 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Multimodal and Conversational AI on Learning Outcomes and Experience
Apr 02, 2026Multimodal Large Language Models (MLLMs) offer an opportunity to support multimedia learning through conversational systems grounded in educational content. However, while conversational AI is known to boost engagement, its impact on learning in visually-rich STEM domains remains under-explored. Moreover, there is limited understanding of how multimodality and conversationality jointly influence learning in generative AI systems. This work reports findings from a randomized controlled online study (N = 124) comparing three approaches to learning biology from textbook content: (1) a document-grounded conversational AI with interleaved text-and-image responses (MuDoC), (2) a document-grounded conversational AI with text-only responses (TexDoC), and (3) a textbook interface with semantic search and highlighting (DocSearch). Learners using MuDoC achieved the highest post-test scores and reported the most positive learning experience. Notably, while TexDoC was rated as significantly more engaging and easier to use than DocSearch, it led to the lowest post-test scores, revealing a disconnect between student perceptions and learning outcomes. Interpreted through the lens of the Cognitive Load Theory, these findings suggest that conversationality reduces extraneous load, while visual-verbal integration induced by multimodality increases germane load, leading to better learning outcomes. When conversationality is not complemented by multimodality, reduced cognitive effort may instead inflate perceived understanding without improving learning outcomes.
MetaCues: Enabling Critical Engagement with Generative AI for Information Seeking and Sensemaking
Mar 20, 2026Generative AI (GenAI) search tools are increasingly used for information seeking, yet their design tends to encourage cognitive offloading, which may lead to passive engagement, selective attention, and informational homogenization. Effective use requires metacognitive engagement to craft good prompts, verify AI outputs, and critically engage with information. We developed MetaCues, a novel GenAI-based interactive tool for information seeking that delivers metacognitive cues alongside AI responses and a note-taking interface to guide users' search and associated learning. Through an online study (N = 146), we compared MetaCues to a baseline tool without cues, across two broad search topics that required participants to explore diverse perspectives in order to make informed judgments. Preliminary findings regarding participants' search behavior show that MetaCues leads to increased confidence in attitudinal judgments about the search topic as well as broader inquiry, with the latter effect emerging primarily for the topic that was less controversial and with which participants had relatively less familiarity. Accordingly, we outline directions for future qualitative exploration of search interactions and inquiry patterns.
"They are uncultured": Unveiling Covert Harms and Social Threats in LLM Generated Conversations
May 08, 2024



Large language models (LLMs) have emerged as an integral part of modern societies, powering user-facing applications such as personal assistants and enterprise applications like recruitment tools. Despite their utility, research indicates that LLMs perpetuate systemic biases. Yet, prior works on LLM harms predominantly focus on Western concepts like race and gender, often overlooking cultural concepts from other parts of the world. Additionally, these studies typically investigate "harm" as a singular dimension, ignoring the various and subtle forms in which harms manifest. To address this gap, we introduce the Covert Harms and Social Threats (CHAST), a set of seven metrics grounded in social science literature. We utilize evaluation models aligned with human assessments to examine the presence of covert harms in LLM-generated conversations, particularly in the context of recruitment. Our experiments reveal that seven out of the eight LLMs included in this study generated conversations riddled with CHAST, characterized by malign views expressed in seemingly neutral language unlikely to be detected by existing methods. Notably, these LLMs manifested more extreme views and opinions when dealing with non-Western concepts like caste, compared to Western ones such as race.
