 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlaf-World: Orienting Latent Actions for Video World Modeling
Feb 10, 2026Scaling action-controllable world models is limited by the scarcity of action labels. While latent action learning promises to extract control interfaces from unlabeled video, learned latents often fail to transfer across contexts: they entangle scene-specific cues and lack a shared coordinate system. This occurs because standard objectives operate only within each clip, providing no mechanism to align action semantics across contexts. Our key insight is that although actions are unobserved, their semantic effects are observable and can serve as a shared reference. We introduce Seq$Δ$-REPA, a sequence-level control-effect alignment objective that anchors integrated latent action to temporal feature differences from a frozen, self-supervised video encoder. Building on this, we present Olaf-World, a pipeline that pretrains action-conditioned video world models from large-scale passive video. Extensive experiments demonstrate that our method learns a more structured latent action space, leading to stronger zero-shot action transfer and more data-efficient adaptation to new control interfaces than state-of-the-art baselines.
MIND: Benchmarking Memory Consistency and Action Control in World Models
Feb 08, 2026World models aim to understand, remember, and predict dynamic visual environments, yet a unified benchmark for evaluating their fundamental abilities remains lacking. To address this gap, we introduce MIND, the first open-domain closed-loop revisited benchmark for evaluating Memory consIstency and action coNtrol in worlD models. MIND contains 250 high-quality videos at 1080p and 24 FPS, including 100 (first-person) + 100 (third-person) video clips under a shared action space and 25 + 25 clips across varied action spaces covering eight diverse scenes. We design an efficient evaluation framework to measure two core abilities: memory consistency and action control, capturing temporal stability and contextual coherence across viewpoints. Furthermore, we design various action spaces, including different character movement speeds and camera rotation angles, to evaluate the action generalization capability across different action spaces under shared scenes. To facilitate future performance benchmarking on MIND, we introduce MIND-World, a novel interactive Video-to-World baseline. Extensive experiments demonstrate the completeness of MIND and reveal key challenges in current world models, including the difficulty of maintaining long-term memory consistency and generalizing across action spaces. Project page: https://csu-jpg.github.io/MIND.github.io/
Tuning-Free Image Editing with Fidelity and Editability via Unified Latent Diffusion Model
Apr 08, 2025Balancing fidelity and editability is essential in text-based image editing (TIE), where failures commonly lead to over- or under-editing issues. Existing methods typically rely on attention injections for structure preservation and leverage the inherent text alignment capabilities of pre-trained text-to-image (T2I) models for editability, but they lack explicit and unified mechanisms to properly balance these two objectives. In this work, we introduce UnifyEdit, a tuning-free method that performs diffusion latent optimization to enable a balanced integration of fidelity and editability within a unified framework. Unlike direct attention injections, we develop two attention-based constraints: a self-attention (SA) preservation constraint for structural fidelity, and a cross-attention (CA) alignment constraint to enhance text alignment for improved editability. However, simultaneously applying both constraints can lead to gradient conflicts, where the dominance of one constraint results in over- or under-editing. To address this challenge, we introduce an adaptive time-step scheduler that dynamically adjusts the influence of these constraints, guiding the diffusion latent toward an optimal balance. Extensive quantitative and qualitative experiments validate the effectiveness of our approach, demonstrating its superiority in achieving a robust balance between structure preservation and text alignment across various editing tasks, outperforming other state-of-the-art methods. The source code will be available at https://github.com/CUC-MIPG/UnifyEdit.
