 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiOSPointMapper: RealTime Pedestrian and Accessibility Mapping with Mobile AI
Dec 26, 2025Accurate, up-to-date sidewalk data is essential for building accessible and inclusive pedestrian infrastructure, yet current approaches to data collection are often costly, fragmented, and difficult to scale. We introduce iOSPointMapper, a mobile application that enables real-time, privacy-conscious sidewalk mapping on the ground, using recent-generation iPhones and iPads. The system leverages on-device semantic segmentation, LiDAR-based depth estimation, and fused GPS/IMU data to detect and localize sidewalk-relevant features such as traffic signs, traffic lights and poles. To ensure transparency and improve data quality, iOSPointMapper incorporates a user-guided annotation interface for validating system outputs before submission. Collected data is anonymized and transmitted to the Transportation Data Exchange Initiative (TDEI), where it integrates seamlessly with broader multimodal transportation datasets. Detailed evaluations of the system's feature detection and spatial mapping performance reveal the application's potential for enhanced pedestrian mapping. Together, these capabilities offer a scalable and user-centered approach to closing critical data gaps in pedestrian
Dynamic-KGQA: A Scalable Framework for Generating Adaptive Question Answering Datasets
Mar 06, 2025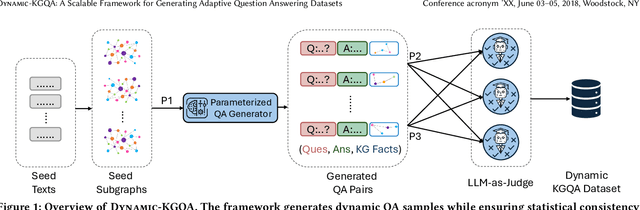
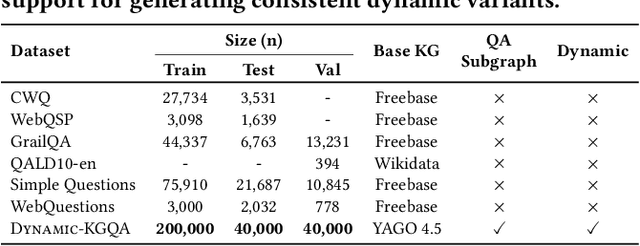
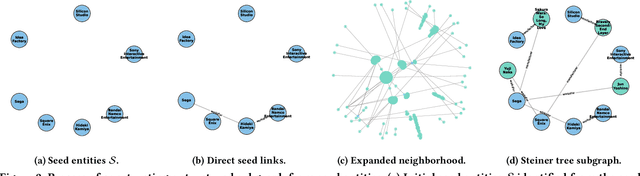

As question answering (QA) systems advance alongside the rapid evolution of foundation models, the need for robust, adaptable, and large-scale evaluation benchmarks becomes increasingly critical. Traditional QA benchmarks are often static and publicly available, making them susceptible to data contamination and memorization by large language models (LLMs). Consequently, static benchmarks may overestimate model generalization and hinder a reliable assessment of real-world performance. In this work, we introduce Dynamic-KGQA, a scalable framework for generating adaptive QA datasets from knowledge graphs (KGs), designed to mitigate memorization risks while maintaining statistical consistency across iterations. Unlike fixed benchmarks, Dynamic-KGQA generates a new dataset variant on every run while preserving the underlying distribution, enabling fair and reproducible evaluations. Furthermore, our framework provides fine-grained control over dataset characteristics, supporting domain-specific and topic-focused QA dataset generation. Additionally, Dynamic-KGQA produces compact, semantically coherent subgraphs that facilitate both training and evaluation of KGQA models, enhancing their ability to leverage structured knowledge effectively. To align with existing evaluation protocols, we also provide static large-scale train/test/validation splits, ensuring comparability with prior methods. By introducing a dynamic, customizable benchmarking paradigm, Dynamic-KGQA enables a more rigorous and adaptable evaluation of QA systems.
ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs
Mar 12, 2024In the midst of widespread misinformation and disinformation through social media and the proliferation of AI-generated texts, it has become increasingly difficult for people to validate and trust information they encounter. Many fact-checking approaches and tools have been developed, but they often lack appropriate explainability or granularity to be useful in various contexts. A text validation method that is easy to use, accessible, and can perform fine-grained evidence attribution has become crucial. More importantly, building user trust in such a method requires presenting the rationale behind each prediction, as research shows this significantly influences people's belief in automated systems. It is also paramount to localize and bring users' attention to the specific problematic content, instead of providing simple blanket labels. In this paper, we present $\textit{ClaimVer, a human-centric framework}$ tailored to meet users' informational and verification needs by generating rich annotations and thereby reducing cognitive load. Designed to deliver comprehensive evaluations of texts, it highlights each claim, verifies it against a trusted knowledge graph (KG), presents the evidence, and provides succinct, clear explanations for each claim prediction. Finally, our framework introduces an attribution score, enhancing applicability across a wide range of downstream tasks.