 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedDCR: Learning to Design Agentic Workflows for Medical Coding
Nov 17, 2025Medical coding converts free-text clinical notes into standardized diagnostic and procedural codes, which are essential for billing, hospital operations, and medical research. Unlike ordinary text classification, it requires multi-step reasoning: extracting diagnostic concepts, applying guideline constraints, mapping to hierarchical codebooks, and ensuring cross-document consistency. Recent advances leverage agentic LLMs, but most rely on rigid, manually crafted workflows that fail to capture the nuance and variability of real-world documentation, leaving open the question of how to systematically learn effective workflows. We present MedDCR, a closed-loop framework that treats workflow design as a learning problem. A Designer proposes workflows, a Coder executes them, and a Reflector evaluates predictions and provides constructive feedback, while a memory archive preserves prior designs for reuse and iterative refinement. On benchmark datasets, MedDCR outperforms state-of-the-art baselines and produces interpretable, adaptable workflows that better reflect real coding practice, improving both the reliability and trustworthiness of automated systems.
Distill-C: Enhanced NL2SQL via Distilled Customization with LLMs
Mar 30, 2025The growing adoption of large language models (LLMs) in business applications has amplified interest in Natural Language to SQL (NL2SQL) solutions, in which there is competing demand for high performance and efficiency. Domain- and customer-specific requirements further complicate the problem. To address this conundrum, we introduce Distill-C, a distilled customization framework tailored for NL2SQL tasks. Distill-C utilizes large teacher LLMs to produce high-quality synthetic data through a robust and scalable pipeline. Finetuning smaller and open-source LLMs on this synthesized data enables them to rival or outperform teacher models an order of magnitude larger. Evaluated on multiple challenging benchmarks, Distill-C achieves an average improvement of 36% in execution accuracy compared to the base models from three distinct LLM families. Additionally, on three internal customer benchmarks, Distill-C demonstrates a 22.6% performance improvement over the base models. Our results demonstrate that Distill-C is an effective, high-performing and generalizable approach for deploying lightweight yet powerful NL2SQL models, delivering exceptional accuracies while maintaining low computational cost.
SQLong: Enhanced NL2SQL for Longer Contexts with LLMs
Feb 23, 2025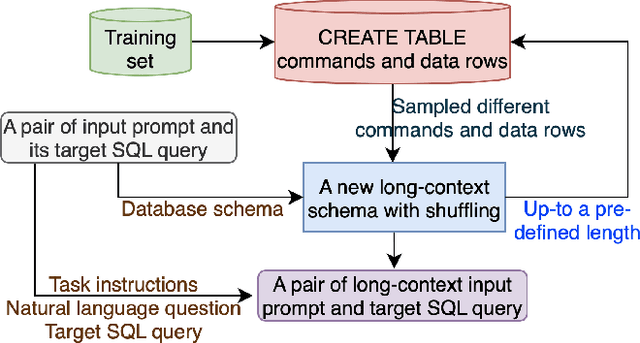
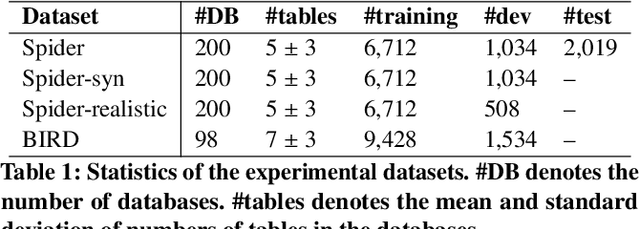

