 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Input-Output: Rethinking Creativity through Design-by-Analogy in Human-AI Collaboration
Feb 10, 2026While the proliferation of foundation models has significantly boosted individual productivity, it also introduces a potential challenge: the homogenization of creative content. In response, we revisit Design-by-Analogy (DbA), a cognitively grounded approach that fosters novel solutions by mapping inspiration across domains. However, prevailing perspectives often restrict DbA to early ideation or specific data modalities, while reducing AI-driven design to simplified input-output pipelines. Such conceptual limitations inadvertently foster widespread design fixation. To address this, we expand the understanding of DbA by embedding it into the entire creative process, thereby demonstrating its capacity to mitigate such fixation. Through a systematic review of 85 studies, we identify six forms of representation and classify techniques across seven stages of the creative process. We further discuss three major application domains: creative industries, intelligent manufacturing, and education and services, demonstrating DbA's practical relevance. Building on this synthesis, we frame DbA as a mediating technology for human-AI collaboration and outline the potential opportunities and inherent risks for advancing creativity support in HCI and design research.
* 20 pages, 9 figures. Accepted to the 2026 CHI Conference on Human Factors in Computing Systems
Mixture of Attention Yields Accurate Results for Tabular Data
Feb 18, 2025



Tabular data inherently exhibits significant feature heterogeneity, but existing transformer-based methods lack specialized mechanisms to handle this property. To bridge the gap, we propose MAYA, an encoder-decoder transformer-based framework. In the encoder, we design a Mixture of Attention (MOA) that constructs multiple parallel attention branches and averages the features at each branch, effectively fusing heterogeneous features while limiting parameter growth. Additionally, we employ collaborative learning with a dynamic consistency weight constraint to produce more robust representations. In the decoder stage, cross-attention is utilized to seamlessly integrate tabular data with corresponding label features. This dual-attention mechanism effectively captures both intra-instance and inter-instance interactions. We evaluate the proposed method on a wide range of datasets and compare it with other state-of-the-art transformer-based methods. Extensive experiments demonstrate that our model achieves superior performance among transformer-based methods in both tabular classification and regression tasks.
SSAD: Self-supervised Auxiliary Detection Framework for Panoramic X-ray based Dental Disease Diagnosis
Jun 20, 2024Panoramic X-ray is a simple and effective tool for diagnosing dental diseases in clinical practice. When deep learning models are developed to assist dentist in interpreting panoramic X-rays, most of their performance suffers from the limited annotated data, which requires dentist's expertise and a lot of time cost. Although self-supervised learning (SSL) has been proposed to address this challenge, the two-stage process of pretraining and fine-tuning requires even more training time and computational resources. In this paper, we present a self-supervised auxiliary detection (SSAD) framework, which is plug-and-play and compatible with any detectors. It consists of a reconstruction branch and a detection branch. Both branches are trained simultaneously, sharing the same encoder, without the need for finetuning. The reconstruction branch learns to restore the tooth texture of healthy or diseased teeth, while the detection branch utilizes these learned features for diagnosis. To enhance the encoder's ability to capture fine-grained features, we incorporate the image encoder of SAM to construct a texture consistency (TC) loss, which extracts image embedding from the input and output of reconstruction branch, and then enforces both embedding into the same feature space. Extensive experiments on the public DENTEX dataset through three detection tasks demonstrate that the proposed SSAD framework achieves state-of-the-art performance compared to mainstream object detection methods and SSL methods. The code is available at https://github.com/Dylonsword/SSAD
Scalable Ensembling For Mitigating Reward Overoptimisation
Jun 03, 2024



Reinforcement Learning from Human Feedback (RLHF) has enabled significant advancements within language modeling for powerful, instruction-following models. However, the alignment of these models remains a pressing challenge as the policy tends to overfit the learned ``proxy" reward model past an inflection point of utility as measured by a ``gold" reward model that is more performant -- a phenomenon known as \textit{over-optimization}. Prior work has mitigated this issue by computing a pessimistic statistic over an ensemble of reward models, which is common in Offline Reinforcement Learning but incredibly costly for language models with high memory requirements, making such approaches infeasible for sufficiently large models. To this end, we propose using a shared encoder but separate linear heads. We find this leads to similar performance as the full ensemble while allowing tremendous savings in memory and time required for training for models of similar size. \end{abstract}
Linguistic Calibration of Language Models
Mar 30, 2024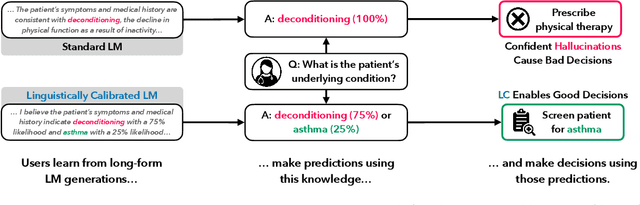

