processing (NLP) models expose vulnerabilities by introducing subtle perturbations to input text, often leading to misclassification while maintaining human readability. Existing methods typically focus on word-level or local text segment alterations, overlooking the broader context, which results in detectable or semantically inconsistent perturbations. We propose a novel adversarial text attack scheme named Dynamic Contextual Perturbation (DCP). DCP dynamically generates context-aware perturbations across sentences, paragraphs, and documents, ensuring semantic fidelity and fluency. Leveraging the capabilities of pre-trained language models, DCP iteratively refines perturbations through an adversarial objective function that balances the dual objectives of inducing model misclassification and preserving the naturalness of the text. This comprehensive approach allows DCP to produce more sophisticated and effective adversarial examples that better mimic natural language patterns. Our experimental results, conducted on various NLP models and datasets, demonstrate the efficacy of DCP in challenging the robustness of state-of-the-art NLP systems. By integrating dynamic contextual analysis, DCP significantly enhances the subtlety and impact of adversarial attacks. This study highlights the critical role of context in adversarial attacks and lays the groundwork for creating more robust NLP systems capable of withstanding sophisticated adversarial strategies.
* This is the accepted version of the paper, which was presented at IEEE CALCON. The conference was organized at Jadavpur University, Kolkata, from December 14 to 15, 2025. The paper is six pages long, and it consists of six tables and six figures. This is not the final camera-ready version of the paper
Adversarial Robustness through Dynamic Ensemble Learning
Dec 20, 2024Adversarial attacks pose a significant threat to the reliability of pre-trained language models (PLMs) such as GPT, BERT, RoBERTa, and T5. This paper presents Adversarial Robustness through Dynamic Ensemble Learning (ARDEL), a novel scheme designed to enhance the robustness of PLMs against such attacks. ARDEL leverages the diversity of multiple PLMs and dynamically adjusts the ensemble configuration based on input characteristics and detected adversarial patterns. Key components of ARDEL include a meta-model for dynamic weighting, an adversarial pattern detection module, and adversarial training with regularization techniques. Comprehensive evaluations using standardized datasets and various adversarial attack scenarios demonstrate that ARDEL significantly improves robustness compared to existing