 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistill-C: Enhanced NL2SQL via Distilled Customization with LLMs
Mar 30, 2025The growing adoption of large language models (LLMs) in business applications has amplified interest in Natural Language to SQL (NL2SQL) solutions, in which there is competing demand for high performance and efficiency. Domain- and customer-specific requirements further complicate the problem. To address this conundrum, we introduce Distill-C, a distilled customization framework tailored for NL2SQL tasks. Distill-C utilizes large teacher LLMs to produce high-quality synthetic data through a robust and scalable pipeline. Finetuning smaller and open-source LLMs on this synthesized data enables them to rival or outperform teacher models an order of magnitude larger. Evaluated on multiple challenging benchmarks, Distill-C achieves an average improvement of 36% in execution accuracy compared to the base models from three distinct LLM families. Additionally, on three internal customer benchmarks, Distill-C demonstrates a 22.6% performance improvement over the base models. Our results demonstrate that Distill-C is an effective, high-performing and generalizable approach for deploying lightweight yet powerful NL2SQL models, delivering exceptional accuracies while maintaining low computational cost.
FLeet: Online Federated Learning via Staleness Awareness and Performance Prediction
Jun 12, 2020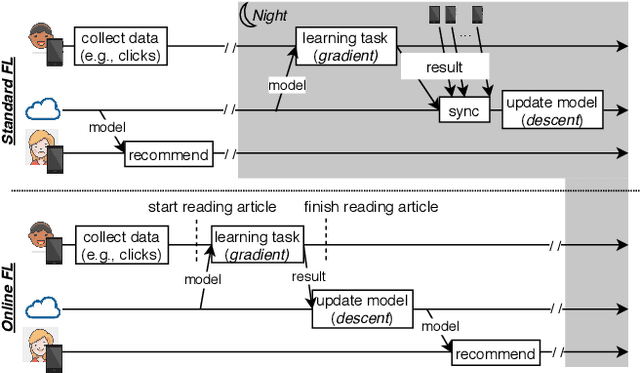
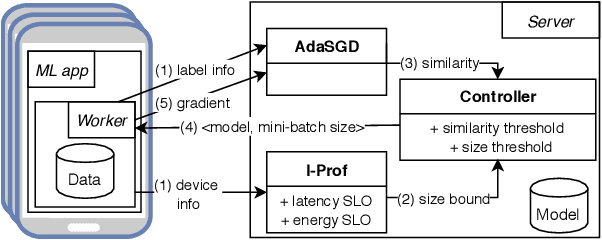
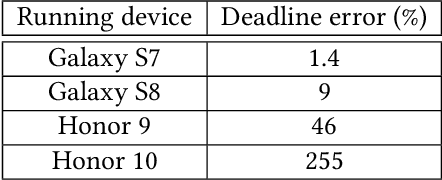
Federated Learning (FL) is very appealing for its privacy benefits: essentially, a global model is trained with updates computed on mobile devices while keeping the data of users local. Standard FL infrastructures are however designed to have no energy or performance impact on mobile devices, and are therefore not suitable for applications that require frequent (online) model updates, such as news recommenders. This paper presents FLeet, the first Online FL system, acting as a middleware between the Android OS and the machine learning application. FLeet combines the privacy of Standard FL with the precision of online learning thanks to two core components: (i) I-Prof, a new lightweight profiler that predicts and controls the impact of learning tasks on mobile devices, and (ii) AdaSGD, a new adaptive learning algorithm that is resilient to delayed updates. Our extensive evaluation shows that Online FL, as implemented by FLeet, can deliver a 2.3x quality boost compared to Standard FL, while only consuming 0.036% of the battery per day. I-Prof can accurately control the impact of learning tasks by improving the prediction accuracy up to 3.6x (computation time) and up to 19x (energy). AdaSGD outperforms alternative FL approaches by 18.4% in terms of convergence speed on heterogeneous data.
