 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDWM: Towards a Unified Driving World Model via Multifaceted Representation Learning
Feb 02, 2026Achieving reliable and efficient planning in complex driving environments requires a model that can reason over the scene's geometry, appearance, and dynamics. We present UniDWM, a unified driving world model that advances autonomous driving through multifaceted representation learning. UniDWM constructs a structure- and dynamic-aware latent world representation that serves as a physically grounded state space, enabling consistent reasoning across perception, prediction, and planning. Specifically, a joint reconstruction pathway learns to recover the scene's structure, including geometry and visual texture, while a collaborative generation framework leverages a conditional diffusion transformer to forecast future world evolution within the latent space. Furthermore, we show that our UniDWM can be deemed as a variation of VAE, which provides theoretical guidance for the multifaceted representation learning. Extensive experiments demonstrate the effectiveness of UniDWM in trajectory planning, 4D reconstruction and generation, highlighting the potential of multifaceted world representations as a foundation for unified driving intelligence. The code will be publicly available at https://github.com/Say2L/UniDWM.
TiCAL:Typicality-Based Consistency-Aware Learning for Multimodal Emotion Recognition
Nov 19, 2025Multimodal Emotion Recognition (MER) aims to accurately identify human emotional states by integrating heterogeneous modalities such as visual, auditory, and textual data. Existing approaches predominantly rely on unified emotion labels to supervise model training, often overlooking a critical challenge: inter-modal emotion conflicts, wherein different modalities within the same sample may express divergent emotional tendencies. In this work, we address this overlooked issue by proposing a novel framework, Typicality-based Consistent-aware Multimodal Emotion Recognition (TiCAL), inspired by the stage-wise nature of human emotion perception. TiCAL dynamically assesses the consistency of each training sample by leveraging pseudo unimodal emotion labels alongside a typicality estimation. To further enhance emotion representation, we embed features in a hyperbolic space, enabling the capture of fine-grained distinctions among emotional categories. By incorporating consistency estimates into the learning process, our method improves model performance, particularly on samples exhibiting high modality inconsistency. Extensive experiments on benchmark datasets, e.g, CMU-MOSEI and MER2023, validate the effectiveness of TiCAL in mitigating inter-modal emotional conflicts and enhancing overall recognition accuracy, e.g., with about 2.6% improvements over the state-of-the-art DMD.
VLMs Guided Interpretable Decision Making for Autonomous Driving
Nov 17, 2025



Recent advancements in autonomous driving (AD) have explored the use of vision-language models (VLMs) within visual question answering (VQA) frameworks for direct driving decision-making. However, these approaches often depend on handcrafted prompts and suffer from inconsistent performance, limiting their robustness and generalization in real-world scenarios. In this work, we evaluate state-of-the-art open-source VLMs on high-level decision-making tasks using ego-view visual inputs and identify critical limitations in their ability to deliver reliable, context-aware decisions. Motivated by these observations, we propose a new approach that shifts the role of VLMs from direct decision generators to semantic enhancers. Specifically, we leverage their strong general scene understanding to enrich existing vision-based benchmarks with structured, linguistically rich scene descriptions. Building on this enriched representation, we introduce a multi-modal interactive architecture that fuses visual and linguistic features for more accurate decision-making and interpretable textual explanations. Furthermore, we design a post-hoc refinement module that utilizes VLMs to enhance prediction reliability. Extensive experiments on two autonomous driving benchmarks demonstrate that our approach achieves state-of-the-art performance, offering a promising direction for integrating VLMs into reliable and interpretable AD systems.
StructLayoutFormer:Conditional Structured Layout Generation via Structure Serialization and Disentanglement
Oct 30, 2025Structured layouts are preferable in many 2D visual contents (\eg, GUIs, webpages) since the structural information allows convenient layout editing. Computational frameworks can help create structured layouts but require heavy labor input. Existing data-driven approaches are effective in automatically generating fixed layouts but fail to produce layout structures. We present StructLayoutFormer, a novel Transformer-based approach for conditional structured layout generation. We use a structure serialization scheme to represent structured layouts as sequences. To better control the structures of generated layouts, we disentangle the structural information from the element placements. Our approach is the first data-driven approach that achieves conditional structured layout generation and produces realistic layout structures explicitly. We compare our approach with existing data-driven layout generation approaches by including post-processing for structure extraction. Extensive experiments have shown that our approach exceeds these baselines in conditional structured layout generation. We also demonstrate that our approach is effective in extracting and transferring layout structures. The code is publicly available at %\href{https://github.com/Teagrus/StructLayoutFormer} {https://github.com/Teagrus/StructLayoutFormer}.
Knowledge-Aligned Counterfactual-Enhancement Diffusion Perception for Unsupervised Cross-Domain Visual Emotion Recognition
May 26, 2025Visual Emotion Recognition (VER) is a critical yet challenging task aimed at inferring emotional states of individuals based on visual cues. However, existing works focus on single domains, e.g., realistic images or stickers, limiting VER models' cross-domain generalizability. To fill this gap, we introduce an Unsupervised Cross-Domain Visual Emotion Recognition (UCDVER) task, which aims to generalize visual emotion recognition from the source domain (e.g., realistic images) to the low-resource target domain (e.g., stickers) in an unsupervised manner. Compared to the conventional unsupervised domain adaptation problems, UCDVER presents two key challenges: a significant emotional expression variability and an affective distribution shift. To mitigate these issues, we propose the Knowledge-aligned Counterfactual-enhancement Diffusion Perception (KCDP) framework. Specifically, KCDP leverages a VLM to align emotional representations in a shared knowledge space and guides diffusion models for improved visual affective perception. Furthermore, a Counterfactual-Enhanced Language-image Emotional Alignment (CLIEA) method generates high-quality pseudo-labels for the target domain. Extensive experiments demonstrate that our model surpasses SOTA models in both perceptibility and generalization, e.g., gaining 12% improvements over the SOTA VER model TGCA-PVT. The project page is at https://yinwen2019.github.io/ucdver.
Mixture of Attention Yields Accurate Results for Tabular Data
Feb 18, 2025



