 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShielding Federated Learning Systems against Inference Attacks with ARM TrustZone
Aug 19, 2022
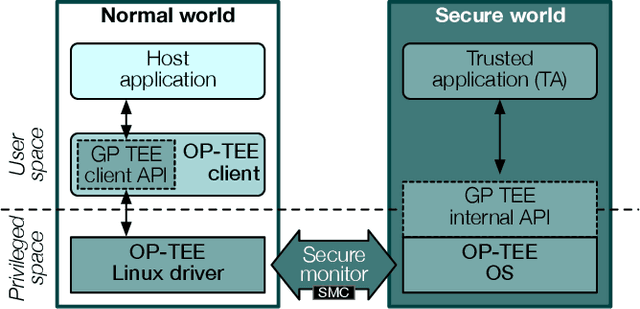
Federated Learning (FL) opens new perspectives for training machine learning models while keeping personal data on the users premises. Specifically, in FL, models are trained on the users devices and only model updates (i.e., gradients) are sent to a central server for aggregation purposes. However, the long list of inference attacks that leak private data from gradients, published in the recent years, have emphasized the need of devising effective protection mechanisms to incentivize the adoption of FL at scale. While there exist solutions to mitigate these attacks on the server side, little has been done to protect users from attacks performed on the client side. In this context, the use of Trusted Execution Environments (TEEs) on the client side are among the most proposing solutions. However, existing frameworks (e.g., DarkneTZ) require statically putting a large portion of the machine learning model into the TEE to effectively protect against complex attacks or a combination of attacks. We present GradSec, a solution that allows protecting in a TEE only sensitive layers of a machine learning model, either statically or dynamically, hence reducing both the TCB size and the overall training time by up to 30% and 56%, respectively compared to state-of-the-art competitors.
PEPPER: Empowering User-Centric Recommender Systems over Gossip Learning
Aug 09, 2022


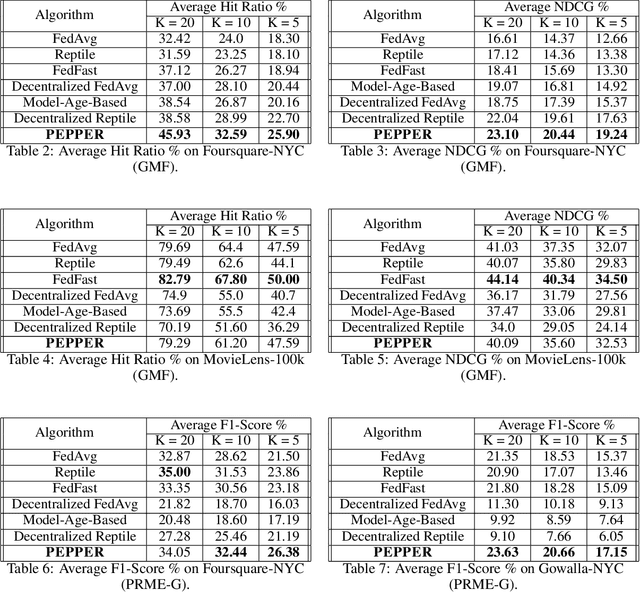
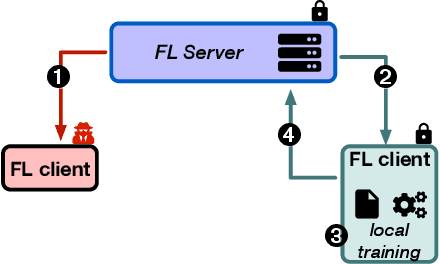
Recommender systems are proving to be an invaluable tool for extracting user-relevant content helping users in their daily activities (e.g., finding relevant places to visit, content to consume, items to purchase). However, to be effective, these systems need to collect and analyze large volumes of personal data (e.g., location check-ins, movie ratings, click rates .. etc.), which exposes users to numerous privacy threats. In this context, recommender systems based on Federated Learning (FL) appear to be a promising solution for enforcing privacy as they compute accurate recommendations while keeping personal data on the users' devices. However, FL, and therefore FL-based recommender systems, rely on a central server that can experience scalability issues besides being vulnerable to attacks. To remedy this, we propose PEPPER, a decentralized recommender system based on gossip learning principles. In PEPPER, users gossip model updates and aggregate them asynchronously. At the heart of PEPPER reside two key components: a personalized peer-sampling protocol that keeps in the neighborhood of each node, a proportion of nodes that have similar interests to the former and a simple yet effective model aggregation function that builds a model that is better suited to each user. Through experiments on three real datasets implementing two use cases: a location check-in recommendation and a movie recommendation, we demonstrate that our solution converges up to 42% faster than with other decentralized solutions providing up to 9% improvement on average performance metric such as hit ratio and up to 21% improvement on long tail performance compared to decentralized competitors.
