 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining Neural Activation Patterns for Layer-Level Concept Discovery in Neural Network-Based Receivers
May 21, 2025Concept discovery in neural networks often targets individual neurons or human-interpretable features, overlooking distributed layer-wide patterns. We study the Neural Activation Pattern (NAP) methodology, which clusters full-layer activation distributions to identify such layer-level concepts. Applied to visual object recognition and radio receiver models, we propose improved normalization, distribution estimation, distance metrics, and varied cluster selection. In the radio receiver model, distinct concepts did not emerge; instead, a continuous activation manifold shaped by Signal-to-Noise Ratio (SNR) was observed -- highlighting SNR as a key learned factor, consistent with classical receiver behavior and supporting physical plausibility. Our enhancements to NAP improved in-distribution vs. out-of-distribution separation, suggesting better generalization and indirectly validating clustering quality. These results underscore the importance of clustering design and activation manifolds in interpreting and troubleshooting neural network behavior.
SQLong: Enhanced NL2SQL for Longer Contexts with LLMs
Feb 23, 2025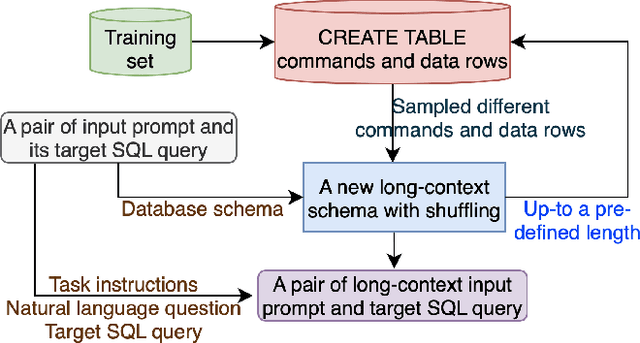
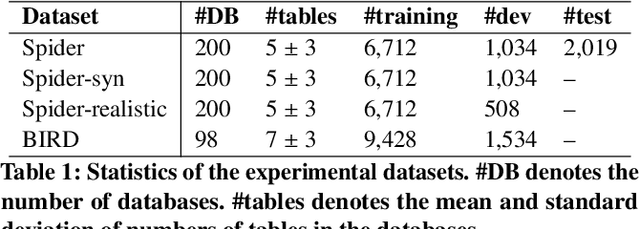

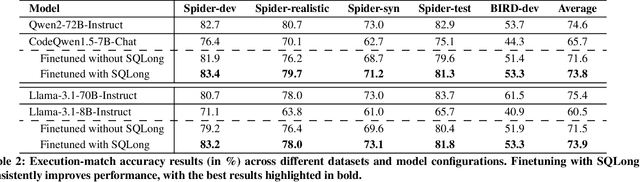
Open-weight large language models (LLMs) have significantly advanced performance in the Natural Language to SQL (NL2SQL) task. However, their effectiveness diminishes when dealing with large database schemas, as the context length increases. To address this limitation, we present SQLong, a novel and efficient data augmentation framework designed to enhance LLM performance in long-context scenarios for the NL2SQL task. SQLong generates augmented datasets by extending existing database schemas with additional synthetic CREATE TABLE commands and corresponding data rows, sampled from diverse schemas in the training data. This approach effectively simulates long-context scenarios during finetuning and evaluation. Through experiments on the Spider and BIRD datasets, we demonstrate that LLMs finetuned with SQLong-augmented data significantly outperform those trained on standard datasets. These imply SQLong's practical implementation and its impact on improving NL2SQL capabilities in real-world settings with complex database schemas.
Exploiting Text and Network Context for Geolocation of Social Media Users
Jun 16, 2015

Research on automatically geolocating social media users has conventionally been based on the text content of posts from a given user or the social network of the user, with very little crossover between the two, and no bench-marking of the two approaches over compara- ble datasets. We bring the two threads of research together in first proposing a text-based method based on adaptive grids, followed by a hybrid network- and text-based method. Evaluating over three Twitter datasets, we show that the empirical difference between text- and network-based methods is not great, and that hybridisation of the two is superior to the component methods, especially in contexts where the user graph is not well connected. We achieve state-of-the-art results on all three datasets.