Long-Context Autoregressive Video Modeling with Next-Frame Prediction
Mar 25, 2025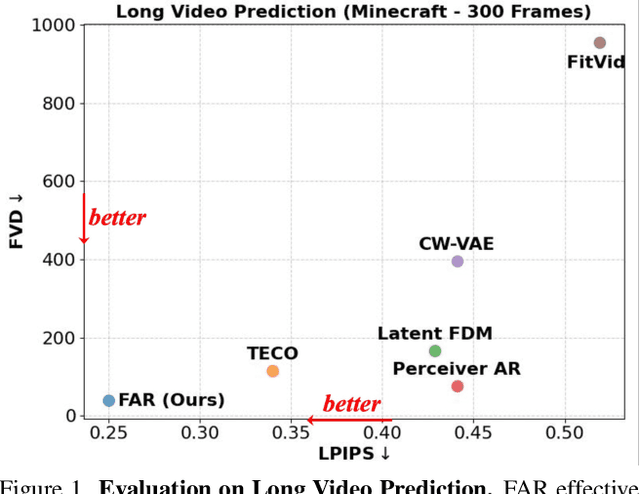
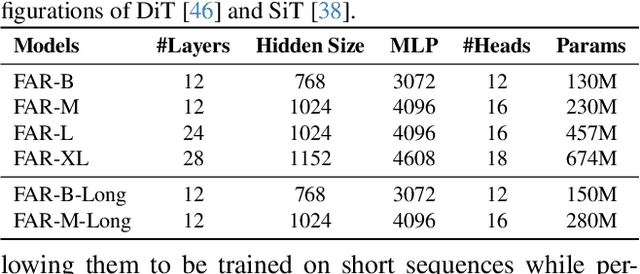
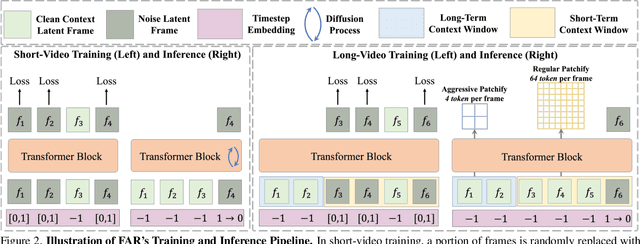
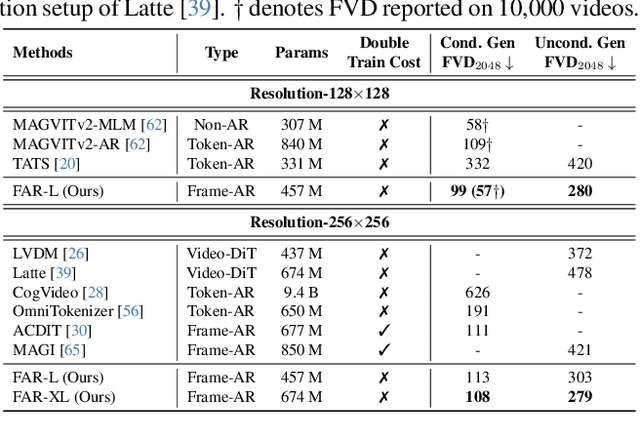
Long-context autoregressive modeling has significantly advanced language generation, but video generation still struggles to fully utilize extended temporal contexts. To investigate long-context video modeling, we introduce Frame AutoRegressive (FAR), a strong baseline for video autoregressive modeling. Just as language models learn causal dependencies between tokens (i.e., Token AR), FAR models temporal causal dependencies between continuous frames, achieving better convergence than Token AR and video diffusion transformers. Building on FAR, we observe that long-context vision modeling faces challenges due to visual redundancy. Existing RoPE lacks effective temporal decay for remote context and fails to extrapolate well to long video sequences. Additionally, training on long videos is computationally expensive, as vision tokens grow much faster than language tokens. To tackle these issues, we propose balancing locality and long-range dependency. We introduce FlexRoPE, an test-time technique that adds flexible temporal decay to RoPE, enabling extrapolation to 16x longer vision contexts. Furthermore, we propose long short-term context modeling, where a high-resolution short-term context window ensures fine-grained temporal consistency, while an unlimited long-term context window encodes long-range information using fewer tokens. With this approach, we can train on long video sequences with a manageable token context length. We demonstrate that FAR achieves state-of-the-art performance in both short- and long-video generation, providing a simple yet effective baseline for video autoregressive modeling.
Edit Transfer: Learning Image Editing via Vision In-Context Relations
Mar 17, 2025We introduce a new setting, Edit Transfer, where a model learns a transformation from just a single source-target example and applies it to a new query image. While text-based methods excel at semantic manipulations through textual prompts, they often struggle with precise geometric details (e.g., poses and viewpoint changes). Reference-based editing, on the other hand, typically focuses on style or appearance and fails at non-rigid transformations. By explicitly learning the editing transformation from a source-target pair, Edit Transfer mitigates the limitations of both text-only and appearance-centric references. Drawing inspiration from in-context learning in large language models, we propose a visual relation in-context learning paradigm, building upon a DiT-based text-to-image model. We arrange the edited example and the query image into a unified four-panel composite, then apply lightweight LoRA fine-tuning to capture complex spatial transformations from minimal examples. Despite using only 42 training samples, Edit Transfer substantially outperforms state-of-the-art TIE and RIE methods on diverse non-rigid scenarios, demonstrating the effectiveness of few-shot visual relation learning.
