 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking Ahead: Prospection-Guided Retrieval of Memory with Language Models
May 13, 2026Long-horizon personalization requires dialogue assistants to retrieve user-specific facts from extended interaction histories. In practice, many relevant facts often have low semanticsimilarity to the query under dense retrieval. Standard Retrieval-Augmented Generation (RAG) and GraphRAG systems are still largely retrospective: they rely on embedding similarity to the query or on fixed graph traversals, so they often miss facts that matter for the user's needs but lie far from the query in embedding space. Inspired by prospection, the human ability to use imagined futures as cues for recall, we introduce Prospection-Guided Retrieval (PGR), which decouples retrieval from how memories are stored. Given a user query, PGR first expands the goal into a short Tree-of-Thought (ToT) or linear chain of plausible next steps, and uses these steps as retrieval probes rather than relying on the original query alone. The facts retrieved by these probes are then used to personalize the next round of prospection, enabling PGR to uncover additional memories that become relevant only after the simulation is grounded in the user's history. We also introduce MemoryQuest, a challenging multi-session benchmark in which each query is annotated with 3--5 dated reference facts subject to a low query-reference similarity constraint. Across 1,625 queries spanning 185 user profiles from 3 publicly available datasets, PGR-TOT substantially improves retrieval, including nearly 3x recall on MemoryQuest over the strongest baseline. In pairwise LLM-as-judge comparisons against baselines, PGR-generated responses are preferred on 89--98% of queries, with blinded human annotations on held-out subsets showing the same trend. Overall, the results demonstrate that explicit prospection yields large gains in long-horizon retrieval and response quality relative to similarity-only baselines.
Beyond Cooperative Simulators: Generating Realistic User Personas for Robust Evaluation of LLM Agents
May 13, 2026Large Language Model (LLM) agents are increasingly deployed in settings where they interact with a wide variety of people, including users who are unclear, impatient, or reluctant to share information. However, collecting real interaction data at scale remains expensive. The field has turned to LLM-based user simulators as stand-ins, but these simulators inherit the behavior of their underlying models: cooperative and homogeneous. As a result, agents that appear strong in simulation often fail under the unseen, diverse communication patterns of real users. To narrow this gap, we introduce Persona Policies (PPol), a plug-and-play control layer that induces realistic behavioral variation in user simulators while preserving the original task goals. Rather than hand-crafting personas, we cast persona generation as an LLM-driven evolutionary program search that optimizes a Python generator to discover behaviors and translate them into task-preserving roleplay policies. Candidate generators are guided by a multi-objective fitness score combining human-likeness with broad coverage of human behavioral patterns. Once optimized, the generator produces a diverse population of human-like personas for any task in the domain. Across tau^2-bench retail and airline domains, evolved PPol programs yield 33-62% absolute gains in fitness score over the baseline simulator. In a blinded evaluation, annotators rated PPol-conditioned users as human 80.4% of the time, close to real human traces and nearly twice as frequently as baseline simulators. Agents trained with PPol are more robust to challenging, out-of-distribution behaviors, improving task success by +17% relative to training only on existing simulated interactions. This offers a novel approach to strengthen simulator-based evaluation and training without changing tasks or rewards.
iAgentBench: Benchmarking Sensemaking Capabilities of Information-Seeking Agents on High-Traffic Topics
Mar 04, 2026With the emergence of search-enabled generative QA systems, users are increasingly turning to tools that browse, aggregate, and reconcile evidence across multiple sources on their behalf. Yet many widely used QA benchmarks remain answerable by retrieving a single relevant passage, making them poorly suited for measuring cross-source sensemaking, such as integrating evidence, tracking causal links, and resolving dependencies across facets of a topic. We present iAgentBench, a dynamic ODQA benchmark that targets these higher-level information needs while keeping questions natural and grounded in realistic information-seeking behavior. iAgentBench draws seed topics from real-world attention signals and uses common user intent patterns to construct user-like questions whose answers require combining evidence from multiple sources, not just extracting a single snippet. Each instance is released with traceable evidence and auditable intermediate artifacts that support contamination checks and enable fine-grained diagnosis of failures in retrieval versus synthesis. Experiments across multiple LLMs show that retrieval improves accuracy, but retrieval alone does not reliably resolve these questions, underscoring the need to evaluate evidence use, not just evidence access.
