 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers
Dec 19, 2023



Recent advances in generative AI have significantly enhanced image and video editing, particularly in the context of text prompt control. State-of-the-art approaches predominantly rely on diffusion models to accomplish these tasks. However, the computational demands of diffusion-based methods are substantial, often necessitating large-scale paired datasets for training, and therefore challenging the deployment in practical applications. This study addresses this challenge by breaking down the text-based video editing process into two separate stages. In the first stage, we leverage an existing text-to-image diffusion model to simultaneously edit a few keyframes without additional fine-tuning. In the second stage, we introduce an efficient model called MaskINT, which is built on non-autoregressive masked generative transformers and specializes in frame interpolation between the keyframes, benefiting from structural guidance provided by intermediate frames. Our comprehensive set of experiments illustrates the efficacy and efficiency of MaskINT when compared to other diffusion-based methodologies. This research offers a practical solution for text-based video editing and showcases the potential of non-autoregressive masked generative transformers in this domain.
Local Relighting of Real Scenes
Jul 06, 2022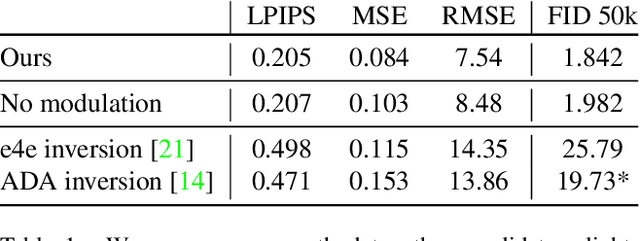

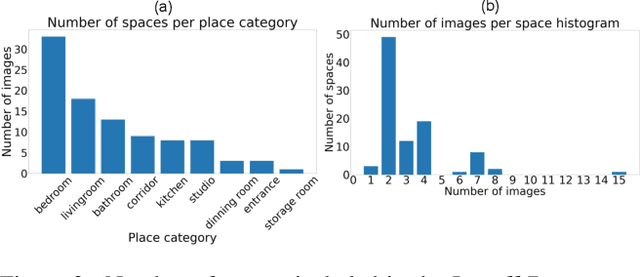
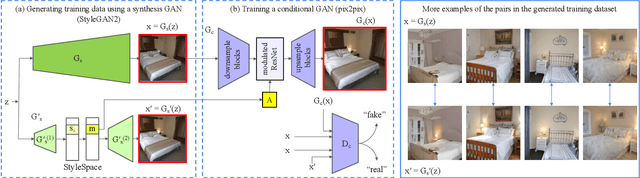
We introduce the task of local relighting, which changes a photograph of a scene by switching on and off the light sources that are visible within the image. This new task differs from the traditional image relighting problem, as it introduces the challenge of detecting light sources and inferring the pattern of light that emanates from them. We propose an approach for local relighting that trains a model without supervision of any novel image dataset by using synthetically generated image pairs from another model. Concretely, we collect paired training images from a stylespace-manipulated GAN; then we use these images to train a conditional image-to-image model. To benchmark local relighting, we introduce Lonoff, a collection of 306 precisely aligned images taken in indoor spaces with different combinations of lights switched on. We show that our method significantly outperforms baseline methods based on GAN inversion. Finally, we demonstrate extensions of our method that control different light sources separately. We invite the community to tackle this new task of local relighting.
