 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic-KGQA: A Scalable Framework for Generating Adaptive Question Answering Datasets
Paper and Code
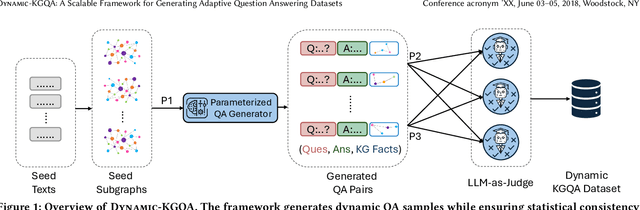
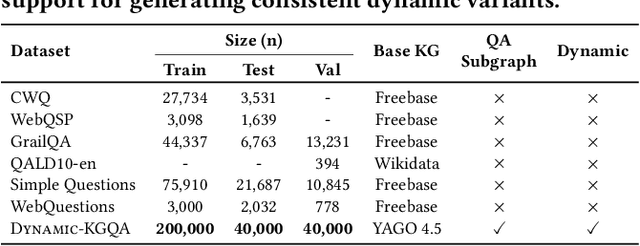
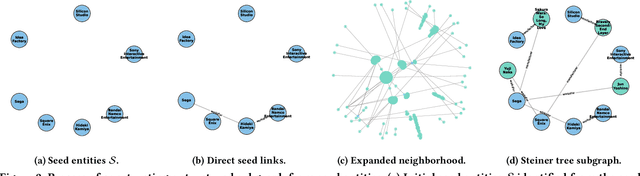

As question answering (QA) systems advance alongside the rapid evolution of foundation models, the need for robust, adaptable, and large-scale evaluation benchmarks becomes increasingly critical. Traditional QA benchmarks are often static and publicly available, making them susceptible to data contamination and memorization by large language models (LLMs). Consequently, static benchmarks may overestimate model generalization and hinder a reliable assessment of real-world performance. In this work, we introduce Dynamic-KGQA, a scalable framework for generating adaptive QA datasets from knowledge graphs (KGs), designed to mitigate memorization risks while maintaining statistical consistency across iterations. Unlike fixed benchmarks, Dynamic-KGQA generates a new dataset variant on every run while preserving the underlying distribution, enabling fair and reproducible evaluations. Furthermore, our framework provides fine-grained control over dataset characteristics, supporting domain-specific and topic-focused QA dataset generation. Additionally, Dynamic-KGQA produces compact, semantically coherent subgraphs that facilitate both training and evaluation of KGQA models, enhancing their ability to leverage structured knowledge effectively. To align with existing evaluation protocols, we also provide static large-scale train/test/validation splits, ensuring comparability with prior methods. By introducing a dynamic, customizable benchmarking paradigm, Dynamic-KGQA enables a more rigorous and adaptable evaluation of QA systems.