Knowing Isn't Understanding: Re-grounding Generative Proactivity with Epistemic and Behavioral Insight
Feb 16, 2026Generative AI agents equate understanding with resolving explicit queries, an assumption that confines interaction to what users can articulate. This assumption breaks down when users themselves lack awareness of what is missing, risky, or worth considering. In such conditions, proactivity is not merely an efficiency enhancement, but an epistemic necessity. We refer to this condition as epistemic incompleteness: where progress depends on engaging with unknown unknowns for effective partnership. Existing approaches to proactivity remain narrowly anticipatory, extrapolating from past behavior and presuming that goals are already well defined, thereby failing to support users meaningfully. However, surfacing possibilities beyond a user's current awareness is not inherently beneficial. Unconstrained proactive interventions can misdirect attention, overwhelm users, or introduce harm. Proactive agents, therefore, require behavioral grounding: principled constraints on when, how, and to what extent an agent should intervene. We advance the position that generative proactivity must be grounded both epistemically and behaviorally. Drawing on the philosophy of ignorance and research on proactive behavior, we argue that these theories offer critical guidance for designing agents that can engage responsibly and foster meaningful partnerships.
ClaimDB: A Fact Verification Benchmark over Large Structured Data
Jan 21, 2026Despite substantial progress in fact-verification benchmarks, claims grounded in large-scale structured data remain underexplored. In this work, we introduce ClaimDB, the first fact-verification benchmark where the evidence for claims is derived from compositions of millions of records and multiple tables. ClaimDB consists of 80 unique real-life databases covering a wide range of domains, from governance and healthcare to media, education and the natural sciences. At this scale, verification approaches that rely on "reading" the evidence break down, forcing a timely shift toward reasoning in executable programs. We conduct extensive experiments with 30 state-of-the-art proprietary and open-source (below 70B) LLMs and find that none exceed 83% accuracy, with more than half below 55%. Our analysis also reveals that both closed- and open-source models struggle with abstention -- the ability to admit that there is no evidence to decide -- raising doubts about their reliability in high-stakes data analysis. We release the benchmark, code, and the LLM leaderboard at https://claimdb.github.io .
The PROPER Approach to Proactivity: Benchmarking and Advancing Knowledge Gap Navigation
Jan 16, 2026Most language-based assistants follow a reactive ask-and-respond paradigm, requiring users to explicitly state their needs. As a result, relevant but unexpressed needs often go unmet. Existing proactive agents attempt to address this gap either by eliciting further clarification, preserving this burden, or by extrapolating future needs from context, often leading to unnecessary or mistimed interventions. We introduce ProPer, Proactivity-driven Personalized agents, a novel two-agent architecture consisting of a Dimension Generating Agent (DGA) and a Response Generating Agent (RGA). DGA, a fine-tuned LLM agent, leverages explicit user data to generate multiple implicit dimensions (latent aspects relevant to the user's task but not considered by the user) or knowledge gaps. These dimensions are selectively filtered using a reranker based on quality, diversity, and task relevance. RGA then balances explicit and implicit dimensions to tailor personalized responses with timely and proactive interventions. We evaluate ProPer across multiple domains using a structured, gap-aware rubric that measures coverage, initiative appropriateness, and intent alignment. Our results show that ProPer improves quality scores and win rates across all domains, achieving up to 84% gains in single-turn evaluation and consistent dominance in multi-turn interactions.
