 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiAgentBench: Benchmarking Sensemaking Capabilities of Information-Seeking Agents on High-Traffic Topics
Mar 04, 2026With the emergence of search-enabled generative QA systems, users are increasingly turning to tools that browse, aggregate, and reconcile evidence across multiple sources on their behalf. Yet many widely used QA benchmarks remain answerable by retrieving a single relevant passage, making them poorly suited for measuring cross-source sensemaking, such as integrating evidence, tracking causal links, and resolving dependencies across facets of a topic. We present iAgentBench, a dynamic ODQA benchmark that targets these higher-level information needs while keeping questions natural and grounded in realistic information-seeking behavior. iAgentBench draws seed topics from real-world attention signals and uses common user intent patterns to construct user-like questions whose answers require combining evidence from multiple sources, not just extracting a single snippet. Each instance is released with traceable evidence and auditable intermediate artifacts that support contamination checks and enable fine-grained diagnosis of failures in retrieval versus synthesis. Experiments across multiple LLMs show that retrieval improves accuracy, but retrieval alone does not reliably resolve these questions, underscoring the need to evaluate evidence use, not just evidence access.
I Think, Therefore I Am Under-Qualified? A Benchmark for Evaluating Linguistic Shibboleth Detection in LLM Hiring Evaluations
Aug 06, 2025This paper introduces a comprehensive benchmark for evaluating how Large Language Models (LLMs) respond to linguistic shibboleths: subtle linguistic markers that can inadvertently reveal demographic attributes such as gender, social class, or regional background. Through carefully constructed interview simulations using 100 validated question-response pairs, we demonstrate how LLMs systematically penalize certain linguistic patterns, particularly hedging language, despite equivalent content quality. Our benchmark generates controlled linguistic variations that isolate specific phenomena while maintaining semantic equivalence, which enables the precise measurement of demographic bias in automated evaluation systems. We validate our approach along multiple linguistic dimensions, showing that hedged responses receive 25.6% lower ratings on average, and demonstrate the benchmark's effectiveness in identifying model-specific biases. This work establishes a foundational framework for detecting and measuring linguistic discrimination in AI systems, with broad applications to fairness in automated decision-making contexts.
RealWebAssist: A Benchmark for Long-Horizon Web Assistance with Real-World Users
Apr 14, 2025To achieve successful assistance with long-horizon web-based tasks, AI agents must be able to sequentially follow real-world user instructions over a long period. Unlike existing web-based agent benchmarks, sequential instruction following in the real world poses significant challenges beyond performing a single, clearly defined task. For instance, real-world human instructions can be ambiguous, require different levels of AI assistance, and may evolve over time, reflecting changes in the user's mental state. To address this gap, we introduce RealWebAssist, a novel benchmark designed to evaluate sequential instruction-following in realistic scenarios involving long-horizon interactions with the web, visual GUI grounding, and understanding ambiguous real-world user instructions. RealWebAssist includes a dataset of sequential instructions collected from real-world human users. Each user instructs a web-based assistant to perform a series of tasks on multiple websites. A successful agent must reason about the true intent behind each instruction, keep track of the mental state of the user, understand user-specific routines, and ground the intended tasks to actions on the correct GUI elements. Our experimental results show that state-of-the-art models struggle to understand and ground user instructions, posing critical challenges in following real-world user instructions for long-horizon web assistance.
Federated Multimodal Learning with Dual Adapters and Selective Pruning for Communication and Computational Efficiency
Mar 10, 2025Federated Learning (FL) enables collaborative learning across distributed clients while preserving data privacy. However, FL faces significant challenges when dealing with heterogeneous data distributions, which can lead to suboptimal global models that fail to generalize across diverse clients. In this work, we propose a novel framework designed to tackle these challenges by introducing a dual-adapter approach. The method utilizes a larger local adapter for client-specific personalization and a smaller global adapter to facilitate efficient knowledge sharing across clients. Additionally, we incorporate a pruning mechanism to reduce communication overhead by selectively removing less impactful parameters from the local adapter. Through extensive experiments on a range of vision and language tasks, our method demonstrates superior performance compared to existing approaches. It achieves higher test accuracy, lower performance variance among clients, and improved worst-case performance, all while significantly reducing communication and computation costs. Overall, the proposed method addresses the critical trade-off between model personalization and generalization, offering a scalable solution for real-world FL applications.
The Order Effect: Investigating Prompt Sensitivity in Closed-Source LLMs
Feb 06, 2025