Generative AI-Based Text Generation Methods Using Pre-Trained GPT-2 Model
Apr 02, 2024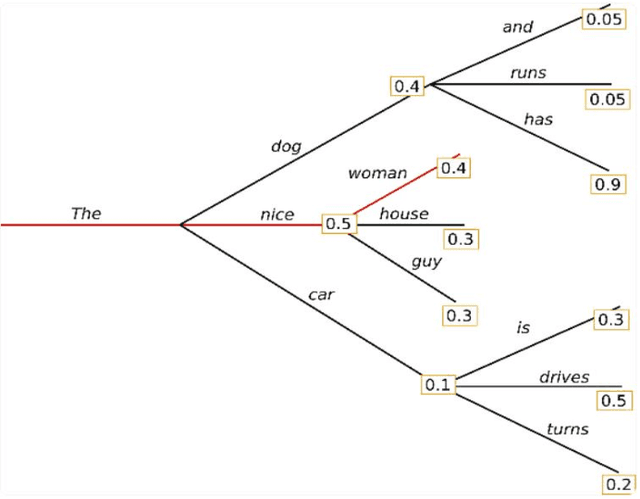
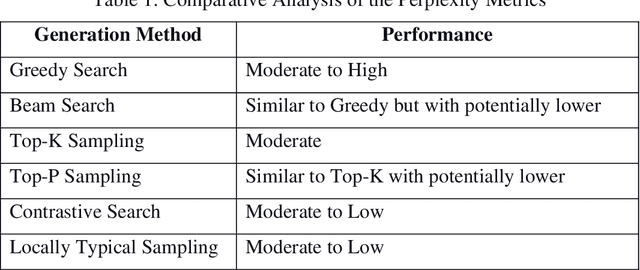
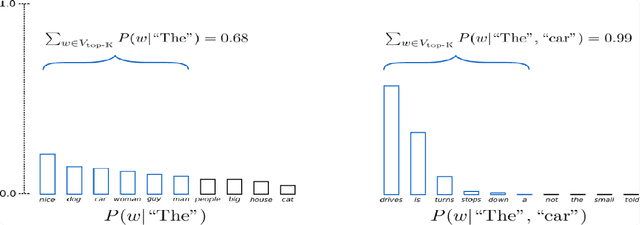
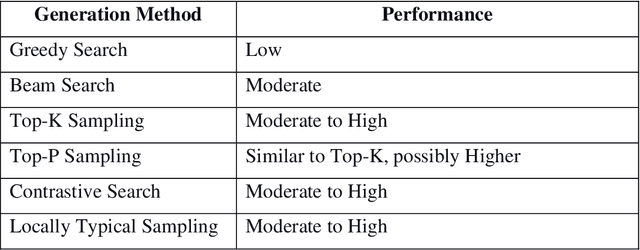
This work delved into the realm of automatic text generation, exploring a variety of techniques ranging from traditional deterministic approaches to more modern stochastic methods. Through analysis of greedy search, beam search, top-k sampling, top-p sampling, contrastive searching, and locally typical searching, this work has provided valuable insights into the strengths, weaknesses, and potential applications of each method. Each text-generating method is evaluated using several standard metrics and a comparative study has been made on the performance of the approaches. Finally, some future directions of research in the field of automatic text generation are also identified.
Automating Human Tutor-Style Programming Feedback: Leveraging GPT-4 Tutor Model for Hint Generation and GPT-3.5 Student Model for Hint Validation
Oct 05, 2023



Generative AI and large language models hold great promise in enhancing programming education by automatically generating individualized feedback for students. We investigate the role of generative AI models in providing human tutor-style programming hints to help students resolve errors in their buggy programs. Recent works have benchmarked state-of-the-art models for various feedback generation scenarios; however, their overall quality is still inferior to human tutors and not yet ready for real-world deployment. In this paper, we seek to push the limits of generative AI models toward providing high-quality programming hints and develop a novel technique, GPT4Hints-GPT3.5Val. As a first step, our technique leverages GPT-4 as a ``tutor'' model to generate hints -- it boosts the generative quality by using symbolic information of failing test cases and fixes in prompts. As a next step, our technique leverages GPT-3.5, a weaker model, as a ``student'' model to further validate the hint quality -- it performs an automatic quality validation by simulating the potential utility of providing this feedback. We show the efficacy of our technique via extensive evaluation using three real-world datasets of Python programs covering a variety of concepts ranging from basic algorithms to regular expressions and data analysis using pandas library.
