 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxiTwitch: Toward Emote-Aware Hybrid Moderation for Live Streaming Platforms
Jan 22, 2026The rapid growth of live-streaming platforms such as Twitch has introduced complex challenges in moderating toxic behavior. Traditional moderation approaches, such as human annotation and keyword-based filtering, have demonstrated utility, but human moderators on Twitch constantly struggle to scale effectively in the fast-paced, high-volume, and context-rich chat environment of the platform while also facing harassment themselves. Recent advances in large language models (LLMs), such as DeepSeek-R1-Distill and Llama-3-8B-Instruct, offer new opportunities for toxicity detection, especially in understanding nuanced, multimodal communication involving emotes. In this work, we present an exploratory comparison of toxicity detection approaches tailored to Twitch. Our analysis reveals that incorporating emotes improves the detection of toxic behavior. To this end, we introduce ToxiTwitch, a hybrid model that combines LLM-generated embeddings of text and emotes with traditional machine learning classifiers, including Random Forest and SVM. In our case study, the proposed hybrid approach reaches up to 80 percent accuracy under channel-specific training (with 13 percent improvement over BERT and F1-score of 76 percent). This work is an exploratory study intended to surface challenges and limits of emote-aware toxicity detection on Twitch.
Comparing Fairness of Generative Mobility Models
Nov 07, 2024This work examines the fairness of generative mobility models, addressing the often overlooked dimension of equity in model performance across geographic regions. Predictive models built on crowd flow data are instrumental in understanding urban structures and movement patterns; however, they risk embedding biases, particularly in spatiotemporal contexts where model performance may reflect and reinforce existing inequities tied to geographic distribution. We propose a novel framework for assessing fairness by measuring the utility and equity of generated traces. Utility is assessed via the Common Part of Commuters (CPC), a similarity metric comparing generated and real mobility flows, while fairness is evaluated using demographic parity. By reformulating demographic parity to reflect the difference in CPC distribution between two groups, our analysis reveals disparities in how various models encode biases present in the underlying data. We utilized four models (Gravity, Radiation, Deep Gravity, and Non-linear Gravity) and our results indicate that traditional gravity and radiation models produce fairer outcomes, although Deep Gravity achieves higher CPC. This disparity underscores a trade-off between model accuracy and equity, with the feature-rich Deep Gravity model amplifying pre-existing biases in community representations. Our findings emphasize the importance of integrating fairness metrics in mobility modeling to avoid perpetuating inequities.
Do LLMs Exhibit Human-Like Reasoning? Evaluating Theory of Mind in LLMs for Open-Ended Responses
Jun 09, 2024



Theory of Mind (ToM) reasoning entails recognizing that other individuals possess their own intentions, emotions, and thoughts, which is vital for guiding one's own thought processes. Although large language models (LLMs) excel in tasks such as summarization, question answering, and translation, they still face challenges with ToM reasoning, especially in open-ended questions. Despite advancements, the extent to which LLMs truly understand ToM reasoning and how closely it aligns with human ToM reasoning remains inadequately explored in open-ended scenarios. Motivated by this gap, we assess the abilities of LLMs to perceive and integrate human intentions and emotions into their ToM reasoning processes within open-ended questions. Our study utilizes posts from Reddit's ChangeMyView platform, which demands nuanced social reasoning to craft persuasive responses. Our analysis, comparing semantic similarity and lexical overlap metrics between responses generated by humans and LLMs, reveals clear disparities in ToM reasoning capabilities in open-ended questions, with even the most advanced models showing notable limitations. To enhance LLM capabilities, we implement a prompt tuning method that incorporates human intentions and emotions, resulting in improvements in ToM reasoning performance. However, despite these improvements, the enhancement still falls short of fully achieving human-like reasoning. This research highlights the deficiencies in LLMs' social reasoning and demonstrates how integrating human intentions and emotions can boost their effectiveness.
Phoenix: A Federated Generative Diffusion Model
Jun 07, 2023



