 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRANITE : a Byzantine-Resilient Dynamic Gossip Learning Framework
Apr 24, 2025Gossip Learning (GL) is a decentralized learning paradigm where users iteratively exchange and aggregate models with a small set of neighboring peers. Recent GL approaches rely on dynamic communication graphs built and maintained using Random Peer Sampling (RPS) protocols. Thanks to graph dynamics, GL can achieve fast convergence even over extremely sparse topologies. However, the robustness of GL over dy- namic graphs to Byzantine (model poisoning) attacks remains unaddressed especially when Byzantine nodes attack the RPS protocol to scale up model poisoning. We address this issue by introducing GRANITE, a framework for robust learning over sparse, dynamic graphs in the presence of a fraction of Byzantine nodes. GRANITE relies on two key components (i) a History-aware Byzantine-resilient Peer Sampling protocol (HaPS), which tracks previously encountered identifiers to reduce adversarial influence over time, and (ii) an Adaptive Probabilistic Threshold (APT), which leverages an estimate of Byzantine presence to set aggregation thresholds with formal guarantees. Empirical results confirm that GRANITE maintains convergence with up to 30% Byzantine nodes, improves learning speed via adaptive filtering of poisoned models and obtains these results in up to 9 times sparser graphs than dictated by current theory.
Scrutinizing the Vulnerability of Decentralized Learning to Membership Inference Attacks
Dec 17, 2024



The primary promise of decentralized learning is to allow users to engage in the training of machine learning models in a collaborative manner while keeping their data on their premises and without relying on any central entity. However, this paradigm necessitates the exchange of model parameters or gradients between peers. Such exchanges can be exploited to infer sensitive information about training data, which is achieved through privacy attacks (e.g Membership Inference Attacks -- MIA). In order to devise effective defense mechanisms, it is important to understand the factors that increase/reduce the vulnerability of a given decentralized learning architecture to MIA. In this study, we extensively explore the vulnerability to MIA of various decentralized learning architectures by varying the graph structure (e.g number of neighbors), the graph dynamics, and the aggregation strategy, across diverse datasets and data distributions. Our key finding, which to the best of our knowledge we are the first to report, is that the vulnerability to MIA is heavily correlated to (i) the local model mixing strategy performed by each node upon reception of models from neighboring nodes and (ii) the global mixing properties of the communication graph. We illustrate these results experimentally using four datasets and by theoretically analyzing the mixing properties of various decentralized architectures. Our paper draws a set of lessons learned for devising decentralized learning systems that reduce by design the vulnerability to MIA.
Community Detection Attack against Collaborative Learning-based Recommender Systems
Jun 15, 2023



Collaborative-learning based recommender systems emerged following the success of collaborative learning techniques such as Federated Learning (FL) and Gossip Learning (GL). In these systems, users participate in the training of a recommender system while keeping their history of consumed items on their devices. While these solutions seemed appealing for preserving the privacy of the participants at a first glance, recent studies have shown that collaborative learning can be vulnerable to a variety of privacy attacks. In this paper we propose a novel privacy attack called Community Detection Attack (CDA), which allows an adversary to discover the members of a community based on a set of items of her choice (e.g., discovering users interested in LGBT content). Through experiments on three real recommendation datasets and by using two state-of-the-art recommendation models, we assess the sensitivity of an FL-based recommender system as well as two flavors of Gossip Learning-based recommender systems to CDA. Results show that on all models and all datasets, the FL setting is more vulnerable to CDA than Gossip settings. We further evaluated two off-the-shelf mitigation strategies, namely differential privacy (DP) and a share less policy, which consists in sharing a subset of model parameters. Results show a better privacy-utility trade-off for the share less policy compared to DP especially in the Gossip setting.
Survey of Federated Learning Models for Spatial-Temporal Mobility Applications
May 10, 2023Federated learning involves training statistical models over edge devices such as mobile phones such that the training data is kept local. Federated Learning (FL) can serve as an ideal candidate for training spatial temporal models that rely on heterogeneous and potentially massive numbers of participants while preserving the privacy of highly sensitive location data. However, there are unique challenges involved with transitioning existing spatial temporal models to decentralized learning. In this survey paper, we review the existing literature that has proposed FL-based models for predicting human mobility, traffic prediction, community detection, location-based recommendation systems, and other spatial-temporal tasks. We describe the metrics and datasets these works have been using and create a baseline of these approaches in comparison to the centralized settings. Finally, we discuss the challenges of applying spatial-temporal models in a decentralized setting and by highlighting the gaps in the literature we provide a road map and opportunities for the research community.
PEPPER: Empowering User-Centric Recommender Systems over Gossip Learning
Aug 09, 2022


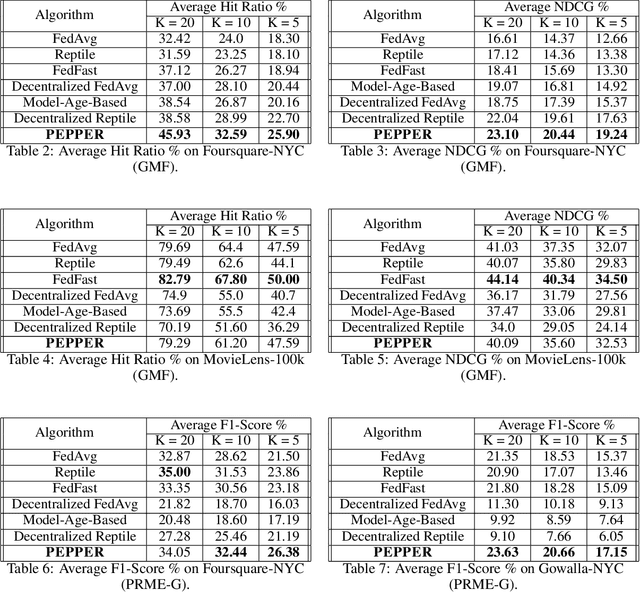
Recommender systems are proving to be an invaluable tool for extracting user-relevant content helping users in their daily activities (e.g., finding relevant places to visit, content to consume, items to purchase). However, to be effective, these systems need to collect and analyze large volumes of personal data (e.g., location check-ins, movie ratings, click rates .. etc.), which exposes users to numerous privacy threats. In this context, recommender systems based on Federated Learning (FL) appear to be a promising solution for enforcing privacy as they compute accurate recommendations while keeping personal data on the users' devices. However, FL, and therefore FL-based recommender systems, rely on a central server that can experience scalability issues besides being vulnerable to attacks. To remedy this, we propose PEPPER, a decentralized recommender system based on gossip learning principles. In PEPPER, users gossip model updates and aggregate them asynchronously. At the heart of PEPPER reside two key components: a personalized peer-sampling protocol that keeps in the neighborhood of each node, a proportion of nodes that have similar interests to the former and a simple yet effective model aggregation function that builds a model that is better suited to each user. Through experiments on three real datasets implementing two use cases: a location check-in recommendation and a movie recommendation, we demonstrate that our solution converges up to 42% faster than with other decentralized solutions providing up to 9% improvement on average performance metric such as hit ratio and up to 21% improvement on long tail performance compared to decentralized competitors.