 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX-ray Insights Unleashed: Pioneering the Enhancement of Multi-Label Long-Tail Data
Dec 24, 2025Long-tailed pulmonary anomalies in chest radiography present formidable diagnostic challenges. Despite the recent strides in diffusion-based methods for enhancing the representation of tailed lesions, the paucity of rare lesion exemplars curtails the generative capabilities of these approaches, thereby leaving the diagnostic precision less than optimal. In this paper, we propose a novel data synthesis pipeline designed to augment tail lesions utilizing a copious supply of conventional normal X-rays. Specifically, a sufficient quantity of normal samples is amassed to train a diffusion model capable of generating normal X-ray images. This pre-trained diffusion model is subsequently utilized to inpaint the head lesions present in the diseased X-rays, thereby preserving the tail classes as augmented training data. Additionally, we propose the integration of a Large Language Model Knowledge Guidance (LKG) module alongside a Progressive Incremental Learning (PIL) strategy to stabilize the inpainting fine-tuning process. Comprehensive evaluations conducted on the public lung datasets MIMIC and CheXpert demonstrate that the proposed method sets a new benchmark in performance.
Show-o2: Improved Native Unified Multimodal Models
Jun 18, 2025



This paper presents improved native unified multimodal models, \emph{i.e.,} Show-o2, that leverage autoregressive modeling and flow matching. Built upon a 3D causal variational autoencoder space, unified visual representations are constructed through a dual-path of spatial (-temporal) fusion, enabling scalability across image and video modalities while ensuring effective multimodal understanding and generation. Based on a language model, autoregressive modeling and flow matching are natively applied to the language head and flow head, respectively, to facilitate text token prediction and image/video generation. A two-stage training recipe is designed to effectively learn and scale to larger models. The resulting Show-o2 models demonstrate versatility in handling a wide range of multimodal understanding and generation tasks across diverse modalities, including text, images, and videos. Code and models are released at https://github.com/showlab/Show-o.
MG-MotionLLM: A Unified Framework for Motion Comprehension and Generation across Multiple Granularities
Apr 03, 2025Recent motion-aware large language models have demonstrated promising potential in unifying motion comprehension and generation. However, existing approaches primarily focus on coarse-grained motion-text modeling, where text describes the overall semantics of an entire motion sequence in just a few words. This limits their ability to handle fine-grained motion-relevant tasks, such as understanding and controlling the movements of specific body parts. To overcome this limitation, we pioneer MG-MotionLLM, a unified motion-language model for multi-granular motion comprehension and generation. We further introduce a comprehensive multi-granularity training scheme by incorporating a set of novel auxiliary tasks, such as localizing temporal boundaries of motion segments via detailed text as well as motion detailed captioning, to facilitate mutual reinforcement for motion-text modeling across various levels of granularity. Extensive experiments show that our MG-MotionLLM achieves superior performance on classical text-to-motion and motion-to-text tasks, and exhibits potential in novel fine-grained motion comprehension and editing tasks. Project page: CVI-SZU/MG-MotionLLM
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Aug 22, 2024



We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
Learning Video Context as Interleaved Multimodal Sequences
Jul 31, 2024



Narrative videos, such as movies, pose significant challenges in video understanding due to their rich contexts (characters, dialogues, storylines) and diverse demands (identify who, relationship, and reason). In this paper, we introduce MovieSeq, a multimodal language model developed to address the wide range of challenges in understanding video contexts. Our core idea is to represent videos as interleaved multimodal sequences (including images, plots, videos, and subtitles), either by linking external knowledge databases or using offline models (such as whisper for subtitles). Through instruction-tuning, this approach empowers the language model to interact with videos using interleaved multimodal instructions. For example, instead of solely relying on video as input, we jointly provide character photos alongside their names and dialogues, allowing the model to associate these elements and generate more comprehensive responses. To demonstrate its effectiveness, we validate MovieSeq's performance on six datasets (LVU, MAD, Movienet, CMD, TVC, MovieQA) across five settings (video classification, audio description, video-text retrieval, video captioning, and video question-answering). The code will be public at https://github.com/showlab/MovieSeq.