Generative AI has made impressive strides in enabling users to create diverse and realistic visual content such as images, videos, and audio. However, training generative models on large centralized datasets can pose challenges in terms of data privacy, security, and accessibility. Federated learning (FL) is an approach that uses decentralized techniques to collaboratively train a shared deep learning model while retaining the training data on individual edge devices to preserve data privacy. This paper proposes a novel method for training a Denoising Diffusion Probabilistic Model (DDPM) across multiple data sources using FL techniques. Diffusion models, a newly emerging generative model, show promising results in achieving superior quality images than Generative Adversarial Networks (GANs). Our proposed method Phoenix is an unconditional diffusion model that leverages strategies to improve the data diversity of generated samples even when trained on data with statistical heterogeneity or Non-IID (Non-Independent and Identically Distributed) data. We demonstrate how our approach outperforms the default diffusion model in an FL setting. These results indicate that high-quality samples can be generated by maintaining data diversity, preserving privacy, and reducing communication between data sources, offering exciting new possibilities in the field of generative AI.
Survey of Federated Learning Models for Spatial-Temporal Mobility Applications
May 10, 2023Federated learning involves training statistical models over edge devices such as mobile phones such that the training data is kept local. Federated Learning (FL) can serve as an ideal candidate for training spatial temporal models that rely on heterogeneous and potentially massive numbers of participants while preserving the privacy of highly sensitive location data. However, there are unique challenges involved with transitioning existing spatial temporal models to decentralized learning. In this survey paper, we review the existing literature that has proposed FL-based models for predicting human mobility, traffic prediction, community detection, location-based recommendation systems, and other spatial-temporal tasks. We describe the metrics and datasets these works have been using and create a baseline of these approaches in comparison to the centralized settings. Finally, we discuss the challenges of applying spatial-temporal models in a decentralized setting and by highlighting the gaps in the literature we provide a road map and opportunities for the research community.
Analysing Fairness of Privacy-Utility Mobility Models
Apr 10, 2023



Preserving the individuals' privacy in sharing spatial-temporal datasets is critical to prevent re-identification attacks based on unique trajectories. Existing privacy techniques tend to propose ideal privacy-utility tradeoffs, however, largely ignore the fairness implications of mobility models and whether such techniques perform equally for different groups of users. The quantification between fairness and privacy-aware models is still unclear and there barely exists any defined sets of metrics for measuring fairness in the spatial-temporal context. In this work, we define a set of fairness metrics designed explicitly for human mobility, based on structural similarity and entropy of the trajectories. Under these definitions, we examine the fairness of two state-of-the-art privacy-preserving models that rely on GAN and representation learning to reduce the re-identification rate of users for data sharing. Our results show that while both models guarantee group fairness in terms of demographic parity, they violate individual fairness criteria, indicating that users with highly similar trajectories receive disparate privacy gain. We conclude that the tension between the re-identification task and individual fairness needs to be considered for future spatial-temporal data analysis and modelling to achieve a privacy-preserving fairness-aware setting.
Personalized Emotion Detection using IoT and Machine Learning
Sep 14, 2022
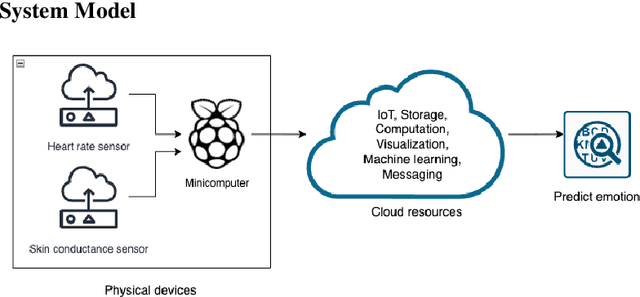


The Medical Internet of Things, a recent technological advancement in medicine, is incredibly helpful in providing real-time monitoring of health metrics. This paper presents a non-invasive IoT system that tracks patients' emotions, especially those with autism spectrum disorder. With a few affordable sensors and cloud computing services, the individual's heart rates are monitored and analyzed to study the effects of changes in sweat and heartbeats per minute for different emotions. Under normal resting conditions of the individual, the proposed system could detect the right emotion using machine learning algorithms with a performance of up to 92% accuracy. The result of the proposed approach is comparable with the state-of-the-art solutions in medical IoT.
Privacy-Aware Adversarial Network in Human Mobility Prediction
Aug 09, 2022
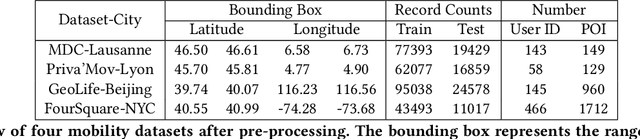