Asynchronous Byzantine Machine Learning (the case of SGD)
Jul 09, 2018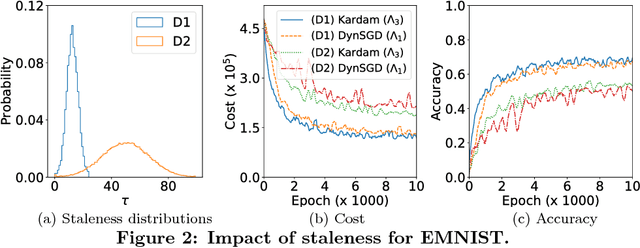
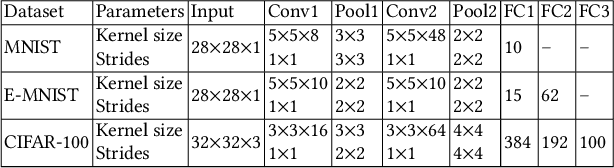
Asynchronous distributed machine learning solutions have proven very effective so far, but always assuming perfectly functioning workers. In practice, some of the workers can however exhibit Byzantine behavior, caused by hardware failures, software bugs, corrupt data, or even malicious attacks. We introduce \emph{Kardam}, the first distributed asynchronous stochastic gradient descent (SGD) algorithm that copes with Byzantine workers. Kardam consists of two complementary components: a filtering and a dampening component. The first is scalar-based and ensures resilience against $\frac{1}{3}$ Byzantine workers. Essentially, this filter leverages the Lipschitzness of cost functions and acts as a self-stabilizer against Byzantine workers that would attempt to corrupt the progress of SGD. The dampening component bounds the convergence rate by adjusting to stale information through a generic gradient weighting scheme. We prove that Kardam guarantees almost sure convergence in the presence of asynchrony and Byzantine behavior, and we derive its convergence rate. We evaluate Kardam on the CIFAR-100 and EMNIST datasets and measure its overhead with respect to non Byzantine-resilient solutions. We empirically show that Kardam does not introduce additional noise to the learning procedure but does induce a slowdown (the cost of Byzantine resilience) that we both theoretically and empirically show to be less than $f/n$, where $f$ is the number of Byzantine failures tolerated and $n$ the total number of workers. Interestingly, we also empirically observe that the dampening component is interesting in its own right for it enables to build an SGD algorithm that outperforms alternative staleness-aware asynchronous competitors in environments with honest workers.
BoostJet: Towards Combining Statistical Aggregates with Neural Embeddings for Recommendations
Dec 07, 2017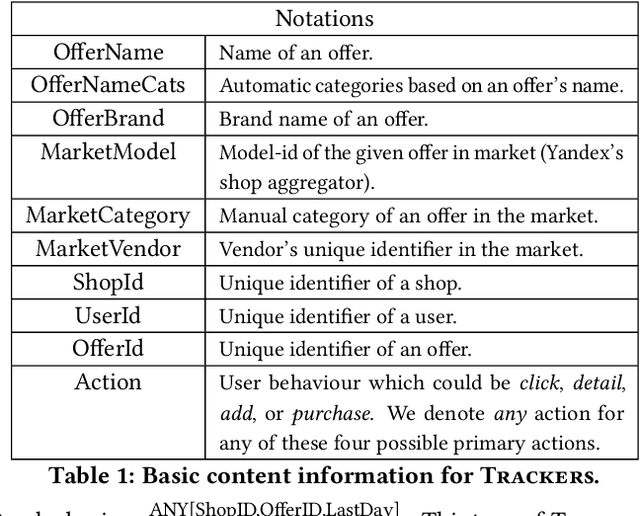
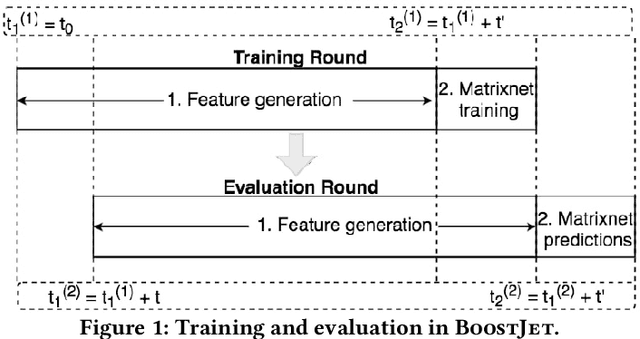

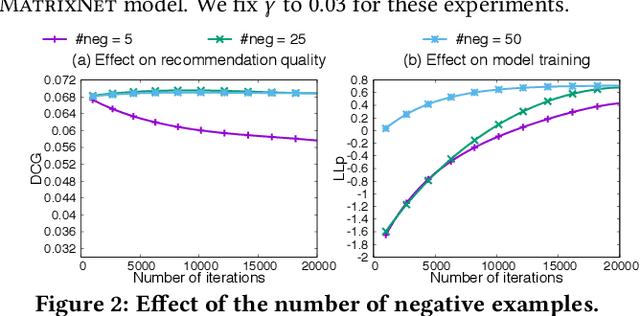
Recommenders have become widely popular in recent years because of their broader applicability in many e-commerce applications. These applications rely on recommenders for generating advertisements for various offers or providing content recommendations. However, the quality of the generated recommendations depends on user features (like demography, temporality), offer features (like popularity, price), and user-offer features (like implicit or explicit feedback). Current state-of-the-art recommenders do not explore such diverse features concurrently while generating the recommendations. In this paper, we first introduce the notion of Trackers which enables us to capture the above-mentioned features and thus incorporate users' online behaviour through statistical aggregates of different features (demography, temporality, popularity, price). We also show how to capture offer-to-offer relations, based on their consumption sequence, leveraging neural embeddings for offers in our Offer2Vec algorithm. We then introduce BoostJet, a novel recommender which integrates the Trackers along with the neural embeddings using MatrixNet, an efficient distributed implementation of gradient boosted decision tree, to improve the recommendation quality significantly. We provide an in-depth evaluation of BoostJet on Yandex's dataset, collecting online behaviour from tens of millions of online users, to demonstrate the practicality of BoostJet in terms of recommendation quality as well as scalability.