Sparse Generative Adversarial Network
Aug 20, 2019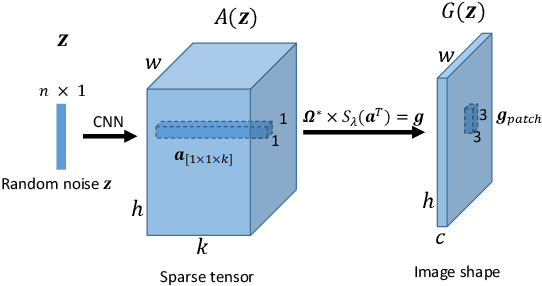
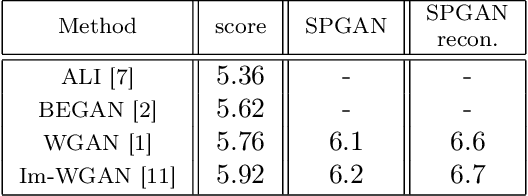
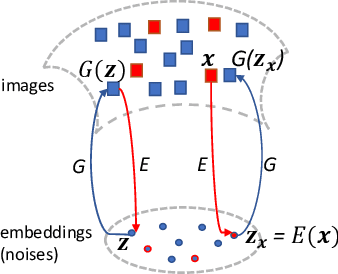
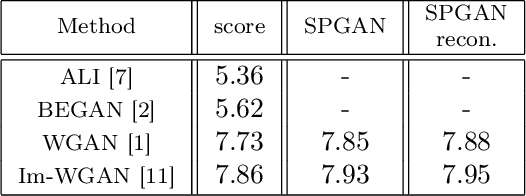
We propose a new approach to Generative Adversarial Networks (GANs) to achieve an improved performance with additional robustness to its so-called and well recognized mode collapse. We first proceed by mapping the desired data onto a frame-based space for a sparse representation to lift any limitation of small support features prior to learning the structure. To that end we start by dividing an image into multiple patches and modifying the role of the generative network from producing an entire image, at once, to creating a sparse representation vector for each image patch. We synthesize an entire image by multiplying generated sparse representations to a pre-trained dictionary and assembling the resulting patches. This approach restricts the output of the generator to a particular structure, obtained by imposing a Union of Subspaces (UoS) model to the original training data, leading to more realistic images, while maintaining a desired diversity. To further regularize GANs in generating high-quality images and to avoid the notorious mode-collapse problem, we introduce a third player in GANs, called reconstructor. This player utilizes an auto-encoding scheme to ensure that first, the input-output relation in the generator is injective and second each real image corresponds to some input noise. We present a number of experiments, where the proposed algorithm shows a remarkably higher inception score compared to the equivalent conventional GANs.
Deep Dictionary Learning: A PARametric NETwork Approach
Mar 11, 2018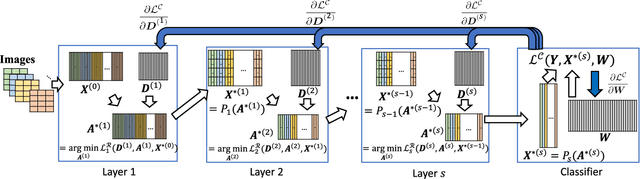
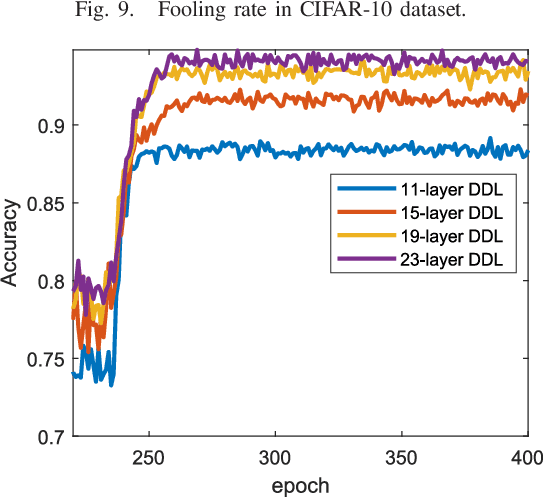
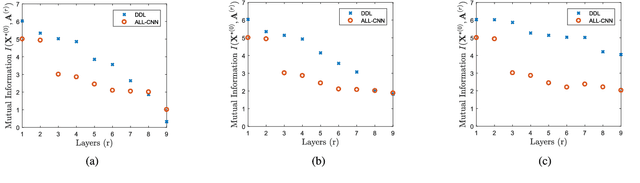
Deep dictionary learning seeks multiple dictionaries at different image scales to capture complementary coherent characteristics. We propose a method for learning a hierarchy of synthesis dictionaries with an image classification goal. The dictionaries and classification parameters are trained by a classification objective, and the sparse features are extracted by reducing a reconstruction loss in each layer. The reconstruction objectives in some sense regularize the classification problem and inject source signal information in the extracted features. The performance of the proposed hierarchical method increases by adding more layers, which consequently makes this model easier to tune and adapt. The proposed algorithm furthermore, shows remarkably lower fooling rate in presence of adversarial perturbation. The validation of the proposed approach is based on its classification performance using four benchmark datasets and is compared to a CNN of similar size.