I Think, Therefore I Am Under-Qualified? A Benchmark for Evaluating Linguistic Shibboleth Detection in LLM Hiring Evaluations
Aug 06, 2025This paper introduces a comprehensive benchmark for evaluating how Large Language Models (LLMs) respond to linguistic shibboleths: subtle linguistic markers that can inadvertently reveal demographic attributes such as gender, social class, or regional background. Through carefully constructed interview simulations using 100 validated question-response pairs, we demonstrate how LLMs systematically penalize certain linguistic patterns, particularly hedging language, despite equivalent content quality. Our benchmark generates controlled linguistic variations that isolate specific phenomena while maintaining semantic equivalence, which enables the precise measurement of demographic bias in automated evaluation systems. We validate our approach along multiple linguistic dimensions, showing that hedged responses receive 25.6% lower ratings on average, and demonstrate the benchmark's effectiveness in identifying model-specific biases. This work establishes a foundational framework for detecting and measuring linguistic discrimination in AI systems, with broad applications to fairness in automated decision-making contexts.
LLM-Driven Usefulness Judgment for Web Search Evaluation
Apr 19, 2025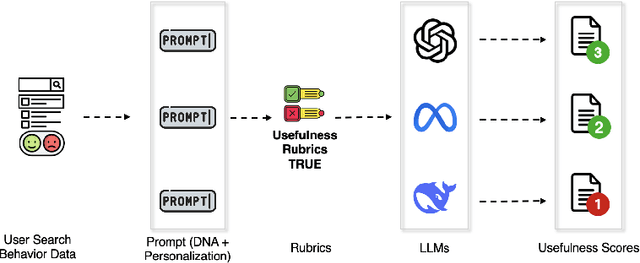

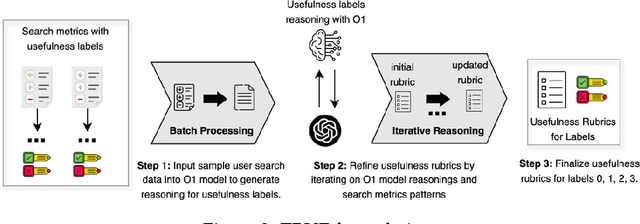
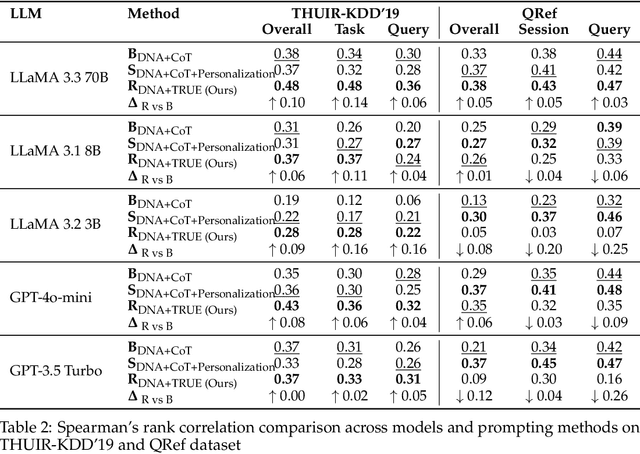
Evaluation is fundamental in optimizing search experiences and supporting diverse user intents in Information Retrieval (IR). Traditional search evaluation methods primarily rely on relevance labels, which assess how well retrieved documents match a user's query. However, relevance alone fails to capture a search system's effectiveness in helping users achieve their search goals, making usefulness a critical evaluation criterion. In this paper, we explore an alternative approach: LLM-generated usefulness labels, which incorporate both implicit and explicit user behavior signals to evaluate document usefulness. We propose Task-aware Rubric-based Usefulness Evaluation (TRUE), a rubric-driven evaluation method that employs iterative sampling and reasoning to model complex search behavior patterns. Our findings show that (i) LLMs can generate moderate usefulness labels by leveraging comprehensive search session history incorporating personalization and contextual understanding, and (ii) fine-tuned LLMs improve usefulness judgments when provided with structured search session contexts. Additionally, we examine whether LLMs can distinguish between relevance and usefulness, particularly in cases where this divergence impacts search success. We also conduct an ablation study to identify key metrics for accurate usefulness label generation, optimizing for token efficiency and cost-effectiveness in real-world applications. This study advances LLM-based usefulness evaluation by refining key user metrics, exploring LLM-generated label reliability, and ensuring feasibility for large-scale search systems.
