 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiAgentBench: Benchmarking Sensemaking Capabilities of Information-Seeking Agents on High-Traffic Topics
Mar 04, 2026With the emergence of search-enabled generative QA systems, users are increasingly turning to tools that browse, aggregate, and reconcile evidence across multiple sources on their behalf. Yet many widely used QA benchmarks remain answerable by retrieving a single relevant passage, making them poorly suited for measuring cross-source sensemaking, such as integrating evidence, tracking causal links, and resolving dependencies across facets of a topic. We present iAgentBench, a dynamic ODQA benchmark that targets these higher-level information needs while keeping questions natural and grounded in realistic information-seeking behavior. iAgentBench draws seed topics from real-world attention signals and uses common user intent patterns to construct user-like questions whose answers require combining evidence from multiple sources, not just extracting a single snippet. Each instance is released with traceable evidence and auditable intermediate artifacts that support contamination checks and enable fine-grained diagnosis of failures in retrieval versus synthesis. Experiments across multiple LLMs show that retrieval improves accuracy, but retrieval alone does not reliably resolve these questions, underscoring the need to evaluate evidence use, not just evidence access.
ClaimDB: A Fact Verification Benchmark over Large Structured Data
Jan 21, 2026Despite substantial progress in fact-verification benchmarks, claims grounded in large-scale structured data remain underexplored. In this work, we introduce ClaimDB, the first fact-verification benchmark where the evidence for claims is derived from compositions of millions of records and multiple tables. ClaimDB consists of 80 unique real-life databases covering a wide range of domains, from governance and healthcare to media, education and the natural sciences. At this scale, verification approaches that rely on "reading" the evidence break down, forcing a timely shift toward reasoning in executable programs. We conduct extensive experiments with 30 state-of-the-art proprietary and open-source (below 70B) LLMs and find that none exceed 83% accuracy, with more than half below 55%. Our analysis also reveals that both closed- and open-source models struggle with abstention -- the ability to admit that there is no evidence to decide -- raising doubts about their reliability in high-stakes data analysis. We release the benchmark, code, and the LLM leaderboard at https://claimdb.github.io .
Dynamic-KGQA: A Scalable Framework for Generating Adaptive Question Answering Datasets
Mar 06, 2025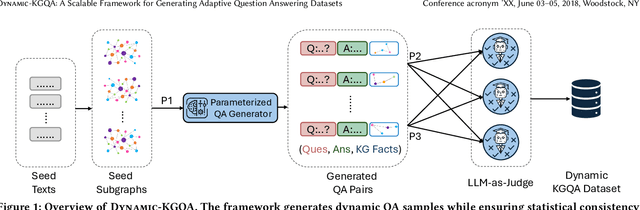
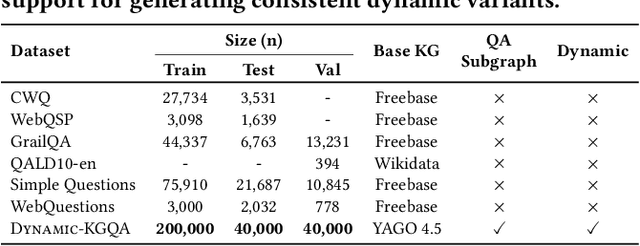
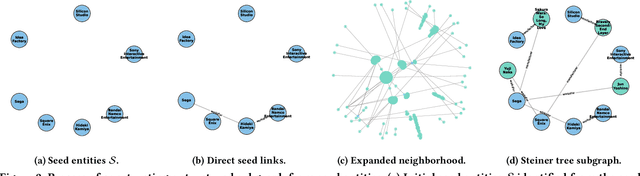

As question answering (QA) systems advance alongside the rapid evolution of foundation models, the need for robust, adaptable, and large-scale evaluation benchmarks becomes increasingly critical. Traditional QA benchmarks are often static and publicly available, making them susceptible to data contamination and memorization by large language models (LLMs). Consequently, static benchmarks may overestimate model generalization and hinder a reliable assessment of real-world performance. In this work, we introduce Dynamic-KGQA, a scalable framework for generating adaptive QA datasets from knowledge graphs (KGs), designed to mitigate memorization risks while maintaining statistical consistency across iterations. Unlike fixed benchmarks, Dynamic-KGQA generates a new dataset variant on every run while preserving the underlying distribution, enabling fair and reproducible evaluations. Furthermore, our framework provides fine-grained control over dataset characteristics, supporting domain-specific and topic-focused QA dataset generation. Additionally, Dynamic-KGQA produces compact, semantically coherent subgraphs that facilitate both training and evaluation of KGQA models, enhancing their ability to leverage structured knowledge effectively. To align with existing evaluation protocols, we also provide static large-scale train/test/validation splits, ensuring comparability with prior methods. By introducing a dynamic, customizable benchmarking paradigm, Dynamic-KGQA enables a more rigorous and adaptable evaluation of QA systems.
"They are uncultured": Unveiling Covert Harms and Social Threats in LLM Generated Conversations
May 08, 2024