ROICtrl: Boosting Instance Control for Visual Generation
Nov 27, 2024



Natural language often struggles to accurately associate positional and attribute information with multiple instances, which limits current text-based visual generation models to simpler compositions featuring only a few dominant instances. To address this limitation, this work enhances diffusion models by introducing regional instance control, where each instance is governed by a bounding box paired with a free-form caption. Previous methods in this area typically rely on implicit position encoding or explicit attention masks to separate regions of interest (ROIs), resulting in either inaccurate coordinate injection or large computational overhead. Inspired by ROI-Align in object detection, we introduce a complementary operation called ROI-Unpool. Together, ROI-Align and ROI-Unpool enable explicit, efficient, and accurate ROI manipulation on high-resolution feature maps for visual generation. Building on ROI-Unpool, we propose ROICtrl, an adapter for pretrained diffusion models that enables precise regional instance control. ROICtrl is compatible with community-finetuned diffusion models, as well as with existing spatial-based add-ons (\eg, ControlNet, T2I-Adapter) and embedding-based add-ons (\eg, IP-Adapter, ED-LoRA), extending their applications to multi-instance generation. Experiments show that ROICtrl achieves superior performance in regional instance control while significantly reducing computational costs.
EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Oct 10, 2024
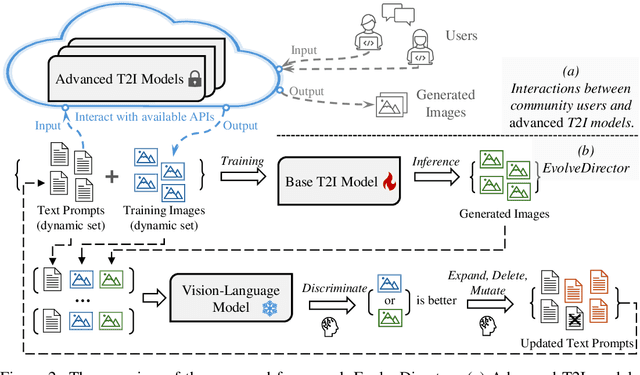

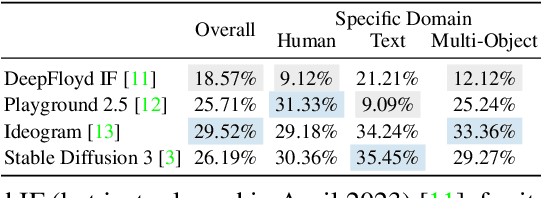
Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The code and model weights are available at https://github.com/showlab/EvolveDirector.
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Aug 22, 2024



We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
DragAnything: Motion Control for Anything using Entity Representation
Mar 15, 2024We introduce DragAnything, which utilizes a entity representation to achieve motion control for any object in controllable video generation. Comparison to existing motion control methods, DragAnything offers several advantages. Firstly, trajectory-based is more userfriendly for interaction, when acquiring other guidance signals (e.g., masks, depth maps) is labor-intensive. Users only need to draw a line (trajectory) during interaction. Secondly, our entity representation serves as an open-domain embedding capable of representing any object, enabling the control of motion for diverse entities, including background. Lastly, our entity representation allows simultaneous and distinct motion control for multiple objects. Extensive experiments demonstrate that our DragAnything achieves state-of-the-art performance for FVD, FID, and User Study, particularly in terms of object motion control, where our method surpasses the previous methods (e.g., DragNUWA) by 26% in human voting.
Towards A Better Metric for Text-to-Video Generation
Jan 15, 2024Generative models have demonstrated remarkable capability in synthesizing high-quality text, images, and videos. For video generation, contemporary text-to-video models exhibit impressive capabilities, crafting visually stunning videos. Nonetheless, evaluating such videos poses significant challenges. Current research predominantly employs automated metrics such as FVD, IS, and CLIP Score. However, these metrics provide an incomplete analysis, particularly in the temporal assessment of video content, thus rendering them unreliable indicators of true video quality. Furthermore, while user studies have the potential to reflect human perception accurately, they are hampered by their time-intensive and laborious nature, with outcomes that are often tainted by subjective bias. In this paper, we investigate the limitations inherent in existing metrics and introduce a novel evaluation pipeline, the Text-to-Video Score (T2VScore). This metric integrates two pivotal criteria: (1) Text-Video Alignment, which scrutinizes the fidelity of the video in representing the given text description, and (2) Video Quality, which evaluates the video's overall production caliber with a mixture of experts. Moreover, to evaluate the proposed metrics and facilitate future improvements on them, we present the TVGE dataset, collecting human judgements of 2,543 text-to-video generated videos on the two criteria. Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore on offering a better metric for text-to-video generation.