Sequences, Items And Latent Links: Recommendation With Consumed Item Packs
Dec 07, 2017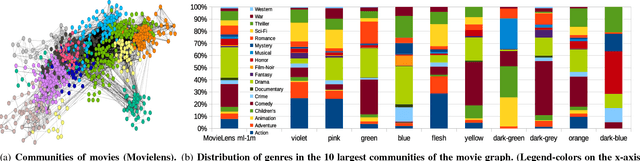
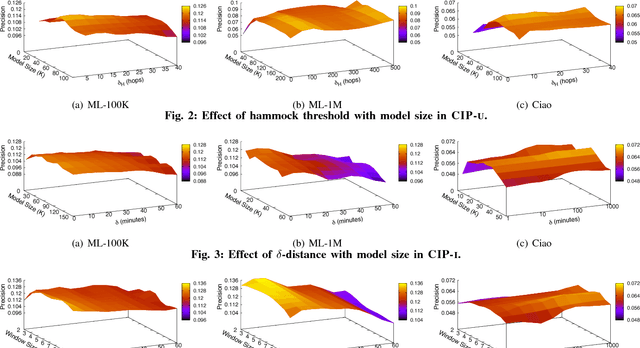
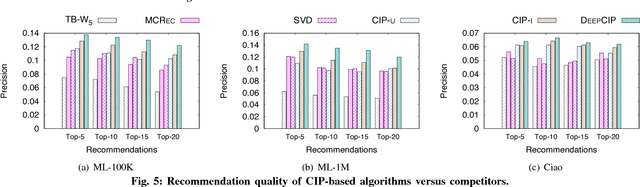
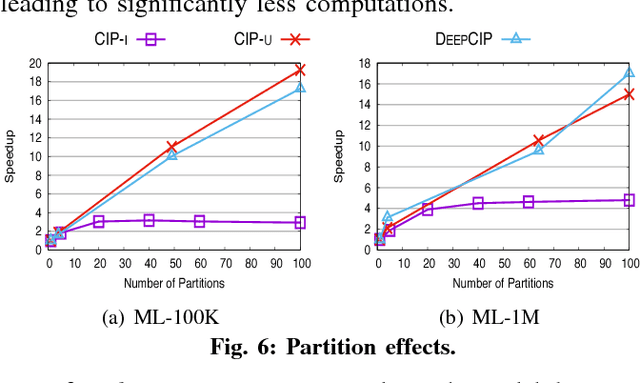
Recommenders personalize the web content by typically using collaborative filtering to relate users (or items) based on explicit feedback, e.g., ratings. The difficulty of collecting this feedback has recently motivated to consider implicit feedback (e.g., item consumption along with the corresponding time). In this paper, we introduce the notion of consumed item pack (CIP) which enables to link users (or items) based on their implicit analogous consumption behavior. Our proposal is generic, and we show that it captures three novel implicit recommenders: a user-based (CIP-U), an item-based (CIP-I), and a word embedding-based (DEEPCIP), as well as a state-of-the-art technique using implicit feedback (FISM). We show that our recommenders handle incremental updates incorporating freshly consumed items. We demonstrate that all three recommenders provide a recommendation quality that is competitive with state-of-the-art ones, including one incorporating both explicit and implicit feedback.