Large language models (LLMs) have emerged as an integral part of modern societies, powering user-facing applications such as personal assistants and enterprise applications like recruitment tools. Despite their utility, research indicates that LLMs perpetuate systemic biases. Yet, prior works on LLM harms predominantly focus on Western concepts like race and gender, often overlooking cultural concepts from other parts of the world. Additionally, these studies typically investigate "harm" as a singular dimension, ignoring the various and subtle forms in which harms manifest. To address this gap, we introduce the Covert Harms and Social Threats (CHAST), a set of seven metrics grounded in social science literature. We utilize evaluation models aligned with human assessments to examine the presence of covert harms in LLM-generated conversations, particularly in the context of recruitment. Our experiments reveal that seven out of the eight LLMs included in this study generated conversations riddled with CHAST, characterized by malign views expressed in seemingly neutral language unlikely to be detected by existing methods. Notably, these LLMs manifested more extreme views and opinions when dealing with non-Western concepts like caste, compared to Western ones such as race.
ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs
Mar 12, 2024In the midst of widespread misinformation and disinformation through social media and the proliferation of AI-generated texts, it has become increasingly difficult for people to validate and trust information they encounter. Many fact-checking approaches and tools have been developed, but they often lack appropriate explainability or granularity to be useful in various contexts. A text validation method that is easy to use, accessible, and can perform fine-grained evidence attribution has become crucial. More importantly, building user trust in such a method requires presenting the rationale behind each prediction, as research shows this significantly influences people's belief in automated systems. It is also paramount to localize and bring users' attention to the specific problematic content, instead of providing simple blanket labels. In this paper, we present $\textit{ClaimVer, a human-centric framework}$ tailored to meet users' informational and verification needs by generating rich annotations and thereby reducing cognitive load. Designed to deliver comprehensive evaluations of texts, it highlights each claim, verifies it against a trusted knowledge graph (KG), presents the evidence, and provides succinct, clear explanations for each claim prediction. Finally, our framework introduces an attribution score, enhancing applicability across a wide range of downstream tasks.
Detecting Spurious Correlations via Robust Visual Concepts in Real and AI-Generated Image Classification
Nov 16, 2023



Often machine learning models tend to automatically learn associations present in the training data without questioning their validity or appropriateness. This undesirable property is the root cause of the manifestation of spurious correlations, which render models unreliable and prone to failure in the presence of distribution shifts. Research shows that most methods attempting to remedy spurious correlations are only effective for a model's known spurious associations. Current spurious correlation detection algorithms either rely on extensive human annotations or are too restrictive in their formulation. Moreover, they rely on strict definitions of visual artifacts that may not apply to data produced by generative models, as they are known to hallucinate contents that do not conform to standard specifications. In this work, we introduce a general-purpose method that efficiently detects potential spurious correlations, and requires significantly less human interference in comparison to the prior art. Additionally, the proposed method provides intuitive explanations while eliminating the need for pixel-level annotations. We demonstrate the proposed method's tolerance to the peculiarity of AI-generated images, which is a considerably challenging task, one where most of the existing methods fall short. Consequently, our method is also suitable for detecting spurious correlations that may propagate to downstream applications originating from generative models.
Addressing Weak Decision Boundaries in Image Classification by Leveraging Web Search and Generative Models
Oct 30, 2023



Machine learning (ML) technologies are known to be riddled with ethical and operational problems, however, we are witnessing an increasing thrust by businesses to deploy them in sensitive applications. One major issue among many is that ML models do not perform equally well for underrepresented groups. This puts vulnerable populations in an even disadvantaged and unfavorable position. We propose an approach that leverages the power of web search and generative models to alleviate some of the shortcomings of discriminative models. We demonstrate our method on an image classification problem using ImageNet's People Subtree subset, and show that it is effective in enhancing robustness and mitigating bias in certain classes that represent vulnerable populations (e.g., female doctor of color). Our new method is able to (1) identify weak decision boundaries for such classes; (2) construct search queries for Google as well as text for generating images through DALL-E 2 and Stable Diffusion; and (3) show how these newly captured training samples could alleviate population bias issue. While still improving the model's overall performance considerably, we achieve a significant reduction (77.30\%) in the model's gender accuracy disparity. In addition to these improvements, we observed a notable enhancement in the classifier's decision boundary, as it is characterized by fewer weakspots and an increased separation between classes. Although we showcase our method on vulnerable populations in this study, the proposed technique is extendable to a wide range of problems and domains.