As large language models (LLMs) become integral to diverse applications, ensuring their reliability under varying input conditions is crucial. One key issue affecting this reliability is order sensitivity, wherein slight variations in input arrangement can lead to inconsistent or biased outputs. Although recent advances have reduced this sensitivity, the problem remains unresolved. This paper investigates the extent of order sensitivity in closed-source LLMs by conducting experiments across multiple tasks, including paraphrasing, relevance judgment, and multiple-choice questions. Our results show that input order significantly affects performance across tasks, with shuffled inputs leading to measurable declines in output accuracy. Few-shot prompting demonstrates mixed effectiveness and offers partial mitigation, however, fails to fully resolve the problem. These findings highlight persistent risks, particularly in high-stakes applications, and point to the need for more robust LLMs or improved input-handling techniques in future development.
How Well Do LLMs Represent Values Across Cultures? Empirical Analysis of LLM Responses Based on Hofstede Cultural Dimensions
Jun 21, 2024



Large Language Models (LLMs) attempt to imitate human behavior by responding to humans in a way that pleases them, including by adhering to their values. However, humans come from diverse cultures with different values. It is critical to understand whether LLMs showcase different values to the user based on the stereotypical values of a user's known country. We prompt different LLMs with a series of advice requests based on 5 Hofstede Cultural Dimensions -- a quantifiable way of representing the values of a country. Throughout each prompt, we incorporate personas representing 36 different countries and, separately, languages predominantly tied to each country to analyze the consistency in the LLMs' cultural understanding. Through our analysis of the responses, we found that LLMs can differentiate between one side of a value and another, as well as understand that countries have differing values, but will not always uphold the values when giving advice, and fail to understand the need to answer differently based on different cultural values. Rooted in these findings, we present recommendations for training value-aligned and culturally sensitive LLMs. More importantly, the methodology and the framework developed here can help further understand and mitigate culture and language alignment issues with LLMs.
ClaimVer: Explainable Claim-Level Verification and Evidence Attribution of Text Through Knowledge Graphs
Mar 12, 2024In the midst of widespread misinformation and disinformation through social media and the proliferation of AI-generated texts, it has become increasingly difficult for people to validate and trust information they encounter. Many fact-checking approaches and tools have been developed, but they often lack appropriate explainability or granularity to be useful in various contexts. A text validation method that is easy to use, accessible, and can perform fine-grained evidence attribution has become crucial. More importantly, building user trust in such a method requires presenting the rationale behind each prediction, as research shows this significantly influences people's belief in automated systems. It is also paramount to localize and bring users' attention to the specific problematic content, instead of providing simple blanket labels. In this paper, we present $\textit{ClaimVer, a human-centric framework}$ tailored to meet users' informational and verification needs by generating rich annotations and thereby reducing cognitive load. Designed to deliver comprehensive evaluations of texts, it highlights each claim, verifies it against a trusted knowledge graph (KG), presents the evidence, and provides succinct, clear explanations for each claim prediction. Finally, our framework introduces an attribution score, enhancing applicability across a wide range of downstream tasks.
Developing a Framework for Auditing Large Language Models Using Human-in-the-Loop
Feb 16, 2024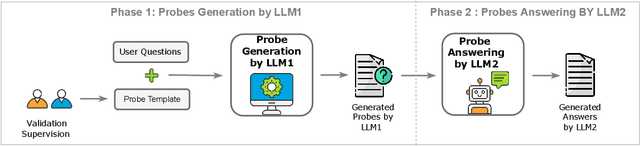