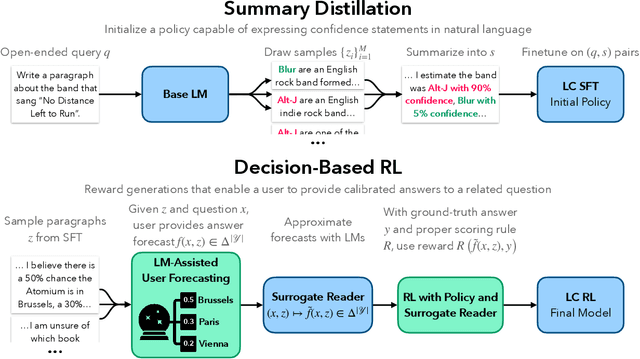
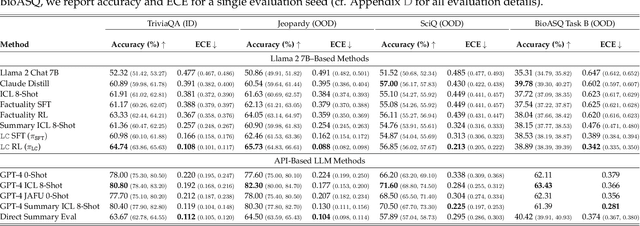
Language models (LMs) may lead their users to make suboptimal downstream decisions when they confidently hallucinate. This issue can be mitigated by having the LM verbally convey the probability that its claims are correct, but existing models cannot produce text with calibrated confidence statements. Through the lens of decision-making, we formalize linguistic calibration for long-form generations: an LM is linguistically calibrated if its generations enable its users to make calibrated probabilistic predictions. This definition enables a training framework where a supervised finetuning step bootstraps an LM to emit long-form generations with confidence statements such as "I estimate a 30% chance of..." or "I am certain that...", followed by a reinforcement learning step which rewards generations that enable a user to provide calibrated answers to related questions. We linguistically calibrate Llama 2 7B and find in automated and human evaluations of long-form generations that it is significantly more calibrated than strong finetuned factuality baselines with comparable accuracy. These findings generalize under distribution shift on question-answering and under a significant task shift to person biography generation. Our results demonstrate that long-form generations may be calibrated end-to-end by constructing an objective in the space of the predictions that users make in downstream decision-making.
SCPMan: Shape Context and Prior Constrained Multi-scale Attention Network for Pancreatic Segmentation
Dec 26, 2023Due to the poor prognosis of Pancreatic cancer, accurate early detection and segmentation are critical for improving treatment outcomes. However, pancreatic segmentation is challenged by blurred boundaries, high shape variability, and class imbalance. To tackle these problems, we propose a multiscale attention network with shape context and prior constraint for robust pancreas segmentation. Specifically, we proposed a Multi-scale Feature Extraction Module (MFE) and a Mixed-scale Attention Integration Module (MAI) to address unclear pancreas boundaries. Furthermore, a Shape Context Memory (SCM) module is introduced to jointly model semantics across scales and pancreatic shape. Active Shape Model (ASM) is further used to model the shape priors. Experiments on NIH and MSD datasets demonstrate the efficacy of our model, which improves the state-of-the-art Dice Score for 1.01% and 1.03% respectively. Our architecture provides robust segmentation performance, against the blurry boundaries, and variations in scale and shape of pancreas.
TCSloT: Text Guided 3D Context and Slope Aware Triple Network for Dental Implant Position Prediction
Aug 10, 2023In implant prosthesis treatment, the surgical guide of implant is used to ensure accurate implantation. However, such design heavily relies on the manual location of the implant position. When deep neural network has been proposed to assist the dentist in locating the implant position, most of them take a single slice as input, which do not fully explore 3D contextual information and ignoring the influence of implant slope. In this paper, we design a Text Guided 3D Context and Slope Aware Triple Network (TCSloT) which enables the perception of contextual information from multiple adjacent slices and awareness of variation of implant slopes. A Texture Variation Perception (TVP) module is correspondingly elaborated to process the multiple slices and capture the texture variation among slices and a Slope-Aware Loss (SAL) is proposed to dynamically assign varying weights for the regression head. Additionally, we design a conditional text guidance (CTG) module to integrate the text condition (i.e., left, middle and right) from the CLIP for assisting the implant position prediction. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCSloT achieves superior performance than existing methods.
TCEIP: Text Condition Embedded Regression Network for Dental Implant Position Prediction
Jun 29, 2023When deep neural network has been proposed to assist the dentist in designing the location of dental implant, most of them are targeting simple cases where only one missing tooth is available. As a result, literature works do not work well when there are multiple missing teeth and easily generate false predictions when the teeth are sparsely distributed. In this paper, we are trying to integrate a weak supervision text, the target region, to the implant position regression network, to address above issues. We propose a text condition embedded implant position regression network (TCEIP), to embed the text condition into the encoder-decoder framework for improvement of the regression performance. A cross-modal interaction that consists of cross-modal attention (CMA) and knowledge alignment module (KAM) is proposed to facilitate the interaction between features of images and texts. The CMA module performs a cross-attention between the image feature and the text condition, and the KAM mitigates the knowledge gap between the image feature and the image encoder of the CLIP. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TCEIP achieves superior performance than existing methods.
AlpacaFarm: A Simulation Framework for Methods that Learn from Human Feedback
May 22, 2023