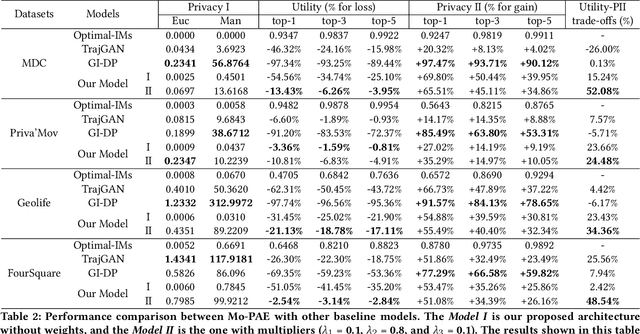
As mobile devices and location-based services are increasingly developed in different smart city scenarios and applications, many unexpected privacy leakages have arisen due to geolocated data collection and sharing. User re-identification and other sensitive inferences are major privacy threats when geolocated data are shared with cloud-assisted applications. Significantly, four spatio-temporal points are enough to uniquely identify 95\% of the individuals, which exacerbates personal information leakages. To tackle malicious purposes such as user re-identification, we propose an LSTM-based adversarial mechanism with representation learning to attain a privacy-preserving feature representation of the original geolocated data (i.e., mobility data) for a sharing purpose. These representations aim to maximally reduce the chance of user re-identification and full data reconstruction with a minimal utility budget (i.e., loss). We train the mechanism by quantifying privacy-utility trade-off of mobility datasets in terms of trajectory reconstruction risk, user re-identification risk, and mobility predictability. We report an exploratory analysis that enables the user to assess this trade-off with a specific loss function and its weight parameters. The extensive comparison results on four representative mobility datasets demonstrate the superiority of our proposed architecture in mobility privacy protection and the efficiency of the proposed privacy-preserving features extractor. We show that the privacy of mobility traces attains decent protection at the cost of marginal mobility utility. Our results also show that by exploring the Pareto optimal setting, we can simultaneously increase both privacy (45%) and utility (32%).
Caring Without Sharing: A Federated Learning Crowdsensing Framework for Diversifying Representation of Cities
Jan 20, 2022Mobile Crowdsensing has become main stream paradigm for researchers to collect behavioral data from citizens in large scales. This valuable data can be leveraged to create centralized repositories that can be used to train advanced Artificial Intelligent (AI) models for various services that benefit society in all aspects. Although decades of research has explored the viability of Mobile Crowdsensing in terms of incentives and many attempts have been made to reduce the participation barriers, the overshadowing privacy concerns regarding sharing personal data still remain. Recently a new pathway has emerged to enable to shift MCS paradigm towards a more privacy-preserving collaborative learning, namely Federated Learning. In this paper, we posit a first of its kind framework for this emerging paradigm. We demonstrate the functionalities of our framework through a case study of diversifying two vision algorithms through to learn the representation of ordinary sidewalk obstacles as part of enhancing visually impaired navigation.
Fairness in Federated Learning for Spatial-Temporal Applications
Jan 20, 2022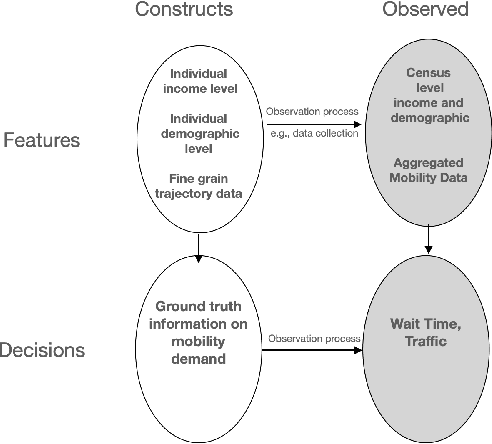

Federated learning involves training statistical models over remote devices such as mobile phones while keeping data localized. Training in heterogeneous and potentially massive networks introduces opportunities for privacy-preserving data analysis and diversifying these models to become more inclusive of the population. Federated learning can be viewed as a unique opportunity to bring fairness and parity to many existing models by enabling model training to happen on a diverse set of participants and on data that is generated regularly and dynamically. In this paper, we discuss the current metrics and approaches that are available to measure and evaluate fairness in the context of spatial-temporal models. We propose how these metrics and approaches can be re-defined to address the challenges that are faced in the federated learning setting.