Reimagining GNN Explanations with ideas from Tabular Data
Jun 23, 2021
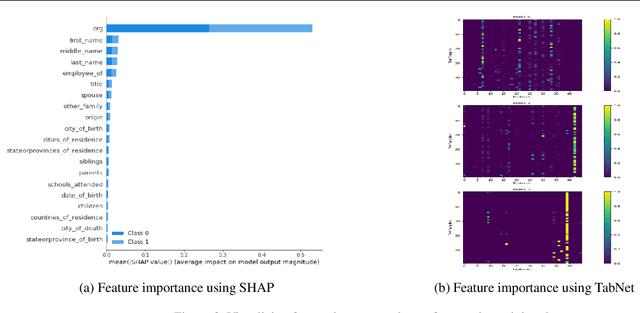
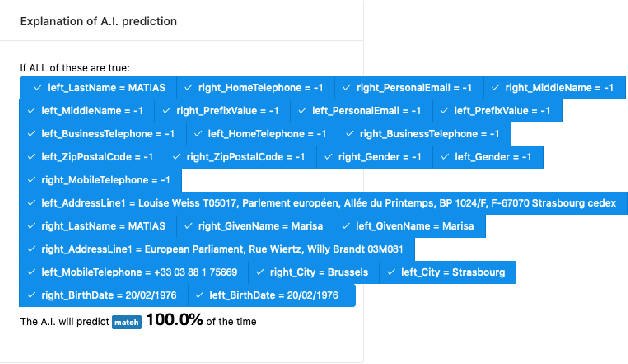

Explainability techniques for Graph Neural Networks still have a long way to go compared to explanations available for both neural and decision decision tree-based models trained on tabular data. Using a task that straddles both graphs and tabular data, namely Entity Matching, we comment on key aspects of explainability that are missing in GNN model explanations.
Adversarial Adaptation of Scene Graph Models for Understanding Civic Issues
Jan 29, 2019
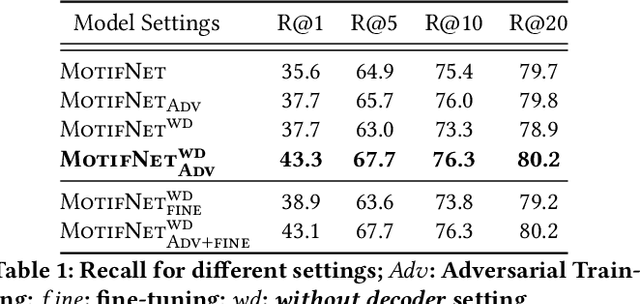
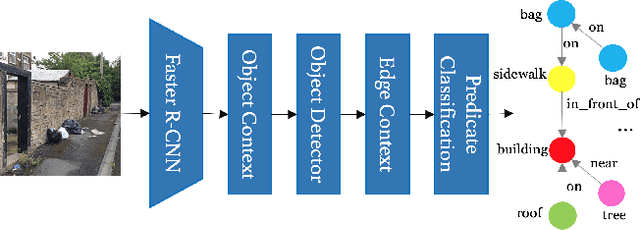
Citizen engagement and technology usage are two emerging trends driven by smart city initiatives. Governments around the world are adopting technology for faster resolution of civic issues. Typically, citizens report issues, such as broken roads, garbage dumps, etc. through web portals and mobile apps, in order for the government authorities to take appropriate actions. Several mediums -- text, image, audio, video -- are used to report these issues. Through a user study with 13 citizens and 3 authorities, we found that image is the most preferred medium to report civic issues. However, analyzing civic issue related images is challenging for the authorities as it requires manual effort. Moreover, previous works have been limited to identifying a specific set of issues from images. In this work, given an image, we propose to generate a Civic Issue Graph consisting of a set of objects and the semantic relations between them, which are representative of the underlying civic issue. We also release two multi-modal (text and images) datasets, that can help in further analysis of civic issues from images. We present a novel approach for adversarial training of existing scene graph models that enables the use of scene graphs for new applications in the absence of any labelled training data. We conduct several experiments to analyze the efficacy of our approach, and using human evaluation, we establish the appropriateness of our model at representing different civic issues.