FLeet: Online Federated Learning via Staleness Awareness and Performance Prediction
Jun 12, 2020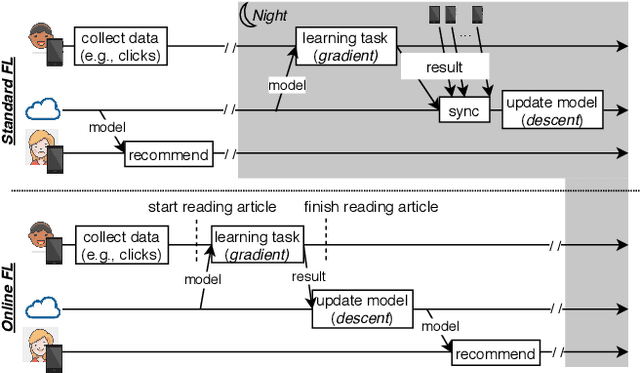
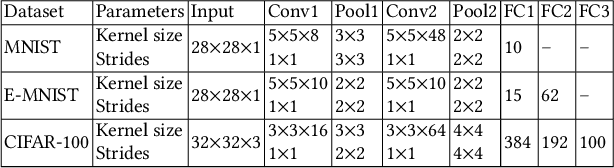
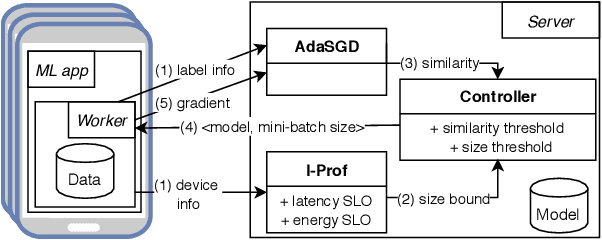
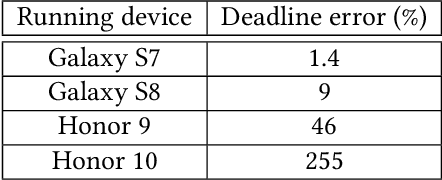
Federated Learning (FL) is very appealing for its privacy benefits: essentially, a global model is trained with updates computed on mobile devices while keeping the data of users local. Standard FL infrastructures are however designed to have no energy or performance impact on mobile devices, and are therefore not suitable for applications that require frequent (online) model updates, such as news recommenders. This paper presents FLeet, the first Online FL system, acting as a middleware between the Android OS and the machine learning application. FLeet combines the privacy of Standard FL with the precision of online learning thanks to two core components: (i) I-Prof, a new lightweight profiler that predicts and controls the impact of learning tasks on mobile devices, and (ii) AdaSGD, a new adaptive learning algorithm that is resilient to delayed updates. Our extensive evaluation shows that Online FL, as implemented by FLeet, can deliver a 2.3x quality boost compared to Standard FL, while only consuming 0.036% of the battery per day. I-Prof can accurately control the impact of learning tasks by improving the prediction accuracy up to 3.6x (computation time) and up to 19x (energy). AdaSGD outperforms alternative FL approaches by 18.4% in terms of convergence speed on heterogeneous data.