Tabular data inherently exhibits significant feature heterogeneity, but existing transformer-based methods lack specialized mechanisms to handle this property. To bridge the gap, we propose MAYA, an encoder-decoder transformer-based framework. In the encoder, we design a Mixture of Attention (MOA) that constructs multiple parallel attention branches and averages the features at each branch, effectively fusing heterogeneous features while limiting parameter growth. Additionally, we employ collaborative learning with a dynamic consistency weight constraint to produce more robust representations. In the decoder stage, cross-attention is utilized to seamlessly integrate tabular data with corresponding label features. This dual-attention mechanism effectively captures both intra-instance and inter-instance interactions. We evaluate the proposed method on a wide range of datasets and compare it with other state-of-the-art transformer-based methods. Extensive experiments demonstrate that our model achieves superior performance among transformer-based methods in both tabular classification and regression tasks.
Degradation-Aware Residual-Conditioned Optimal Transport for Unified Image Restoration
Nov 03, 2024



All-in-one image restoration has emerged as a practical and promising low-level vision task for real-world applications. In this context, the key issue lies in how to deal with different types of degraded images simultaneously. In this work, we present a Degradation-Aware Residual-Conditioned Optimal Transport (DA-RCOT) approach that models (all-in-one) image restoration as an optimal transport (OT) problem for unpaired and paired settings, introducing the transport residual as a degradation-specific cue for both the transport cost and the transport map. Specifically, we formalize image restoration with a residual-guided OT objective by exploiting the degradation-specific patterns of the Fourier residual in the transport cost. More crucially, we design the transport map for restoration as a two-pass DA-RCOT map, in which the transport residual is computed in the first pass and then encoded as multi-scale residual embeddings to condition the second-pass restoration. This conditioning process injects intrinsic degradation knowledge (e.g., degradation type and level) and structural information from the multi-scale residual embeddings into the OT map, which thereby can dynamically adjust its behaviors for all-in-one restoration. Extensive experiments across five degradations demonstrate the favorable performance of DA-RCOT as compared to state-of-the-art methods, in terms of distortion measures, perceptual quality, and image structure preservation. Notably, DA-RCOT delivers superior adaptability to real-world scenarios even with multiple degradations and shows distinctive robustness to both degradation levels and the number of degradations.
Enhancing Skin Disease Diagnosis: Interpretable Visual Concept Discovery with SAM Empowerment
Sep 14, 2024
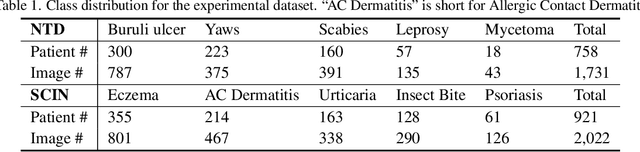