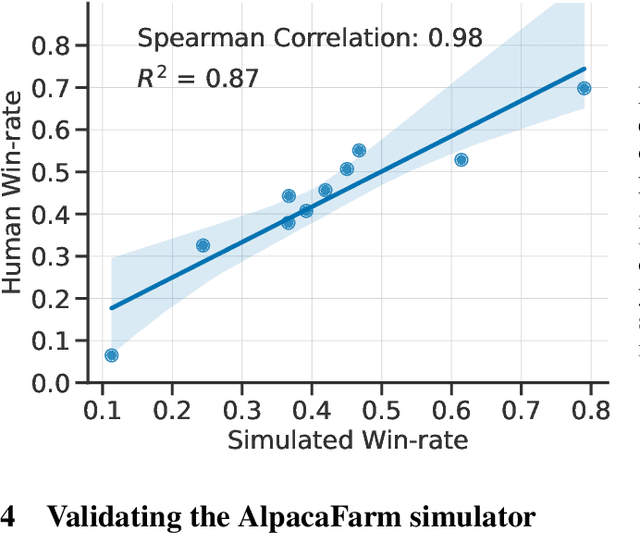
Large language models (LLMs) such as ChatGPT have seen widespread adoption due to their ability to follow user instructions well. Developing these LLMs involves a complex yet poorly understood workflow requiring training with human feedback. Replicating and understanding this instruction-following process faces three major challenges: the high cost of data collection, the lack of trustworthy evaluation, and the absence of reference method implementations. We address these challenges with AlpacaFarm, a simulator that enables research and development for learning from feedback at a low cost. First, we design LLM prompts to simulate human feedback that are 45x cheaper than crowdworkers and display high agreement with humans. Second, we propose an automatic evaluation and validate it against human instructions obtained on real-world interactions. Third, we contribute reference implementations for several methods (PPO, best-of-n, expert iteration, and more) that learn from pairwise feedback. Finally, as an end-to-end validation of AlpacaFarm, we train and evaluate eleven models on 10k pairs of real human feedback and show that rankings of models trained in AlpacaFarm match rankings of models trained on human data. As a demonstration of the research possible in AlpacaFarm, we find that methods that use a reward model can substantially improve over supervised fine-tuning and that our reference PPO implementation leads to a +10% improvement in win-rate against Davinci003. We release all components of AlpacaFarm at https://github.com/tatsu-lab/alpaca_farm.
Two-Stream Regression Network for Dental Implant Position Prediction
May 17, 2023



In implant prosthesis treatment, the design of surgical guide requires lots of manual labors and is prone to subjective variations. When deep learning based methods has started to be applied to address this problem, the space between teeth are various and some of them might present similar texture characteristic with the actual implant region. Both problems make a big challenge for the implant position prediction. In this paper, we develop a two-stream implant position regression framework (TSIPR), which consists of an implant region detector (IRD) and a multi-scale patch embedding regression network (MSPENet), to address this issue. For the training of IRD, we extend the original annotation to provide additional supervisory information, which contains much more rich characteristic and do not introduce extra labeling costs. A multi-scale patch embedding module is designed for the MSPENet to adaptively extract features from the images with various tooth spacing. The global-local feature interaction block is designed to build the encoder of MSPENet, which combines the transformer and convolution for enriched feature representation. During inference, the RoI mask extracted from the IRD is used to refine the prediction results of the MSPENet. Extensive experiments on a dental implant dataset through five-fold cross-validation demonstrated that the proposed TSIPR achieves superior performance than existing methods.