WMAdapter: Adding WaterMark Control to Latent Diffusion Models
Jun 12, 2024
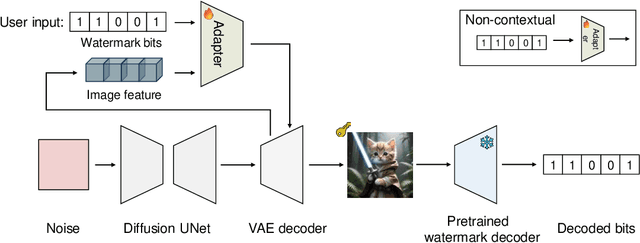
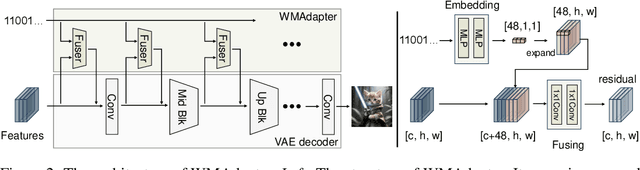
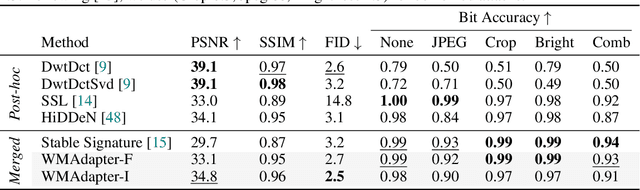
Watermarking is crucial for protecting the copyright of AI-generated images. We propose WMAdapter, a diffusion model watermark plugin that takes user-specified watermark information and allows for seamless watermark imprinting during the diffusion generation process. WMAdapter is efficient and robust, with a strong emphasis on high generation quality. To achieve this, we make two key designs: (1) We develop a contextual adapter structure that is lightweight and enables effective knowledge transfer from heavily pretrained post-hoc watermarking models. (2) We introduce an extra finetuning step and design a hybrid finetuning strategy to further improve image quality and eliminate tiny artifacts. Empirical results demonstrate that WMAdapter offers strong flexibility, exceptional image generation quality and competitive watermark robustness.
Learning Long-form Video Prior via Generative Pre-Training
Apr 24, 2024



Concepts involved in long-form videos such as people, objects, and their interactions, can be viewed as following an implicit prior. They are notably complex and continue to pose challenges to be comprehensively learned. In recent years, generative pre-training (GPT) has exhibited versatile capacities in modeling any kind of text content even visual locations. Can this manner work for learning long-form video prior? Instead of operating on pixel space, it is efficient to employ visual locations like bounding boxes and keypoints to represent key information in videos, which can be simply discretized and then tokenized for consumption by GPT. Due to the scarcity of suitable data, we create a new dataset called \textbf{Storyboard20K} from movies to serve as a representative. It includes synopses, shot-by-shot keyframes, and fine-grained annotations of film sets and characters with consistent IDs, bounding boxes, and whole body keypoints. In this way, long-form videos can be represented by a set of tokens and be learned via generative pre-training. Experimental results validate that our approach has great potential for learning long-form video prior. Code and data will be released at \url{https://github.com/showlab/Long-form-Video-Prior}.
