 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind Your Margin and Boundary: Are Your Distilled Datasets Truly Robust?
May 20, 2026Dataset distillation (DD) compresses a large training set into a small synthetic set for efficient training, but most DD methods optimize only clean accuracy and leave robustness uncontrolled. Recent robust DD methods improve robustness, yet they often suffer from a poor accuracy-robustness trade-off because they (i) treat all adversarially perturbed examples uniformly, despite robust risk being dominated by near-zero robust margins, and (ii) do not explicitly increase inter-class separation in the decision boundary where attacks concentrate. We present Contrastive Curriculum for Robust Dataset Distillation (C$^2$R), a framework that couples an attack-aware curriculum with a contrastive robustness objective. From a robust-margin perspective, we derive a perturbation score that approximates each sample's robust hinge, enabling a curriculum that prioritizes the smallest-margin adversaries that most directly drive robust error. In parallel, a class-balanced contrastive robustness loss enforces adversarial invariance while explicitly widening boundary separation across classes. Experiments on CIFAR-10/100, Tiny-ImageNet, and multiple ImageNet-1K subsets under six attacks show that C$^2$R achieves the best robust accuracy, outperforming prior robust DD by $2.8$% on average.
One Model, Two Minds: Task-Conditioned Reasoning for Unified Image Quality and Aesthetic Assessment
Mar 20, 2026Unifying Image Quality Assessment (IQA) and Image Aesthetic Assessment (IAA) in a single multimodal large language model is appealing, yet existing methods adopt a task-agnostic recipe that applies the same reasoning strategy and reward to both tasks. We show this is fundamentally misaligned: IQA relies on low-level, objective perceptual cues and benefits from concise distortion-focused reasoning, whereas IAA requires deliberative semantic judgment and is poorly served by point-wise score regression. We identify these as a reasoning mismatch and an optimization mismatch, and provide empirical evidence for both through controlled probes. Motivated by these findings, we propose TATAR (Task-Aware Thinking with Asymmetric Rewards), a unified framework that shares the visual-language backbone while conditioning post-training on each task's nature. TATAR combines three components: fast--slow task-specific reasoning construction that pairs IQA with concise perceptual rationales and IAA with deliberative aesthetic narratives; two-stage SFT+GRPO learning that establishes task-aware behavioral priors before reward-driven refinement; and asymmetric rewards that apply Gaussian score shaping for IQA and Thurstone-style completion ranking for IAA. Extensive experiments across eight benchmarks demonstrate that TATAR consistently outperforms prior unified baselines on both tasks under in-domain and cross-domain settings, remains competitive with task-specific specialized models, and yields more stable training dynamics for aesthetic assessment. Our results establish task-conditioned post-training as a principled paradigm for unified perceptual scoring. Our code is publicly available at https://github.com/yinwen2019/TATAR.
TiCAL:Typicality-Based Consistency-Aware Learning for Multimodal Emotion Recognition
Nov 19, 2025Multimodal Emotion Recognition (MER) aims to accurately identify human emotional states by integrating heterogeneous modalities such as visual, auditory, and textual data. Existing approaches predominantly rely on unified emotion labels to supervise model training, often overlooking a critical challenge: inter-modal emotion conflicts, wherein different modalities within the same sample may express divergent emotional tendencies. In this work, we address this overlooked issue by proposing a novel framework, Typicality-based Consistent-aware Multimodal Emotion Recognition (TiCAL), inspired by the stage-wise nature of human emotion perception. TiCAL dynamically assesses the consistency of each training sample by leveraging pseudo unimodal emotion labels alongside a typicality estimation. To further enhance emotion representation, we embed features in a hyperbolic space, enabling the capture of fine-grained distinctions among emotional categories. By incorporating consistency estimates into the learning process, our method improves model performance, particularly on samples exhibiting high modality inconsistency. Extensive experiments on benchmark datasets, e.g, CMU-MOSEI and MER2023, validate the effectiveness of TiCAL in mitigating inter-modal emotional conflicts and enhancing overall recognition accuracy, e.g., with about 2.6% improvements over the state-of-the-art DMD.