methods. By dynamically reconfiguring the ensemble to prioritize the most robust models for each input, ARDEL effectively reduces attack success rates and maintains higher accuracy under adversarial conditions. This work contributes to the broader goal of developing more secure and trustworthy AI systems for real-world NLP applications, offering a practical and scalable solution to enhance adversarial resilience in PLMs.
Robust Image Classification: Defensive Strategies against FGSM and PGD Adversarial Attacks
Aug 20, 2024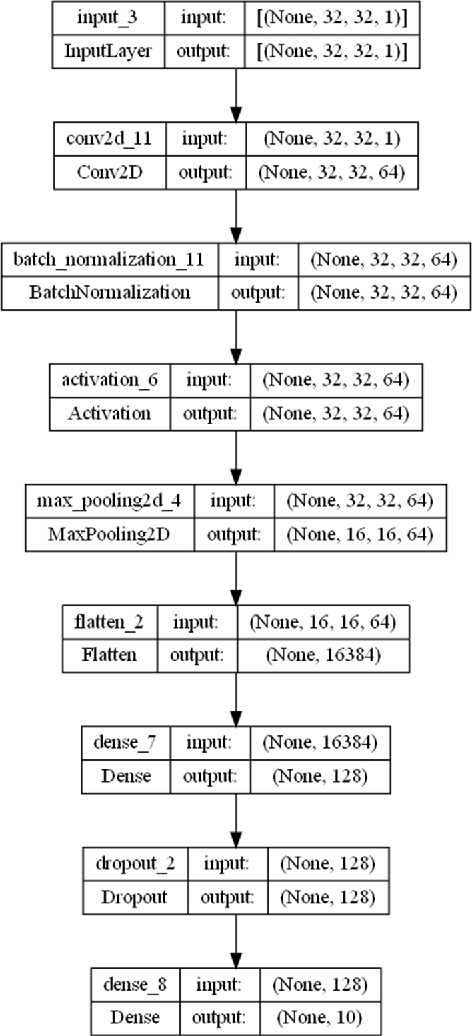

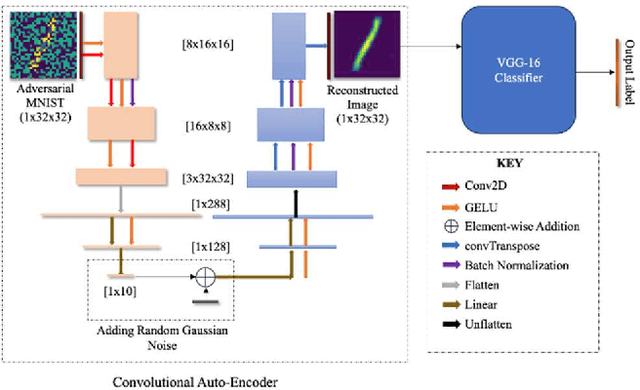
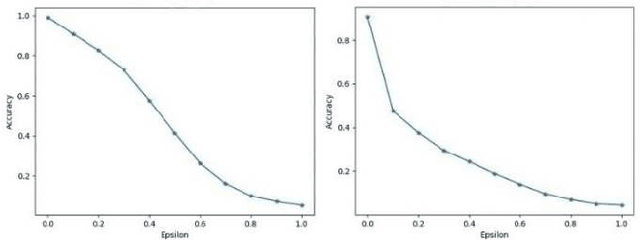
Adversarial attacks, particularly the Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) pose significant threats to the robustness of deep learning models in image classification. This paper explores and refines defense mechanisms against these attacks to enhance the resilience of neural networks. We employ a combination of adversarial training and innovative preprocessing techniques, aiming to mitigate the impact of adversarial perturbations. Our methodology involves modifying input data before classification and investigating different model architectures and training strategies. Through rigorous evaluation of benchmark datasets, we demonstrate the effectiveness of our approach in defending against FGSM and PGD attacks. Our results show substantial improvements in model robustness compared to baseline methods, highlighting the potential of our defense strategies in real-world applications. This study contributes to the ongoing efforts to develop secure and reliable machine learning systems, offering practical insights and paving the way for future research in adversarial defense. By bridging theoretical advancements and practical implementation, we aim to enhance the trustworthiness of AI applications in safety-critical domains.
Enhancing Adversarial Text Attacks on BERT Models with Projected Gradient Descent
Jul 29, 2024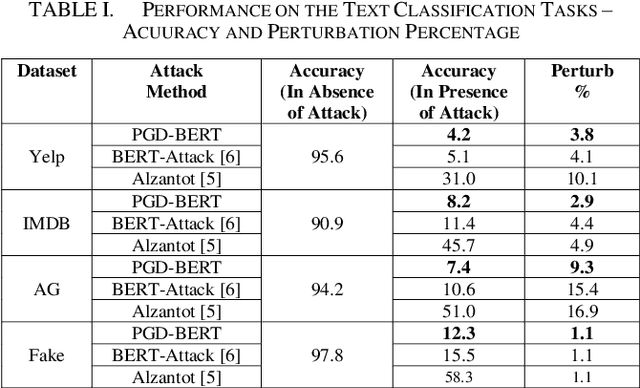
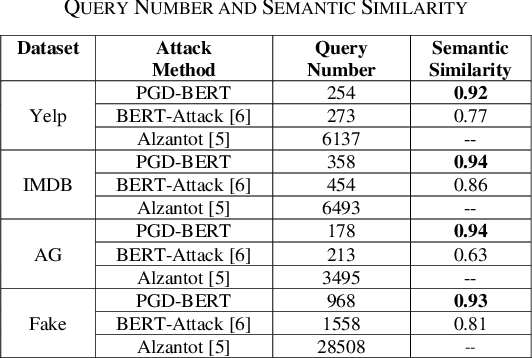
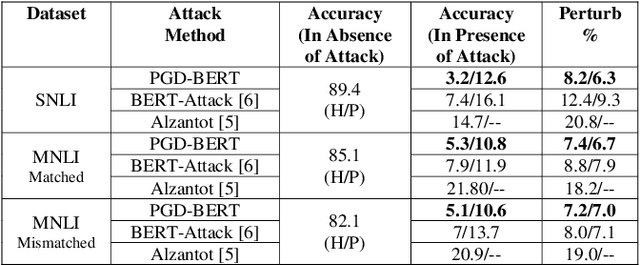

Adversarial attacks against deep learning models represent a major threat to the security and reliability of natural language processing (NLP) systems. In this paper, we propose a modification to the BERT-Attack framework, integrating Projected Gradient Descent (PGD) to enhance its effectiveness and robustness. The original BERT-Attack, designed for generating adversarial examples against BERT-based models, suffers from limitations such as a fixed perturbation budget and a lack of consideration for semantic similarity. The proposed