 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining LLMs with Reinforcement Learning for Intent-Aware Personalized Question Answering
May 12, 2026Effective personalized question answering (PQA) in language models requires grounding responses in the user's underlying intent, where intent refers to the implicit ``why'' behind a query beyond its explicit wording. However, existing approaches to intent-aware personalization rely on multi-turn conversational context or rich user profiles, and do not explicitly model user intent during the reasoning process. This limits their effectiveness in single-turn settings, where the user's latent goal must be inferred from minimal input and integrated into the thinking and reasoning process. To bridge this gap, we propose IAP (Intent-Aware Personalization), a reinforcement learning framework that trains models to infer implicit user intent directly from a single-turn question and incorporate it into thinking steps through a tag-based schema for generating personalized, intent-grounded answers. By optimizing intent-aware answer trajectories under a personalized reward function, IAP reinforces generation paths that make implicit user intent explicit and produce responses that better align with the user's underlying goal. Through experiments on the LaMP-QA benchmark across six models, IAP consistently outperforms all baselines, achieving an average macro-score gain of around 7.5\% over the strongest competitor, demonstrating that modeling implicit user intent within the training objective is a promising direction for PQA.
Learning to Reason for Multi-Step Retrieval of Personal Context in Personalized Question Answering
Feb 22, 2026Personalization in Question Answering (QA) requires answers that are both accurate and aligned with users' background, preferences, and historical context. Existing state-of-the-art methods primarily rely on retrieval-augmented generation (RAG) solutions that construct personal context by retrieving relevant items from the user's profile. Existing methods use the user's query directly to retrieve personal documents, and such strategies often lead to surface-level personalization. We propose PR2 (Personalized Retrieval-Augmented Reasoning), a reinforcement learning framework that integrates reasoning and retrieval from personal context for personalization. PR2 learns adaptive retrieval-reasoning policies, determining when to retrieve, what evidence to retrieve from user profiles, and how to incorporate it into intermediate reasoning steps. By optimizing multi-turn reasoning trajectories under a personalized reward function, the framework reinforces reasoning paths that better align with user-specific preferences and contextual signals reflected by the reward model. Extensive experiments on the LaMP-QA benchmark using three LLMs show that PR2 consistently outperforms strong baselines, achieving an average relative improvement of 8.8%-12% in personalized QA.
Do LLMs Exhibit Human-Like Reasoning? Evaluating Theory of Mind in LLMs for Open-Ended Responses
Jun 09, 2024



Theory of Mind (ToM) reasoning entails recognizing that other individuals possess their own intentions, emotions, and thoughts, which is vital for guiding one's own thought processes. Although large language models (LLMs) excel in tasks such as summarization, question answering, and translation, they still face challenges with ToM reasoning, especially in open-ended questions. Despite advancements, the extent to which LLMs truly understand ToM reasoning and how closely it aligns with human ToM reasoning remains inadequately explored in open-ended scenarios. Motivated by this gap, we assess the abilities of LLMs to perceive and integrate human intentions and emotions into their ToM reasoning processes within open-ended questions. Our study utilizes posts from Reddit's ChangeMyView platform, which demands nuanced social reasoning to craft persuasive responses. Our analysis, comparing semantic similarity and lexical overlap metrics between responses generated by humans and LLMs, reveals clear disparities in ToM reasoning capabilities in open-ended questions, with even the most advanced models showing notable limitations. To enhance LLM capabilities, we implement a prompt tuning method that incorporates human intentions and emotions, resulting in improvements in ToM reasoning performance. However, despite these improvements, the enhancement still falls short of fully achieving human-like reasoning. This research highlights the deficiencies in LLMs' social reasoning and demonstrates how integrating human intentions and emotions can boost their effectiveness.
Developing a Framework for Auditing Large Language Models Using Human-in-the-Loop
Feb 16, 2024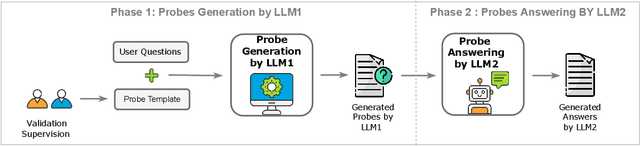


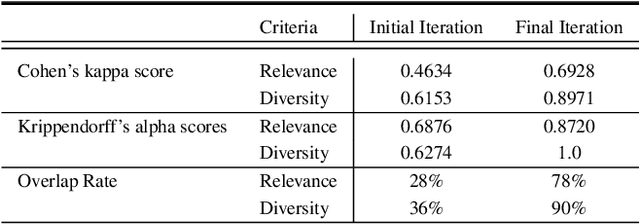
As LLMs become more pervasive across various users and scenarios, identifying potential issues when using these models becomes essential. Examples include bias, inconsistencies, and hallucination. Although auditing the LLM for these problems is desirable, it is far from being easy or solved. An effective method is to probe the LLM using different versions of the same question. This could expose inconsistencies in its knowledge or operation, indicating potential for bias or hallucination. However, to operationalize this auditing method at scale, we need an approach to create those probes reliably and automatically. In this paper we propose an automatic and scalable solution, where one uses a different LLM along with human-in-the-loop. This approach offers verifiability and transparency, while avoiding circular reliance on the same LLMs, and increasing scientific rigor and generalizability. Specifically, we present a novel methodology with two phases of verification using humans: standardized evaluation criteria to verify responses, and a structured prompt template to generate desired probes. Experiments on a set of questions from TruthfulQA dataset show that we can generate a reliable set of probes from one LLM that can be used to audit inconsistencies in a different LLM. The criteria for generating and applying auditing probes is generalizable to various LLMs regardless of the underlying structure or training mechanism.
AuditLLM: A Tool for Auditing Large Language Models Using Multiprobe Approach
Feb 14, 2024As Large Language Models (LLMs) gain wider adoption in various contexts, it becomes crucial to ensure they are reasonably safe, consistent, and reliable for an application at hand. This may require probing or auditing them. Probing LLMs with varied iterations of a single question could reveal potential inconsistencies in their knowledge or functionality. However, a tool for performing such audits with simple workflow and low technical threshold is lacking. In this demo, we introduce "AuditLLM," a novel tool designed to evaluate the performance of various LLMs in a methodical way. AuditLLM's core functionality lies in its ability to test a given LLM by auditing it using multiple probes generated from a single question, thereby identifying any inconsistencies in the model's understanding or operation. A reasonably robust, reliable, and consistent LLM should output semantically similar responses for a question asked differently or by different people. Based on this assumption, AuditLLM produces easily interpretable results regarding the LLM's consistencies from a single question that the user enters. A certain level of inconsistency has been shown to be an indicator of potential bias, hallucinations, and other issues. One could then use the output of AuditLLM to further investigate issues with the aforementioned LLM. To facilitate demonstration and practical uses, AuditLLM offers two key modes: (1) Live mode which allows instant auditing of LLMs by analyzing responses to real-time queries; (2) Batch mode which facilitates comprehensive LLM auditing by processing multiple queries at once for in-depth analysis. This tool is beneficial for both researchers and general users, as it enhances our understanding of LLMs' capabilities in generating responses, using a standardized auditing platform.