MedDCR: Learning to Design Agentic Workflows for Medical Coding
Nov 17, 2025Medical coding converts free-text clinical notes into standardized diagnostic and procedural codes, which are essential for billing, hospital operations, and medical research. Unlike ordinary text classification, it requires multi-step reasoning: extracting diagnostic concepts, applying guideline constraints, mapping to hierarchical codebooks, and ensuring cross-document consistency. Recent advances leverage agentic LLMs, but most rely on rigid, manually crafted workflows that fail to capture the nuance and variability of real-world documentation, leaving open the question of how to systematically learn effective workflows. We present MedDCR, a closed-loop framework that treats workflow design as a learning problem. A Designer proposes workflows, a Coder executes them, and a Reflector evaluates predictions and provides constructive feedback, while a memory archive preserves prior designs for reuse and iterative refinement. On benchmark datasets, MedDCR outperforms state-of-the-art baselines and produces interpretable, adaptable workflows that better reflect real coding practice, improving both the reliability and trustworthiness of automated systems.
Knowledge-Aligned Counterfactual-Enhancement Diffusion Perception for Unsupervised Cross-Domain Visual Emotion Recognition
May 26, 2025Visual Emotion Recognition (VER) is a critical yet challenging task aimed at inferring emotional states of individuals based on visual cues. However, existing works focus on single domains, e.g., realistic images or stickers, limiting VER models' cross-domain generalizability. To fill this gap, we introduce an Unsupervised Cross-Domain Visual Emotion Recognition (UCDVER) task, which aims to generalize visual emotion recognition from the source domain (e.g., realistic images) to the low-resource target domain (e.g., stickers) in an unsupervised manner. Compared to the conventional unsupervised domain adaptation problems, UCDVER presents two key challenges: a significant emotional expression variability and an affective distribution shift. To mitigate these issues, we propose the Knowledge-aligned Counterfactual-enhancement Diffusion Perception (KCDP) framework. Specifically, KCDP leverages a VLM to align emotional representations in a shared knowledge space and guides diffusion models for improved visual affective perception. Furthermore, a Counterfactual-Enhanced Language-image Emotional Alignment (CLIEA) method generates high-quality pseudo-labels for the target domain. Extensive experiments demonstrate that our model surpasses SOTA models in both perceptibility and generalization, e.g., gaining 12% improvements over the SOTA VER model TGCA-PVT. The project page is at https://yinwen2019.github.io/ucdver.
Distill-C: Enhanced NL2SQL via Distilled Customization with LLMs
Mar 30, 2025The growing adoption of large language models (LLMs) in business applications has amplified interest in Natural Language to SQL (NL2SQL) solutions, in which there is competing demand for high performance and efficiency. Domain- and customer-specific requirements further complicate the problem. To address this conundrum, we introduce Distill-C, a distilled customization framework tailored for NL2SQL tasks. Distill-C utilizes large teacher LLMs to produce high-quality synthetic data through a robust and scalable pipeline. Finetuning smaller and open-source LLMs on this synthesized data enables them to rival or outperform teacher models an order of magnitude larger. Evaluated on multiple challenging benchmarks, Distill-C achieves an average improvement of 36% in execution accuracy compared to the base models from three distinct LLM families. Additionally, on three internal customer benchmarks, Distill-C demonstrates a 22.6% performance improvement over the base models. Our results demonstrate that Distill-C is an effective, high-performing and generalizable approach for deploying lightweight yet powerful NL2SQL models, delivering exceptional accuracies while maintaining low computational cost.