approach in this work, PGD-BERT-Attack, addresses these limitations by leveraging PGD to iteratively generate adversarial examples while ensuring both imperceptibility and semantic similarity to the original input. Extensive experiments are conducted to evaluate the performance of PGD-BERT-Attack compared to the original BERT-Attack and other baseline methods. The results demonstrate that PGD-BERT-Attack achieves higher success rates in causing misclassification while maintaining low perceptual changes. Furthermore, PGD-BERT-Attack produces adversarial instances that exhibit greater semantic resemblance to the initial input, enhancing their applicability in real-world scenarios. Overall, the proposed modification offers a more effective and robust approach to adversarial attacks on BERT-based models, thus contributing to the advancement of defense against attacks on NLP systems.
Saliency Attention and Semantic Similarity-Driven Adversarial Perturbation
Jun 18, 2024
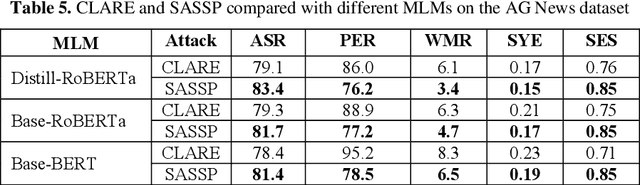
In this paper, we introduce an enhanced textual adversarial attack method, known as Saliency Attention and Semantic Similarity driven adversarial Perturbation (SASSP). The proposed scheme is designed to improve the effectiveness of contextual perturbations by integrating saliency, attention, and semantic similarity. Traditional adversarial attack methods often struggle to maintain semantic consistency and coherence while effectively deceiving target models. Our proposed approach addresses these challenges by incorporating a three-pronged strategy for word selection and perturbation. First, we utilize a saliency-based word selection to prioritize words for modification based on their importance to the model's prediction. Second, attention mechanisms are employed to focus perturbations on contextually significant words, enhancing the attack's efficacy. Finally, an advanced semantic similarity-checking method is employed that includes embedding-based similarity and paraphrase detection. By leveraging models like Sentence-BERT for embedding similarity and fine-tuned paraphrase detection models from the Sentence Transformers library, the scheme ensures that the perturbed text remains contextually appropriate and semantically consistent with the original. Empirical evaluations demonstrate that SASSP generates adversarial examples that not only maintain high semantic fidelity but also effectively deceive state-of-the-art natural language processing models. Moreover, in comparison to the original scheme of contextual perturbation CLARE, SASSP has yielded a higher attack success rate and lower word perturbation rate.