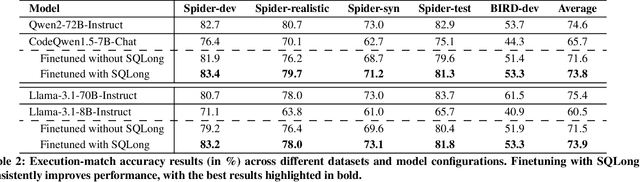
Open-weight large language models (LLMs) have significantly advanced performance in the Natural Language to SQL (NL2SQL) task. However, their effectiveness diminishes when dealing with large database schemas, as the context length increases. To address this limitation, we present SQLong, a novel and efficient data augmentation framework designed to enhance LLM performance in long-context scenarios for the NL2SQL task. SQLong generates augmented datasets by extending existing database schemas with additional synthetic CREATE TABLE commands and corresponding data rows, sampled from diverse schemas in the training data. This approach effectively simulates long-context scenarios during finetuning and evaluation. Through experiments on the Spider and BIRD datasets, we demonstrate that LLMs finetuned with SQLong-augmented data significantly outperform those trained on standard datasets. These imply SQLong's practical implementation and its impact on improving NL2SQL capabilities in real-world settings with complex database schemas.
An Unsupervised Probability Model for Speech-to-Translation Alignment of Low-Resource Languages
Sep 26, 2016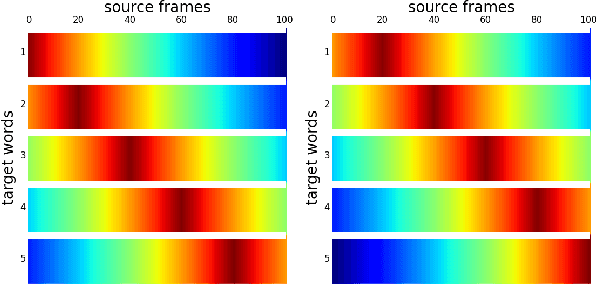
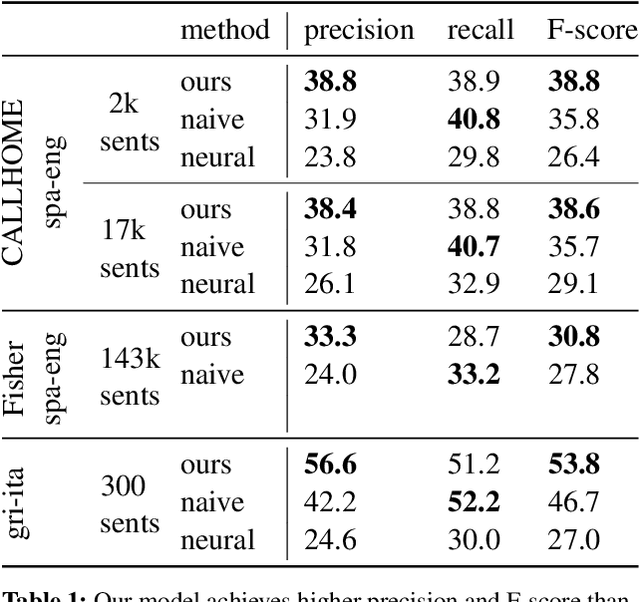

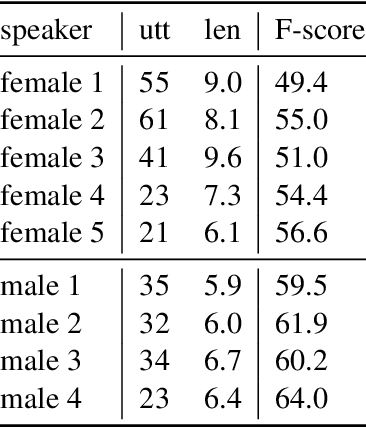
For many low-resource languages, spoken language resources are more likely to be annotated with translations than with transcriptions. Translated speech data is potentially valuable for documenting endangered languages or for training speech translation systems. A first step towards making use of such data would be to automatically align spoken words with their translations. We present a model that combines Dyer et al.'s reparameterization of IBM Model 2 (fast-align) and k-means clustering using Dynamic Time Warping as a distance metric. The two components are trained jointly using expectation-maximization. In an extremely low-resource scenario, our model performs significantly better than both a neural model and a strong baseline.
Learning Crosslingual Word Embeddings without Bilingual Corpora
Jun 30, 2016

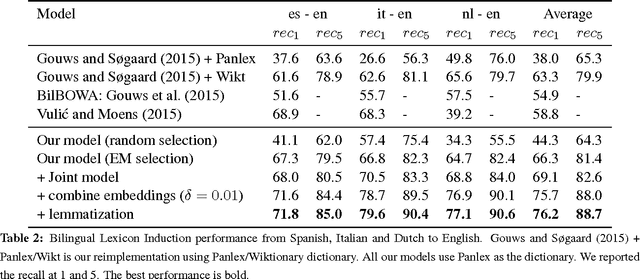
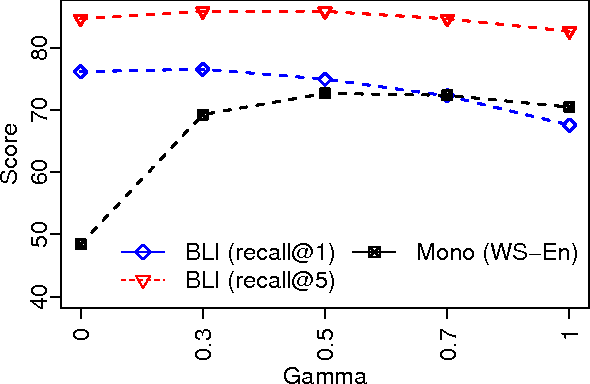
Crosslingual word embeddings represent lexical items from different languages in the same vector space, enabling transfer of NLP tools. However, previous attempts had expensive resource requirements, difficulty incorporating monolingual data or were unable to handle polysemy. We address these drawbacks in our method which takes advantage of a high coverage dictionary in an EM style training algorithm over monolingual corpora in two languages. Our model achieves state-of-the-art performance on bilingual lexicon induction task exceeding models using large bilingual corpora, and competitive results on the monolingual word similarity and cross-lingual document classification task.