SQLong: Enhanced NL2SQL for Longer Contexts with LLMs
Feb 23, 2025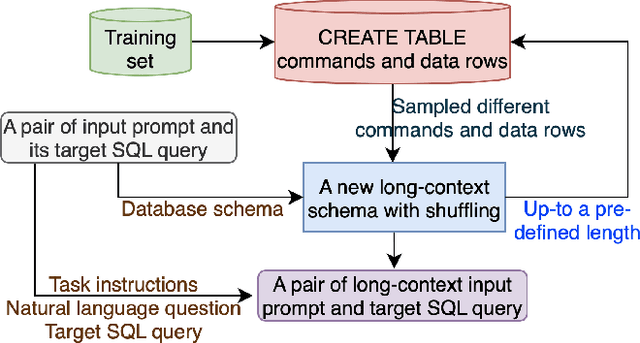
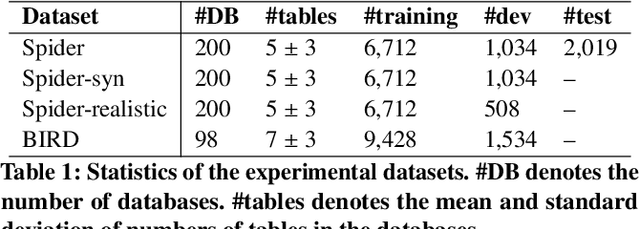

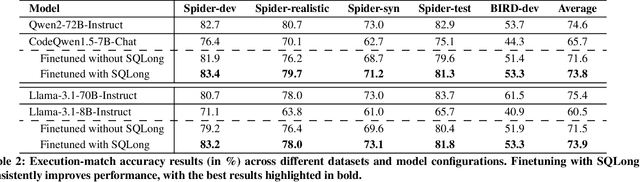
Open-weight large language models (LLMs) have significantly advanced performance in the Natural Language to SQL (NL2SQL) task. However, their effectiveness diminishes when dealing with large database schemas, as the context length increases. To address this limitation, we present SQLong, a novel and efficient data augmentation framework designed to enhance LLM performance in long-context scenarios for the NL2SQL task. SQLong generates augmented datasets by extending existing database schemas with additional synthetic CREATE TABLE commands and corresponding data rows, sampled from diverse schemas in the training data. This approach effectively simulates long-context scenarios during finetuning and evaluation. Through experiments on the Spider and BIRD datasets, we demonstrate that LLMs finetuned with SQLong-augmented data significantly outperform those trained on standard datasets. These imply SQLong's practical implementation and its impact on improving NL2SQL capabilities in real-world settings with complex database schemas.
A Unified Hyperparameter Optimization Pipeline for Transformer-Based Time Series Forecasting Models
Jan 02, 2025



Transformer-based models for time series forecasting (TSF) have attracted significant attention in recent years due to their effectiveness and versatility. However, these models often require extensive hyperparameter optimization (HPO) to achieve the best possible performance, and a unified pipeline for HPO in transformer-based TSF remains lacking. In this paper, we present one such pipeline and conduct extensive experiments on several state-of-the-art (SOTA) transformer-based TSF models. These experiments are conducted on standard benchmark datasets to evaluate and compare the performance of different models, generating practical insights and examples. Our pipeline is generalizable beyond transformer-based architectures and can be applied to other SOTA models, such as Mamba and TimeMixer, as demonstrated in our experiments. The goal of this work is to provide valuable guidance to both industry practitioners and academic researchers in efficiently identifying optimal hyperparameters suited to their specific domain applications. The code and complete experimental results are available on GitHub.
Scalable and Effective Negative Sample Generation for Hyperedge Prediction
Nov 19, 2024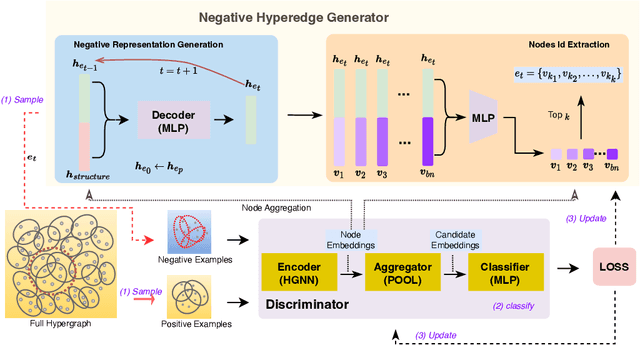
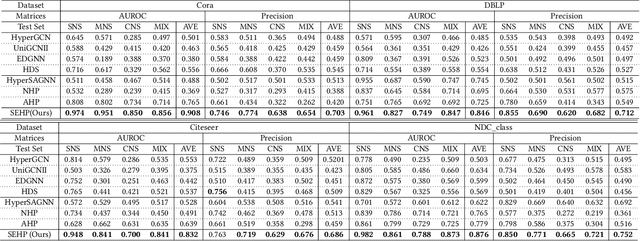
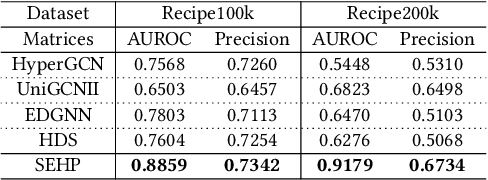
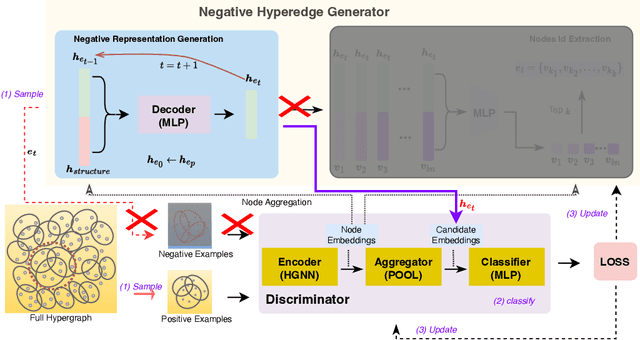