Generative AI-Based Text Generation Methods Using Pre-Trained GPT-2 Model
Apr 02, 2024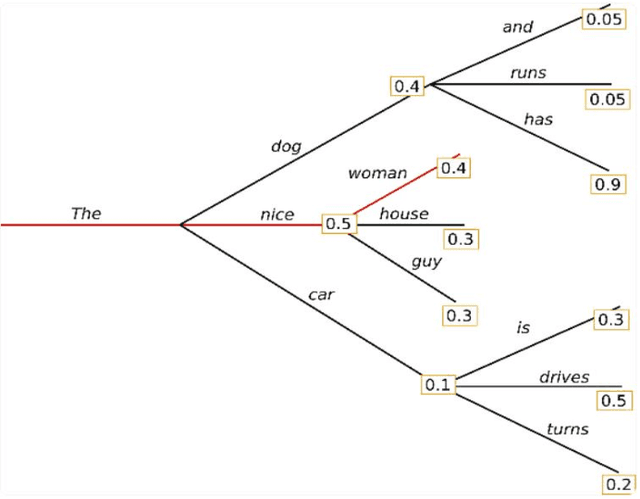
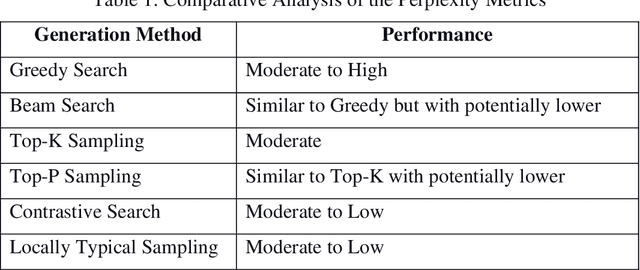
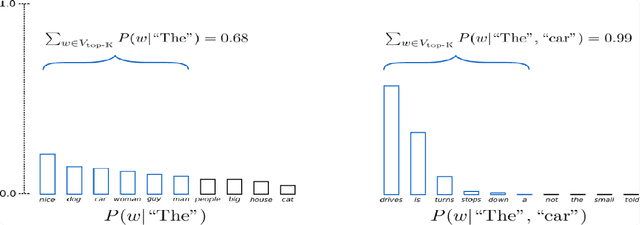
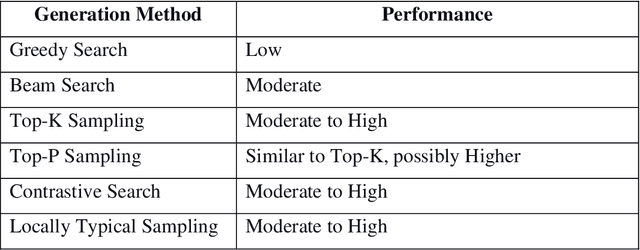
This work delved into the realm of automatic text generation, exploring a variety of techniques ranging from traditional deterministic approaches to more modern stochastic methods. Through analysis of greedy search, beam search, top-k sampling, top-p sampling, contrastive searching, and locally typical searching, this work has provided valuable insights into the strengths, weaknesses, and potential applications of each method. Each text-generating method is evaluated using several standard metrics and a comparative study has been made on the performance of the approaches. Finally, some future directions of research in the field of automatic text generation are also identified.
A Modified Word Saliency-Based Adversarial Attack on Text Classification Models
Mar 17, 2024This paper introduces a novel adversarial attack method targeting text classification models, termed the Modified Word Saliency-based Adversarial At-tack (MWSAA). The technique builds upon the concept of word saliency to strategically perturb input texts, aiming to mislead classification models while preserving semantic coherence. By refining the traditional adversarial attack approach, MWSAA significantly enhances its efficacy in evading detection by classification systems. The methodology involves first identifying salient words in the input text through a saliency estimation process, which prioritizes words most influential to the model's decision-making process. Subsequently, these salient words are subjected to carefully crafted modifications, guided by semantic similarity metrics to ensure that the altered text remains coherent and retains its original meaning. Empirical evaluations conducted on diverse text classification datasets demonstrate the effectiveness of the proposed method in generating adversarial examples capable of successfully deceiving state-of-the-art classification models. Comparative analyses with existing adversarial attack techniques further indicate the superiority of the proposed approach in terms of both attack success rate and preservation of text coherence.