Towards Highly Realistic Artistic Style Transfer via Stable Diffusion with Step-aware and Layer-aware Prompt
Apr 17, 2024
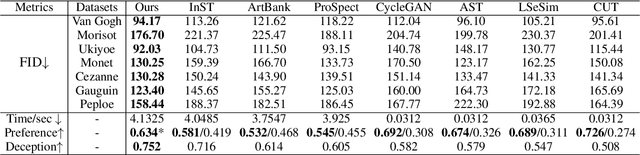
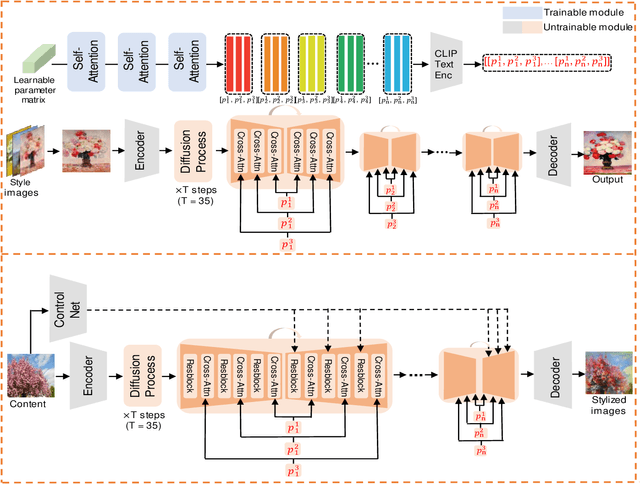
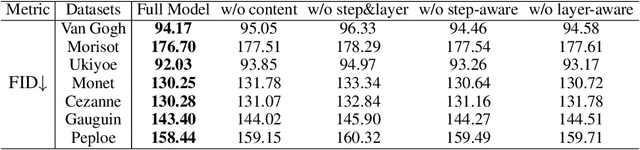
Artistic style transfer aims to transfer the learned artistic style onto an arbitrary content image, generating artistic stylized images. Existing generative adversarial network-based methods fail to generate highly realistic stylized images and always introduce obvious artifacts and disharmonious patterns. Recently, large-scale pre-trained diffusion models opened up a new way for generating highly realistic artistic stylized images. However, diffusion model-based methods generally fail to preserve the content structure of input content images well, introducing some undesired content structure and style patterns. To address the above problems, we propose a novel pre-trained diffusion-based artistic style transfer method, called LSAST, which can generate highly realistic artistic stylized images while preserving the content structure of input content images well, without bringing obvious artifacts and disharmonious style patterns. Specifically, we introduce a Step-aware and Layer-aware Prompt Space, a set of learnable prompts, which can learn the style information from the collection of artworks and dynamically adjusts the input images' content structure and style pattern. To train our prompt space, we propose a novel inversion method, called Step-ware and Layer-aware Prompt Inversion, which allows the prompt space to learn the style information of the artworks collection. In addition, we inject a pre-trained conditional branch of ControlNet into our LSAST, which further improved our framework's ability to maintain content structure. Extensive experiments demonstrate that our proposed method can generate more highly realistic artistic stylized images than the state-of-the-art artistic style transfer methods.
Cross-Attention Makes Inference Cumbersome in Text-to-Image Diffusion Models
Apr 03, 2024This study explores the role of cross-attention during inference in text-conditional diffusion models. We find that cross-attention outputs converge to a fixed point after few inference steps. Accordingly, the time point of convergence naturally divides the entire inference process into two stages: an initial semantics-planning stage, during which, the model relies on cross-attention to plan text-oriented visual semantics, and a subsequent fidelity-improving stage, during which the model tries to generate images from previously planned semantics. Surprisingly, ignoring text conditions in the fidelity-improving stage not only reduces computation complexity, but also maintains model performance. This yields a simple and training-free method called TGATE for efficient generation, which caches the cross-attention output once it converges and keeps it fixed during the remaining inference steps. Our empirical study on the MS-COCO validation set confirms its effectiveness. The source code of TGATE is available at https://github.com/HaozheLiu-ST/T-GATE.
Question-Answer Cross Language Image Matching for Weakly Supervised Semantic Segmentation
Jan 18, 2024Class Activation Map (CAM) has emerged as a popular tool for weakly supervised semantic segmentation (WSSS), allowing the localization of object regions in an image using only image-level labels. However, existing CAM methods suffer from under-activation of target object regions and false-activation of background regions due to the fact that a lack of detailed supervision can hinder the model's ability to understand the image as a whole. In this paper, we propose a novel Question-Answer Cross-Language-Image Matching framework for WSSS (QA-CLIMS), leveraging the vision-language foundation model to maximize the text-based understanding of images and guide the generation of activation maps. First, a series of carefully designed questions are posed to the VQA (Visual Question Answering) model with Question-Answer Prompt Engineering (QAPE) to generate a corpus of both foreground target objects and backgrounds that are adaptive to query images. We then employ contrastive learning in a Region Image Text Contrastive (RITC) network to compare the obtained foreground and background regions with the generated corpus. Our approach exploits the rich textual information from the open vocabulary as additional supervision, enabling the model to generate high-quality CAMs with a more complete object region and reduce false-activation of background regions. We conduct extensive analysis to validate the proposed method and show that our approach performs state-of-the-art on both PASCAL VOC 2012 and MS COCO datasets. Code is available at: https://github.com/CVI-SZU/QA-CLIMS