Current AI-assisted skin image diagnosis has achieved dermatologist-level performance in classifying skin cancer, driven by rapid advancements in deep learning architectures. However, unlike traditional vision tasks, skin images in general present unique challenges due to the limited availability of well-annotated datasets, complex variations in conditions, and the necessity for detailed interpretations to ensure patient safety. Previous segmentation methods have sought to reduce image noise and enhance diagnostic performance, but these techniques require fine-grained, pixel-level ground truth masks for training. In contrast, with the rise of foundation models, the Segment Anything Model (SAM) has been introduced to facilitate promptable segmentation, enabling the automation of the segmentation process with simple yet effective prompts. Efforts applying SAM predominantly focus on dermatoscopy images, which present more easily identifiable lesion boundaries than clinical photos taken with smartphones. This limitation constrains the practicality of these approaches to real-world applications. To overcome the challenges posed by noisy clinical photos acquired via non-standardized protocols and to improve diagnostic accessibility, we propose a novel Cross-Attentive Fusion framework for interpretable skin lesion diagnosis. Our method leverages SAM to generate visual concepts for skin diseases using prompts, integrating local visual concepts with global image features to enhance model performance. Extensive evaluation on two skin disease datasets demonstrates our proposed method's effectiveness on lesion diagnosis and interpretability.
Adversarial Attacks to Multi-Modal Models
Sep 10, 2024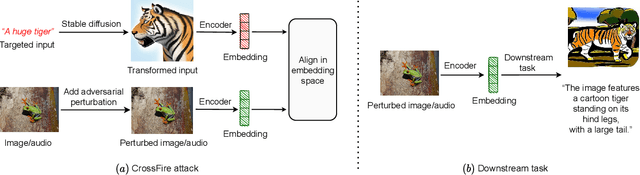



Multi-modal models have gained significant attention due to their powerful capabilities. These models effectively align embeddings across diverse data modalities, showcasing superior performance in downstream tasks compared to their unimodal counterparts. Recent study showed that the attacker can manipulate an image or audio file by altering it in such a way that its embedding matches that of an attacker-chosen targeted input, thereby deceiving downstream models. However, this method often underperforms due to inherent disparities in data from different modalities. In this paper, we introduce CrossFire, an innovative approach to attack multi-modal models. CrossFire begins by transforming the targeted input chosen by the attacker into a format that matches the modality of the original image or audio file. We then formulate our attack as an optimization problem, aiming to minimize the angular deviation between the embeddings of the transformed input and the modified image or audio file. Solving this problem determines the perturbations to be added to the original media. Our extensive experiments on six real-world benchmark datasets reveal that CrossFire can significantly manipulate downstream tasks, surpassing existing attacks. Additionally, we evaluate six defensive strategies against CrossFire, finding that current defenses are insufficient to counteract our CrossFire.
Residual-Conditioned Optimal Transport: Towards Structure-preserving Unpaired and Paired Image Restoration
May 05, 2024



Deep learning-based image restoration methods have achieved promising performance. However, how to faithfully preserve the structure of the original image remains challenging. To address this challenge, we propose a novel Residual-Conditioned Optimal Transport (RCOT) approach, which models the image restoration as an optimal transport (OT) problem for both unpaired and paired settings, integrating the transport residual as a unique degradation-specific cue for both the transport cost and the transport map. Specifically, we first formalize a Fourier residual-guided OT objective by incorporating the degradation-specific information of the residual into the transport cost. Based on the dual form of the OT formulation, we design the transport map as a two-pass RCOT map that comprises a base model and a refinement process, in which the transport residual is computed by the base model in the first pass and then encoded as a degradation-specific embedding to condition the second-pass restoration. By duality, the RCOT problem is transformed into a minimax optimization problem, which can be solved by adversarially training neural networks. Extensive experiments on multiple restoration tasks show the effectiveness of our approach in terms of both distortion measures and perceptual quality. Particularly, RCOT restores images with more faithful structural details compared to state-of-the-art methods.