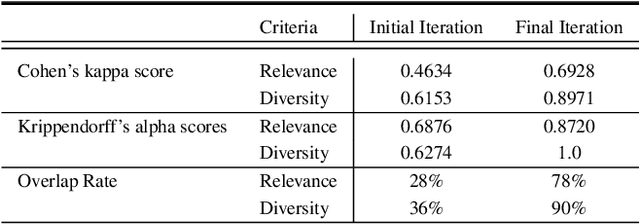
As LLMs become more pervasive across various users and scenarios, identifying potential issues when using these models becomes essential. Examples include bias, inconsistencies, and hallucination. Although auditing the LLM for these problems is desirable, it is far from being easy or solved. An effective method is to probe the LLM using different versions of the same question. This could expose inconsistencies in its knowledge or operation, indicating potential for bias or hallucination. However, to operationalize this auditing method at scale, we need an approach to create those probes reliably and automatically. In this paper we propose an automatic and scalable solution, where one uses a different LLM along with human-in-the-loop. This approach offers verifiability and transparency, while avoiding circular reliance on the same LLMs, and increasing scientific rigor and generalizability. Specifically, we present a novel methodology with two phases of verification using humans: standardized evaluation criteria to verify responses, and a structured prompt template to generate desired probes. Experiments on a set of questions from TruthfulQA dataset show that we can generate a reliable set of probes from one LLM that can be used to audit inconsistencies in a different LLM. The criteria for generating and applying auditing probes is generalizable to various LLMs regardless of the underlying structure or training mechanism.
AuditLLM: A Tool for Auditing Large Language Models Using Multiprobe Approach
Feb 14, 2024As Large Language Models (LLMs) gain wider adoption in various contexts, it becomes crucial to ensure they are reasonably safe, consistent, and reliable for an application at hand. This may require probing or auditing them. Probing LLMs with varied iterations of a single question could reveal potential inconsistencies in their knowledge or functionality. However, a tool for performing such audits with simple workflow and low technical threshold is lacking. In this demo, we introduce "AuditLLM," a novel tool designed to evaluate the performance of various LLMs in a methodical way. AuditLLM's core functionality lies in its ability to test a given LLM by auditing it using multiple probes generated from a single question, thereby identifying any inconsistencies in the model's understanding or operation. A reasonably robust, reliable, and consistent LLM should output semantically similar responses for a question asked differently or by different people. Based on this assumption, AuditLLM produces easily interpretable results regarding the LLM's consistencies from a single question that the user enters. A certain level of inconsistency has been shown to be an indicator of potential bias, hallucinations, and other issues. One could then use the output of AuditLLM to further investigate issues with the aforementioned LLM. To facilitate demonstration and practical uses, AuditLLM offers two key modes: (1) Live mode which allows instant auditing of LLMs by analyzing responses to real-time queries; (2) Batch mode which facilitates comprehensive LLM auditing by processing multiple queries at once for in-depth analysis. This tool is beneficial for both researchers and general users, as it enhances our understanding of LLMs' capabilities in generating responses, using a standardized auditing platform.
What is Lost in Knowledge Distillation?
Nov 07, 2023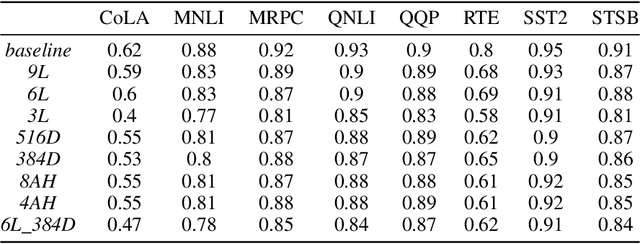

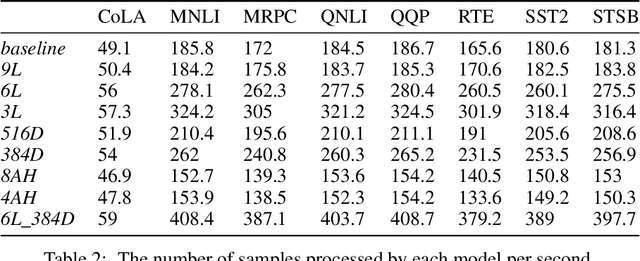

Deep neural networks (DNNs) have improved NLP tasks significantly, but training and maintaining such networks could be costly. Model compression techniques, such as, knowledge distillation (KD), have been proposed to address the issue; however, the compression process could be lossy. Motivated by this, our work investigates how a distilled student model differs from its teacher, if the distillation process causes any information losses, and if the loss follows a specific pattern. Our experiments aim to shed light on the type of tasks might be less or more sensitive to KD by reporting data points on the contribution of different factors, such as the number of layers or attention heads. Results such as ours could be utilized when determining effective and efficient configurations to achieve optimal information transfers between larger (teacher) and smaller (student) models.