LLM-Driven Usefulness Labeling for IR Evaluation
Mar 12, 2025In the information retrieval (IR) domain, evaluation plays a crucial role in optimizing search experiences and supporting diverse user intents. In the recent LLM era, research has been conducted to automate document relevance labels, as these labels have traditionally been assigned by crowd-sourced workers - a process that is both time and consuming and costly. This study focuses on LLM-generated usefulness labels, a crucial evaluation metric that considers the user's search intents and task objectives, an aspect where relevance falls short. Our experiment utilizes task-level, query-level, and document-level features along with user search behavior signals, which are essential in defining the usefulness of a document. Our research finds that (i) pre-trained LLMs can generate moderate usefulness labels by understanding the comprehensive search task session, (ii) pre-trained LLMs perform better judgement in short search sessions when provided with search session contexts. Additionally, we investigated whether LLMs can capture the unique divergence between relevance and usefulness, along with conducting an ablation study to identify the most critical metrics for accurate usefulness label generation. In conclusion, this work explores LLM-generated usefulness labels by evaluating critical metrics and optimizing for practicality in real-world settings.
Dynamic-KGQA: A Scalable Framework for Generating Adaptive Question Answering Datasets
Mar 06, 2025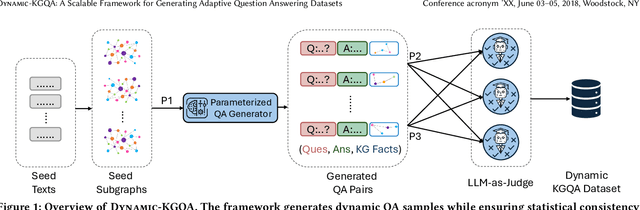
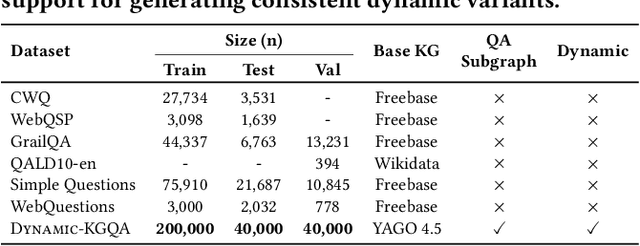
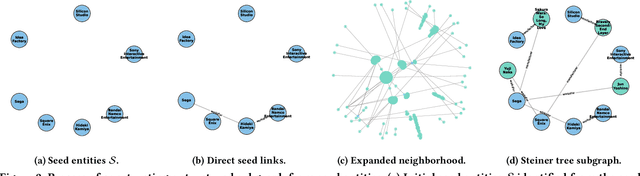

As question answering (QA) systems advance alongside the rapid evolution of foundation models, the need for robust, adaptable, and large-scale evaluation benchmarks becomes increasingly critical. Traditional QA benchmarks are often static and publicly available, making them susceptible to data contamination and memorization by large language models (LLMs). Consequently, static benchmarks may overestimate model generalization and hinder a reliable assessment of real-world performance. In this work, we introduce Dynamic-KGQA, a scalable framework for generating adaptive QA datasets from knowledge graphs (KGs), designed to mitigate memorization risks while maintaining statistical consistency across iterations. Unlike fixed benchmarks, Dynamic-KGQA generates a new dataset variant on every run while preserving the underlying distribution, enabling fair and reproducible evaluations. Furthermore, our framework provides fine-grained control over dataset characteristics, supporting domain-specific and topic-focused QA dataset generation. Additionally, Dynamic-KGQA produces compact, semantically coherent subgraphs that facilitate both training and evaluation of KGQA models, enhancing their ability to leverage structured knowledge effectively. To align with existing evaluation protocols, we also provide static large-scale train/test/validation splits, ensuring comparability with prior methods. By introducing a dynamic, customizable benchmarking paradigm, Dynamic-KGQA enables a more rigorous and adaptable evaluation of QA systems.