Hyperedge prediction is crucial in hypergraph analysis for understanding complex multi-entity interactions in various web-based applications, including social networks and e-commerce systems. Traditional methods often face difficulties in generating high-quality negative samples due to the imbalance between positive and negative instances. To address this, we present the Scalable and Effective Negative Sample Generation for Hyperedge Prediction (SEHP) framework, which utilizes diffusion models to tackle these challenges. SEHP employs a boundary-aware loss function that iteratively refines negative samples, moving them closer to decision boundaries to improve classification performance. SEHP samples positive instances to form sub-hypergraphs for scalable batch processing. By using structural information from sub-hypergraphs as conditions within the diffusion process, SEHP effectively captures global patterns. To enhance efficiency, our approach operates directly in latent space, avoiding the need for discrete ID generation and resulting in significant speed improvements while preserving accuracy. Extensive experiments show that SEHP outperforms existing methods in accuracy, efficiency, and scalability, representing a substantial advancement in hyperedge prediction techniques. Our code is available here.
An Empirical Analysis on Spatial Reasoning Capabilities of Large Multimodal Models
Nov 09, 2024
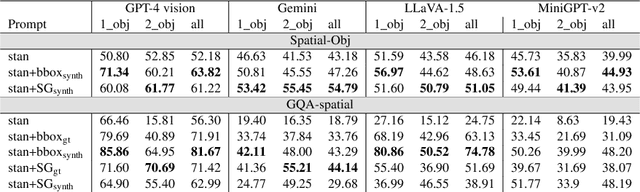

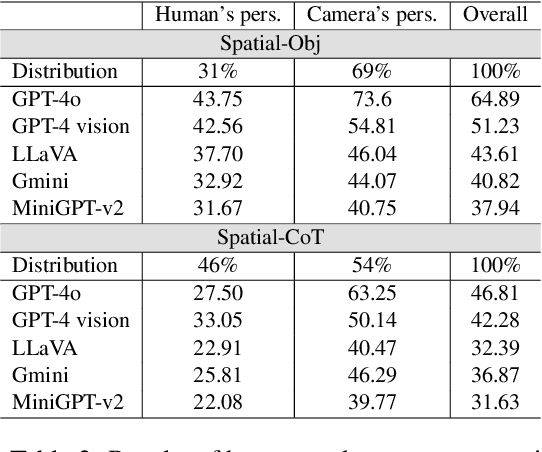
Large Multimodal Models (LMMs) have achieved strong performance across a range of vision and language tasks. However, their spatial reasoning capabilities are under-investigated. In this paper, we construct a novel VQA dataset, Spatial-MM, to comprehensively study LMMs' spatial understanding and reasoning capabilities. Our analyses on object-relationship and multi-hop reasoning reveal several important findings. Firstly, bounding boxes and scene graphs, even synthetic ones, can significantly enhance LMMs' spatial reasoning. Secondly, LMMs struggle more with questions posed from the human perspective than the camera perspective about the image. Thirdly, chain of thought (CoT) prompting does not improve model performance on complex multi-hop questions involving spatial relations. % Moreover, spatial reasoning steps are much less accurate than non-spatial ones across MLLMs. Lastly, our perturbation analysis on GQA-spatial reveals that LMMs are much stronger at basic object detection than complex spatial reasoning. We believe our benchmark dataset and in-depth analyses can spark further research on LMMs spatial reasoning. Spatial-MM benchmark is available at: https://github.com/FatemehShiri/Spatial-MM